Как опытный специалист по цифровому маркетингу с более чем двадцатилетним опытом работы, я видел свою долю обновлений и изменений политики Google. Однако недавняя волна приостановок работы в конкретных отраслях, таких как гаражные ворота, мусорные контейнеры и адвокаты по травмам, кажется необычным шагом даже для Google.
На различных форумах Google Business Profiles наблюдается приток владельцев бизнеса, выражающих обеспокоенность по поводу блокировки их профилей. Похоже, что Google может автоматически отключать некоторые бизнес-профили в определенных отраслях или специализированных секторах.
Бен Фишер недавно поделился публикацией на X, в которой заявил: «Нажата кнопка, и похоже, что фирмы, занимающиеся гаражными дверями и мусорными контейнерами, воют в отчаянии! Я только что получил предупреждение о том, что многочисленные профили в этих категориях временно деактивируются.
Бен упомянул, что его сферой деятельности являются гаражные ворота, управление отходами/мусорные контейнеры и юридические фирмы, связанные с отраслями промышленности.
Вот несколько скринов с форумов подвесок.
Электронная почта о блокировке:
Уведомление о приостановке работы в приложении Google Maps:
Вы можете просмотреть некоторые темы, чтобы увидеть, сколько жалоб есть…
Как опытный специалист по цифровому маркетингу с более чем десятилетним опытом работы с постоянно меняющимися алгоритмами Google, я могу с уверенностью сказать, что нынешнее состояние рейтинга в поиске Google напоминает поездку на американских горках без тормозной системы! Постоянная волатильность после обновления ядра в августе 2024 года была постоянной и без признаков снижения.
Честно говоря, нестабильность в поисковых рейтингах Google не ослабевала с момента запланированного на август 2024 года основного обновления. Однако вчера произошло неожиданное событие, которое, похоже, усилило колебания результатов поиска в Google. Такое ощущение, что за последний месяц или около того в поисковом рейтинге Google происходила непрерывная серия обновлений — и нет, это не самый длительный период волатильности со стороны Google, с которым мы сталкивались (хотя это может так и быть).
Чтобы уточнить, основное обновление Google за август 2024 года началось 15 августа и завершилось 3 сентября. Однако даже через день после его завершения и несколько недель спустя он оставался крайне волатильным и пока не подавал признаков стабилизации.
Примерно 6, 10 сентября и, возможно, 14 сентября мы наблюдали сильные признаки. На сегодняшний день у меня 18 сентября.
Инструменты отслеживания Google
Эти инструменты указывают на то, что волатильность в большинстве случаев остается высокой, и лишь некоторые демонстрируют некоторый уровень спокойствия. Однако даже в спокойных случаях наблюдаются пики в определенные даты. Интересно подумать о том, что может происходить в Google, и у меня такое чувство, что им тоже может быть интересно. 🙂
Показатели поисковой выдачи:
Семраш:
Расширенные веб-рейтинги:
Похожие веб-сайты:
Алгору:
Поисковая статистика:
Аккуранкер:
Мангулы:
Винчер:
Мозкаст:
Данные для SEO:
Когнитивное SEO:
SEO-болтовня
Я не решаюсь полагаться на эти инструменты прямо сейчас, поскольку в течение последнего месяца они в основном проявляли нестабильность. Однако шумиха в сообществе SEO предоставляет ценный ресурс для выявления значительных колебаний в определенные дни. Я считаю, что 18 сентября мы могли пережить еще один большой сдвиг.
Вот что я слышу от WebmasterWorld и здесь за последние 24 часа или около того.
Сегодня ОГРОМНОЕ падение…
То же самое… Сегодня ОГРОМНОЕ падение! 🙁
Мне очень жаль это писать, потому что хотелось бы, чтобы так было со всеми вами. Кажется, Google внезапно полюбил мой новостной сайт. Я уже упоминал, что у меня были очень хорошие выходные, но дело даже не только в этом. С тех пор у меня было примерно такое же большое количество читателей, как Google присылает мне каждый день (на 357% больше, чем в течение недели), в основном через Discover. Sistrix также показывает мне, что ценность видимости продолжает расти (в четыре раза с пятницы). Хотелось бы понять, откуда это вдруг взялось, но так как я ничего на сайте не менял, то не вижу смысла.
Небольшое восстановление за последние 2 дня. Количество ключевых слов на Ahrefs также изменилось и, похоже, снова растет. Слишком рано говорить о том, является ли это реальной тенденцией.
То же самое и для меня: период с послерабочего дня до настоящего момента был очень высоким трафиком. Но оно постепенно сходит на нет. Я снова наблюдаю потери в топ-3 и топ-10, а также мой трафик в США день ото дня возвращается к старому более низкому уровню. Запросы клиентов также снова замедляются. Однако трафик за пределами США по-прежнему очень высок
Вчера около полудня казалось, что пошел небольшой дождь… моя обычная интенсивность движения резко упала и оставалась низкой до конца дня. Сегодня, в 11 часов утра, трафик из США упал на 40%, что означает значительное отклонение от восходящего тренда, который наблюдался примерно с 3 сентября.
Ох… 75 % моего Googleday прошло, а за месяц уже 167 %!
У меня сегодня тоже хороший прирост трафика, но это не отражается на моем доходе… пока.
Да, сегодняшние данные. Вчерашний день был менее заметным. Однако после 16:00 все вернулось на круги своя. Такое впечатление, что фильтр то включился, то выключился…
Кто-нибудь заметил сегодня снижение показов или какие-нибудь предстоящие обновления?
Как опытный профессионал в области SEO, имеющий за плечами годы борьбы с цифровыми джунглями, я искренне поддерживаю использование инструментов аудита веб-сайтов для оптимизации ваших усилий по оптимизации. Такие инструменты, как WebSite Auditor, Screaming Frog, Lumar, Oncrawl или SE Ranking, были моими верными спутниками в навигации по лабиринту мира SEO.
Идея краулингового бюджета относится к важнейшему принципу SEO, особенно для обширных сайтов, содержащих миллионы страниц, или даже для небольших сайтов с тысячами, которые обновляются ежедневно. Все дело в управлении скоростью, с которой роботы поисковых систем могут эффективно исследовать и индексировать эти страницы.
Примером веб-сайта с миллионами страниц может служить eBay.com, а веб-сайтами с десятками тысяч страниц, которые часто обновляются, могут быть веб-сайты с обзорами пользователей и рейтингами, подобные Gamespot.com.
Из-за многочисленных обязанностей и проблем, с которыми сталкивается эксперт по SEO, сканирование сайта обычно задерживается или ему присваивается более низкий приоритет.
Но краулинговый бюджет можно и нужно оптимизировать.
В этой статье вы узнаете:
Как улучшить свой краулинговый бюджет.
Изучите изменения в краулинговом бюджете как концепции за последние пару лет.
Как специалист по SEO, я хотел бы обратить ваше внимание на проблему, которая может повлиять на ваш сайт, если на нем относительно небольшое количество страниц, но они не индексируются. Рекомендуется углубиться в общие причины проблем с индексацией, так как маловероятно, что в этом случае виноват краулинговый бюджет.
Что такое краулинговый бюджет?
Как специалист по цифровому маркетингу, я бы описал свое понимание «бюджета сканирования» следующим образом: он представляет собой объем страниц на веб-сайте, которые сканеры поисковых систем (например, пауки и боты) решают исследовать в течение определенного периода. Другими словами, речь идет о том, насколько глубоко эти сканеры углубляются в наш сайт, гарантируя, что они не пропустят важный контент, а также не перегрузят его ненужными страницами.
При настройке краулингового бюджета необходимо учитывать несколько ключевых факторов. Например, важно найти тонкий баланс: с одной стороны, Googlebot должен стремиться не перегружать ваш сервер слишком большим количеством запросов, а с другой стороны, Google хочет тщательно изучить домен вашего веб-сайта.
Повышение оптимизации бюджета сканирования означает реализацию стратегий, которые повышают скорость и частоту доступа роботов поисковых систем к страницам вашего веб-сайта, тем самым повышая их общую эффективность.
Почему важна оптимизация бюджета сканирования?
Сканирование — первый шаг к появлению в поиске. Без сканирования новые страницы и обновления страниц не будут добавляться в индексы поисковых систем.
Частое посещение сканерами ваших веб-страниц означает более быстрое добавление обновлений и нового контента в индекс поисковой системы. Это приводит к сокращению времени на то, чтобы ваши стратегии оптимизации стали эффективными и повлияли на рейтинг вашего сайта.
Индекс Google охватывает бесчисленные миллиарды веб-страниц и ежедневно расширяется. По мере увеличения количества веб-сайтов поисковые системы стремятся сократить расходы на вычисления и хранение, замедляя скорость сканирования URL-адресов и индексируя меньшее количество веб-страниц.
Кроме того, растет ощущение необходимости снизить выбросы углекислого газа ради сохранения климата, и Google стремится разработать долгосрочный план, который повысит устойчивость и сократит выбросы углекислого газа.
Итак, давайте обсудим, как вы можете оптимизировать свой краулинговый бюджет в современном мире.
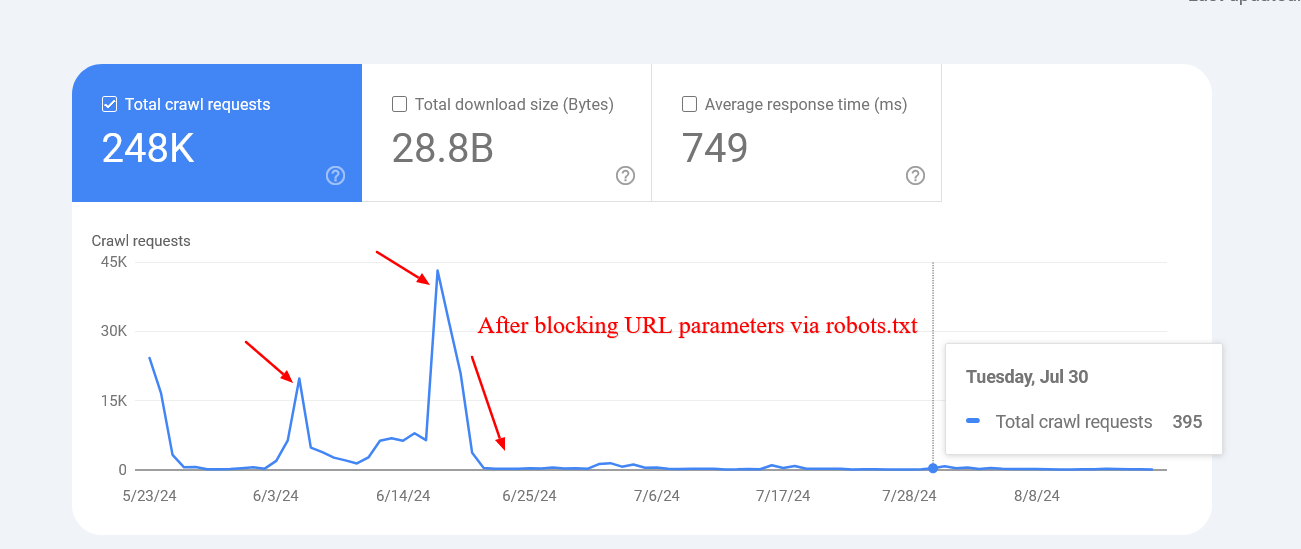
1. Запретить сканирование URL-адресов действий в robots.txt
Это может вас шокировать, но Google подтвердил, что блокировка URL-адресов не повлияет на скорость сканирования вашего сайта. Другими словами, Google продолжит сканировать ваш сайт в обычном темпе. Однако вы можете задаться вопросом, почему мы обсуждаем эту тему. Причина в том, что понимание того, как работает бюджет сканирования Google, может помочь оптимизировать ваш сайт для лучшей индексации и повышения производительности поисковых систем.
Если вы исключаете из сканирования несущественные URL-адреса, вы, по сути, даете Google указание чаще сканировать ценные разделы вашего веб-сайта.
Например, если на вашем веб-сайте есть функция внутреннего поиска с такими параметрами запроса, как /?q=google, Google будет сканировать эти URL-адреса, если на них откуда-то есть ссылки.
На веб-сайте электронной коммерции URL-адрес может выглядеть следующим образом: /filtered-products?color=red&size=small. Проще говоря, это означает, что когда вы фильтруете товары по цвету (например, красный) и размеру (например, маленький), веб-сайт генерирует уникальный URL-адрес для отображения этих конкретных товаров.
Эти параметры, обнаруженные в строках запроса, могут генерировать огромное количество различных вариантов URL-адресов, любой из которых Google может попытаться изучить.
Предоставленные URL-адреса в основном не содержат отдельного контента; вместо этого они просеивают уже имеющиеся у вас данные. Хотя это улучшает взаимодействие с пользователем, это менее полезно для сканирующего бота Google (Googlebot).
Разрешая Google доступ к этим URL-адресам, вы неоправданно расходуете свой бюджет сканирования, что может повлиять на общую возможность сканирования вашего сайта. Вместо этого, установив правила robots.txt для запрета этих URL-адресов, Google сосредоточит свои усилия на сканировании более полезных страниц вашего веб-сайта.
Вот как заблокировать внутренний поиск, фасеты или любые URL-адреса, содержащие строки запроса, через robots.txt:
Каждое правило запрещает URL-адреса с определенным параметром запроса, независимо от каких-либо дополнительных параметров, которые они могут иметь.
* (звездочка) соответствует любой последовательности символов (включая отсутствие).
? (Знак вопроса): указывает начало строки запроса.
=*: Соответствует знаку = и всем последующим символам.
Использование этого метода предотвращает повторение, гарантируя, что URL-адреса, содержащие такие разные параметры запроса, не будут индексироваться ботами поисковых систем.
Имейте в виду, что этот метод предотвращает любые URL-адреса с указанными символами, независимо от их положения. Это потенциально может непреднамеренно заблокировать URL-адреса. Например, параметры запроса, состоящие из одного символа, могут привести к блокировке всех URL-адресов, содержащих этот символ, даже если он находится в другом месте URL-адреса. Если вы хотите ограничить URL-адреса, содержащие определенный одиночный символ, вместо этого рекомендуется использовать комбинацию правил: таким образом вы можете более точно определить, какие URL-адреса следует запретить.
Disallow: *?s=*
Disallow: *&s=*
Критическое изменение заключается в том, что между символами «?» и «s» нет звездочки «*». Этот метод позволяет запретить определенные точные параметры «s» в URL-адресах, но вам придется добавлять каждый вариант индивидуально.
Включите эти рекомендации в свои отдельные сценарии, включающие URL-адреса, которые не предлагают эксклюзивный контент. Для иллюстрации: если у вас есть кнопки списка желаний, связанные с URL-адресами типа «?add_to_wishlist=1», обязательно заблокируйте такие URL-адреса с помощью этого метода:
Disallow: /*?*add_to_wishlist=*
Это простой и естественный первый и самый важный шаг, рекомендованный Google.
Предотвратив индексацию этих конкретных параметров, Google удалось уменьшить количество страниц с чрезмерно очищаемыми строками запросов. Это произошло потому, что Google сталкивался с многочисленными URL-адресами с различными значениями параметров, которые были бессмысленными, что приводило к неработающим или нерелевантным страницам.
Иногда поисковые системы все еще могут сканировать и перечислять URL-адреса, которые предположительно запрещены. Хотя это может показаться необычным, обычно это не повод для беспокойства. Это часто происходит, когда другие сайты ссылаются на эти конкретные URL-адреса.
Google подтвердил, что в этих случаях активность сканирования со временем снизится.
Избегайте применения «мета-тегов noindex» в целях блокировки, поскольку роботу Googlebot необходимо сделать запрос на проверку тега, что может неоправданно расходовать ваш краулинговый бюджет, поскольку требует выполнения запросов, даже если контент не предназначен для индексации.
1.2. Запретить URL-адреса неважных ресурсов в файле Robots.txt
Как специалист по цифровому маркетингу, я бы посоветовал вам рассмотреть возможность запрета файлов JavaScript, которые не влияют на дизайн или функциональность сайта. Эти дополнительные сценарии могут представлять потенциальную угрозу безопасности и непреднамеренно повлиять на производительность вашего сайта.
Если ваши файлы JavaScript выполняют задачу отображения изображений во всплывающем окне при клике пользователя, рассмотрите возможность их блокировки в файле robots.txt, чтобы поисковые системы, такие как Google, не тратили ресурсы на ненужное сканирование.
Вот пример правила запрета файла JavaScript:
Запретить: /assets/js/popup.js
Например, конечные точки REST API используются для обработки отправки форм. Предположим, у вас есть форма с URL-адресом действия «/api/form-submissions». Это пример того, как данные из отправленных форм могут быть отправлены на сервер с использованием этой структуры.
Вполне возможно, что эти URL-адреса могут быть проиндексированы Google. Поскольку они не имеют никакого отношения к аспекту отображения, было бы разумно запретить к ним доступ.
Запретить: /rest-api/form-submissions/
Поскольку многие безголовые CMS полагаются на REST API для динамической доставки контента, крайне важно обеспечить доступность этих конечных точек API.
Короче говоря, посмотрите на все, что не связано с рендерингом, и заблокируйте их.
2. Следите за цепочками перенаправления
Как опытный веб-мастер, я не могу не подчеркнуть важность понимания и устранения цепочек перенаправления. Видите ли, когда один URL-адрес указывает на другой URL-адрес, который затем снова перенаправляется (и так далее), вы получаете цепочку перенаправлений. Если этот процесс продолжится в течение некоторого времени, сканеры поисковых систем могут решить сократить свои потери и сразу перейти к конечному пункту назначения, потенциально пропуская по пути важный контент. Это может негативно повлиять на эффективность SEO вашего сайта. Всегда лучше оптимизировать перенаправление URL-адресов для более удобной работы в Интернете.
Как опытный веб-мастер, я хотел бы поделиться обычным явлением в мире URL-адресов: иногда один URL-адрес (URL 1) ведет к другому (URL 2), который затем ведет к третьему (URL 3), и так вперед. Эту серию редиректов часто называют цепочкой. Однако важно отметить, что эти цепочки также могут образовывать бесконечные циклы, когда один URL-адрес перенаправляется обратно на другой, создавая циклический шаблон.
Избегать этого — разумный подход к здоровью веб-сайта.
В идеале вы могли бы избежать наличия хотя бы одной цепочки перенаправлений на всем вашем домене.
Однако выполнение такой задачи на огромном сайте может оказаться сложной задачей из-за вероятности возникновения как 301, так и 302 редиректов. К сожалению, вы не можете исправить перенаправления, возникающие из входящих обратных ссылок, поскольку у вас нет контроля над иностранными веб-сайтами.
Хотя случайное отклонение не вызовет особых проблем, расширенные пути и круговые узоры могут привести к проблемам.
Чтобы исследовать и решить проблемы с цепочками перенаправлений, вы можете рассмотреть возможность использования популярных инструментов SEO, таких как Screaming Frog, Lumar или Oncrawl. Эти инструменты помогут вам легче идентифицировать и найти цепи.
Оптимальный подход для исправления цепочки (ссылки) — исключить все URL-адреса, соединяющие начальную страницу с последней. Например, если ваша цепочка охватывает семь страниц, лучше всего перенаправить самый первый URL-адрес прямо на седьмую страницу.
Удобный метод минимизации цепочек перенаправлений — обновление внутренних ссылок в вашей системе управления контентом (CMS), которые в данный момент перенаправляются, с указанием их конечных пунктов назначения.
В зависимости от используемой вами системы управления контентом (CMS) могут применяться различные подходы; например, вы можете использовать определенный плагин при работе с WordPress. Если вы используете отдельную CMS, вам может потребоваться индивидуальное решение или проконсультироваться со своей командой разработчиков, чтобы помочь вам.
3. Используйте рендеринг на стороне сервера (HTML), когда это возможно.
В настоящее время, когда дело доходит до операций Google, их сканер использует самую последнюю версию Chrome, гарантируя, что он может легко воспринимать контент, созданный с помощью JavaScript, без каких-либо проблем.
Для Google крайне важно свести к минимуму затраты, связанные с вычислениями, стремясь по возможности находить наиболее эффективные решения.
Зачем выбирать JavaScript для генерации контента на стороне клиента, тем самым потенциально увеличивая вычислительную нагрузку для Google при сканировании ваших веб-страниц?
По этой причине, когда это возможно, вам следует придерживаться HTML.
Таким образом, вы не ухудшите свои шансы при использовании любого сканера.
4. Улучшите скорость страницы
Гугл говорит:
Возможность Google исследовать ваш веб-сайт ограничена такими факторами, как пропускная способность, время и количество доступных экземпляров робота Googlebot. Обеспечивая более быструю реакцию вашего сервера, вы можете помочь нам более эффективно получать доступ к большему количеству страниц вашего сайта.
Использование рендеринга на стороне сервера действительно полезно для повышения скорости страницы, однако крайне важно оптимизировать основные показатели Web Vital, особенно время ответа сервера, чтобы обеспечить бесперебойную работу пользователей.
5. Позаботьтесь о своих внутренних ссылках
Когда Google проверяет веб-страницу, он сканирует URL-адреса, отображаемые на этой странице. Важно отметить, что каждый отдельный URL-адрес рассматривается сканером как уникальная страница.
Чтобы обеспечить единообразие на вашем веб-сайте, направьте все внутренние ссылки, особенно в навигации, на вариант URL-адреса вашего сайта «www». Аналогичным образом убедитесь, что неканонические версии (без «www») также ссылаются на версию «www», чтобы избежать дублирования и потенциальных проблем с SEO.
Частой ошибкой, которую следует избегать, является забывание включить в URL закрывающую косую черту. Убедитесь, что все используемые вами внутренние ссылки также содержат косую черту, если ваши URL-адреса заканчиваются ею.
Если веб-сайт без необходимости перенаправляется с «https://www.example.com/sample-page» на «https://www.example.com/sample-page/», это вызовет два отдельных сканирования для каждого URL-адреса, что приведет к к увеличению рабочей нагрузки и неэффективности процесса сканирования веб-страниц.
Крайне важно убедиться, что на страницах с внутренними ссылками нет разрывов, поскольку они могут потреблять ваш бюджет сканирования и создавать мягкие страницы 404 (не найдено). Проще говоря, важно убедиться, что все ссылки на вашем веб-сайте ведут на работающие страницы, чтобы не тратить впустую выделенное для сканирования веб-страницы или не отображать страницы с ошибками, когда связанная страница не может быть найдена.
И если этого было недостаточно, они еще и навредили вашему пользовательскому опыту!
В данном случае я опять же за использование инструмента для аудита сайта.
Эти инструменты — Website Auditor, Screaming Frog, Lumar, Oncrawl и SE Ranking — являются отличными вариантами для проведения тщательного анализа веб-сайта.
6. Обновите карту сайта
Опять же, позаботиться о вашей XML-карте сайта — это действительно беспроигрышный вариант.
Ботам будет намного лучше и легче понять, куда ведут внутренние ссылки.
Используйте только те URL-адреса, которые являются каноническими для вашей карты сайта.
Также убедитесь, что он соответствует последней загруженной версии robots.txt и загружается быстро.
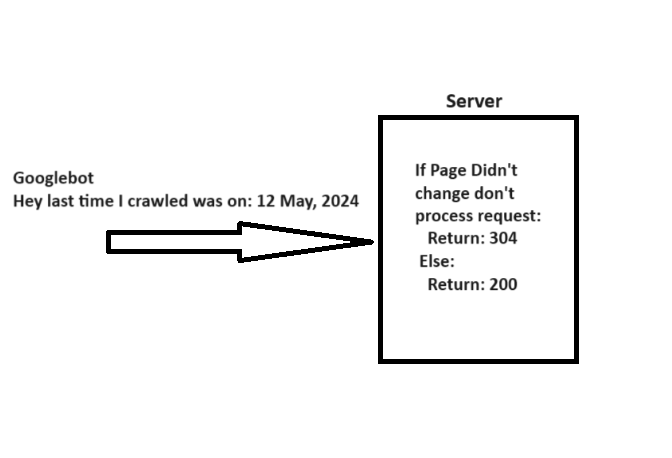
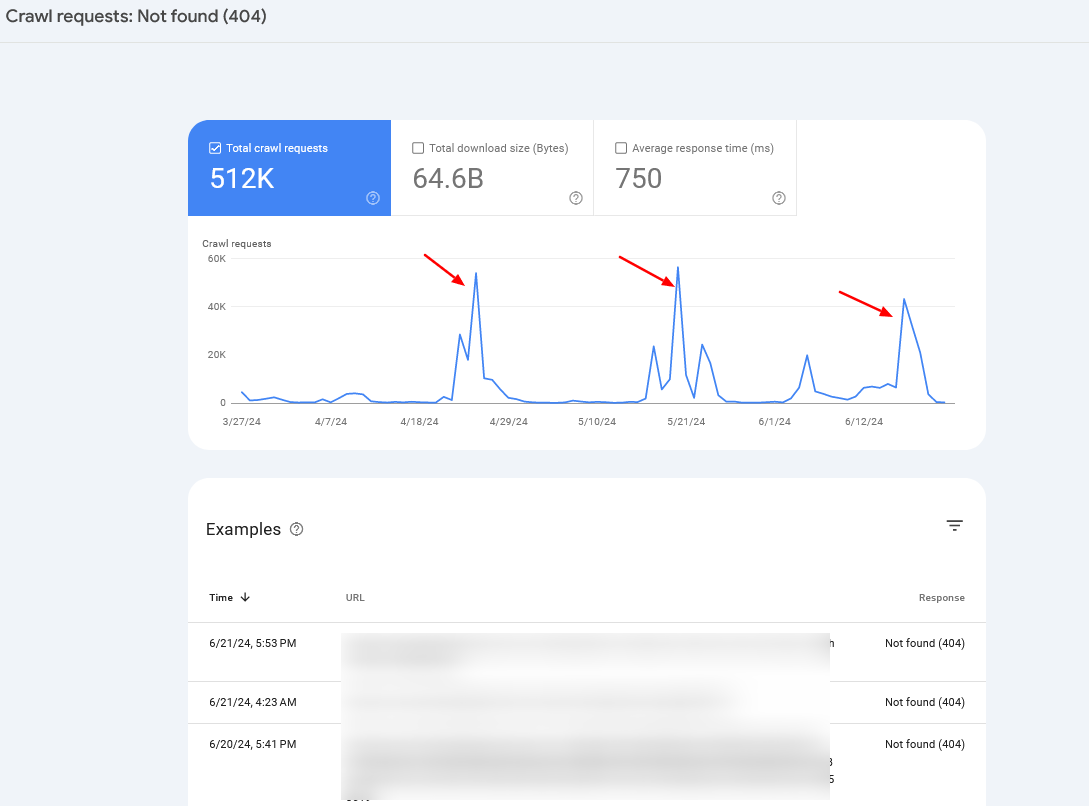
7. Внедрите код состояния 304.
Когда робот Googlebot обращается к URL-адресу, он включает заголовок «If-Modified-Since» с датой предыдущего посещения этого конкретного URL-адреса, предоставляя дополнительную информацию о том, когда он в последний раз проверял эту конкретную ссылку.
Если информация на вашей веб-странице остается неизменной с даты, указанной в «If-Modified-Since», вы можете передать сообщение о состоянии «304 Not Modified», не отправляя никакого тела ответа. Этот сигнал указывает поисковым системам, что содержимое страницы не было обновлено, что позволяет роботу Googlebot использовать ранее сохраненную версию файла при следующем посещении.
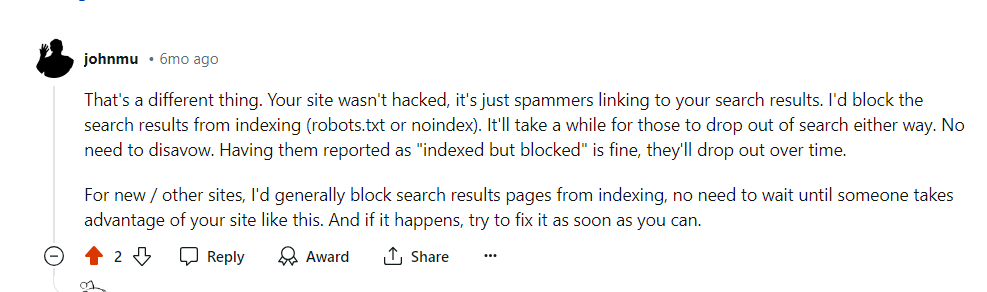
Однако при реализации кода состояния 304 есть предостережение, на которое указал Гэри Иллис.
соблюдайте осторожность. Пустые страницы, возвращаемые серверами со статусом 200 во время ошибок сервера, могут помешать сканерам выполнить повторное сканирование, что со временем приведет к постоянным проблемам с индексацией.
8. Теги Hreflang жизненно важны
Чтобы проанализировать различные языковые версии ваших веб-страниц, сканеры используют теги hreflang. Очень важно четко информировать Google о различных локализованных версиях ваших страниц.
Сначала поместите следующий HTML-код в заголовок вашей веб-страницы:
При указании URL-адреса рекомендуется использовать тег «». Это позволяет вам переходить на разные локализованные варианты одной и той же веб-страницы.
9. Мониторинг и обслуживание
Следите за журналами своего сервера и отчетом о статистике сканирования в консоли поиска Google, чтобы обнаружить любые необычные действия при сканировании и выявить потенциальные проблемы.
Если вы наблюдаете регулярное увеличение количества сканирований страниц 404, в большинстве случаев это может быть связано с проблемой, известной как бесконечное пространство для сканирования (тема, которую мы уже рассматривали ранее), или это может сигнализировать о других потенциальных проблемах, с которыми может столкнуться ваш веб-сайт.
Иногда может быть полезно объединить данные журнала сервера со статистикой Search Console, чтобы точно определить основную проблему.
Краткое содержание
Действительно, если вы размышляли над актуальностью оптимизации краулингового бюджета для вашего сайта, ответ, несомненно, будет утвердительным.
Концепция краулингового бюджета всегда должна быть ключевым фактором для каждого специалиста по SEO, как это было в прошлом и, вероятно, останется таковым в будущем.
Вполне вероятно, что эти предложения помогут вам увеличить бюджет сканирования и повысить эффективность SEO. Однако имейте в виду, что тот факт, что страницы сканируются, не означает, что они автоматически будут проиндексированы.
Как опытный веб-разработчик с многолетним опытом работы за плечами, я имел удовольствие работать как с рендерингом на стороне сервера (SSR), так и с рендерингом на стороне клиента (CSR). Каждый из них имеет свои уникальные преимущества и недостатки, и выбор между ними во многом зависит от характера вашего проекта.
Улучшенная скорость загрузки веб-страниц существенно влияет на удобство работы пользователей и поисковую оптимизацию (SEO). Скорость загрузки страницы — важнейший компонент, который учитывает алгоритм Google.
Веб-дизайнер, работающий над пользовательскими интерфейсами, должен выбрать оптимальный метод отображения сайта, обеспечивающий быстрое взаимодействие и обновление контента в режиме реального времени.
Два популярных метода рендеринга включают рендеринг на стороне клиента (CSR) и рендеринг на стороне сервера (SSR).
Понимание разницы между рендерингом на стороне клиента и на стороне сервера полезно, поскольку каждый веб-сайт имеет уникальные потребности, что позволяет вам оптимизировать представление вашего сайта в соответствии с вашими бизнес-целями.
Google и JavaScript
Google предоставляет исчерпывающие ресурсы, подробно описывающие работу с JavaScript, при этом сотрудники Google часто делятся своими знаниями и отвечают на запросы, связанные с JavaScript, в различных средах, охватывая как формальные, так и неформальные каналы.
В подкасте Search Off The Record они рассказали о том, как Google обрабатывает рендеринг страниц для результатов поиска, даже со значительным количеством JavaScript.
Эта тема вызвала обширное обсуждение в LinkedIn, и вот две дополнительные идеи, почерпнутые из подкаста, а также из последующих разговоров:
Google не отслеживает, насколько дорого обходится рендеринг определенных страниц.
Google отображает все страницы для просмотра контента — независимо от того, использует он JavaScript или нет.
Полный комментарий Мартина Сплитта на LinkedIn по этому поводу был следующим:
Мы не отслеживаем стоимость отдельных страниц для нас. Многие части Интернета используют JavaScript для динамического добавления, удаления или изменения контента на страницах. В результате мы просто отображаем или «рендерингуем» страницу для просмотра всего ее содержимого. Независимо от того, использует ли страница JavaScript или нет, это не оказывает существенного влияния на нашу способность видеть весь контент, поскольку мы можем гарантировать полное представление только после отображения страницы.
Мартин также проверил наличие очереди и возможную задержку между парсингом и листингом, но это связано не только с тем, используется ли что-то JavaScript или нет. Также важно отметить, что проблема неиндексации URL-адресов не является загадочной, поскольку основной причиной является наличие JavaScript.
Общие рекомендации по JavaScript
Давайте удостоверимся, что мы придерживаемся общих лучших практик как для клиентских, так и для серверных методов, углубляясь в обсуждение их достоинств: это обеспечит бесперебойную работу.
Избегайте блокировки рендеринга.
Избегайте внедрения JavaScript в DOM.
Что такое рендеринг на стороне клиента и как он работает?
Рендеринг на стороне клиента — относительно новый подход к рендерингу веб-сайтов.
Его использование получило широкое распространение, когда библиотеки JavaScript начали его включать, причем Angular и React.js служат заслуживающими внимания примерами таких библиотек, используемых в этой конкретной технике рендеринга.
Он работает путем рендеринга JavaScript веб-сайта в вашем браузере, а не на сервере.
Вместо получения всего содержимого из полностью сформированного HTML-документа сервер предоставляет минимальный HTML-файл, который включает только необходимые файлы JavaScript.
Хотя первоначальная загрузка занимает некоторое время, последующие страницы будут загружаться быстро, поскольку для каждого маршрута не требуется новая HTML-страница.
Вместо независимой обработки логики и получения данных из API, веб-сайты, отображаемые на стороне клиента, выполняют все задачи автономно. Страница становится доступной после выполнения кода, поскольку каждая страница, которую посещает пользователь, и связанный с ней URL-адрес динамически генерируются на месте.
Процесс КСО выглядит следующим образом:
Пользователь вводит URL-адрес, который хочет посетить, в адресную строку.
Запрос данных отправляется на сервер по указанному URL-адресу.
При первом запросе клиента на сайт сервер доставляет статические файлы (CSS и HTML) в браузер клиента.
Клиентский браузер сначала загружает содержимое HTML, а затем JavaScript. Эти HTML-файлы подключают JavaScript, запуская процесс загрузки, отображая символы загрузки, определенные разработчиком пользователю. На этом этапе веб-сайт по-прежнему не виден пользователю.
После загрузки JavaScript контент динамически генерируется в браузере клиента.
Веб-контент становится видимым, когда клиент перемещается по веб-сайту и взаимодействует с ним.
Что такое серверный рендеринг и как он работает?
Рендеринг на стороне сервера — более распространенный метод отображения информации на экране.
Проще говоря, когда вы запрашиваете у своего веб-браузера конкретную информацию (например, нажимаете на ссылку), он отправляет запрос на сервер. Затем сервер собирает для вас персонализированные данные и создает полную веб-страницу HTML. Готовая страница затем возвращается на ваше устройство, где она отображается как веб-страница, которую вы видите.
Каждый раз, когда пользователь посещает новую страницу сайта, сервер повторяет весь процесс.
Вот как поэтапно происходит процесс SSR:
Пользователь вводит URL-адрес, который хочет посетить, в адресную строку.
Сервер передает браузеру готовый к отображению HTML-ответ.
Браузер отображает страницу (теперь она доступна для просмотра) и загружает JavaScript.
Браузер выполняет React, что делает страницу интерактивной.
Каковы различия между рендерингом на стороне клиента и на стороне сервера?
Основное различие между этими двумя подходами рендеринга заключается в алгоритмах их работы. CSR показывает пустую страницу перед загрузкой, а SSR отображает полностью визуализированную HTML-страницу при первой загрузке.
Рендеринг на стороне сервера имеет преимущество в скорости по сравнению с рендерингом на стороне клиента, поскольку устраняет необходимость в браузере обрабатывать обширные файлы JavaScript. В результате контент обычно становится видимым всего за несколько миллисекунд.
Поисковые системы могут сканировать ваш веб-сайт, чтобы улучшить его SEO, гарантируя, что ваши веб-страницы легко будут включены в результаты поиска. По сути, именно так веб-сайты статического рендеринга сайта (SSR) отображаются в браузере.
Однако рендеринг на стороне клиента — более дешевый вариант для владельцев веб-сайтов.
Такой подход снижает нагрузку на ваши серверы, поскольку делегирует задачу отображения контента клиенту (будь то бот или пользователь, стремящийся получить доступ к вашей веб-странице). Кроме того, он обеспечивает быстрое и увлекательное взаимодействие с веб-сайтом после начальной загрузки, улучшая взаимодействие с пользователем, предлагая богатые возможности взаимодействия с сайтом.
По сравнению с рендерингом на стороне сервера (SSR), рендеринг на стороне клиента (CSR) выполняет меньше обращений к серверу, поскольку вместо рендеринга каждой страницы заново, как в SSR, CSR обновляет только части страницы при возникновении переходов, производя переключение. между страницами быстрее.
Если сервер завален многочисленными одновременными запросами пользователей, ему может быть сложно сохранить свою структуру, подобно тому, как SSR (твердотельное реле) может погнуться или сломаться под чрезмерным давлением.
Недостатком CSR является более длительное время начальной загрузки. Это может повлиять на SEO; сканеры могут не дождаться загрузки контента и покинуть сайт.
Как опытный веб-мастер, я хотел бы подчеркнуть потенциальную проблему двухэтапного подхода: это может привести к отображению пустого содержимого на вашей странице из-за отсутствия содержимого JavaScript после первоначального сканирования и индексации HTML. Имейте в виду, что для правильного функционирования клиентского рендеринга (CSR) обычно требуется внешняя библиотека.
Когда использовать рендеринг на стороне сервера
Если вы хотите улучшить свою видимость в Google и занять высокие позиции на страницах результатов поисковых систем (SERP), рендеринг на стороне сервера — это выбор номер один.
Веб-сайты, цифровые торговые площадки и приложения с простым дизайном, в которых меньше страниц, опций и обновлений данных в реальном времени, как правило, работают лучше благодаря своей оптимизированной структуре.
Когда использовать рендеринг на стороне клиента
Проще говоря, рендеринг на стороне клиента часто используется на динамических веб-сайтах, таких как платформы социальных сетей или чат-приложения. Причина этого в том, что контент на этих сайтах часто обновляется, и им необходимо быстро обрабатывать огромные объемы изменяющихся данных, чтобы соответствовать ожиданиям пользователей в отношении высокой производительности.
Основное внимание здесь уделяется богатому сайту с большим количеством пользователей, при этом пользовательский опыт отдается приоритету над SEO.
Что лучше: рендеринг на стороне сервера или на стороне клиента?
Чтобы принять обоснованное решение о наиболее подходящем методе, важно учитывать как ваши требования к SEO, так и пользовательский опыт, а также ценность, которую предоставляет веб-сайт.
Рассмотрите текущий проект и подумайте, как выбранная вами презентация может повлиять на ваш рейтинг в поисковых системах (SERP) и общий пользовательский опыт вашего веб-сайта.
Как правило, CSR лучше подходит для динамических веб-сайтов, а SSR лучше всего подходит для статических веб-сайтов.
Частота обновления контента
Для сайтов, предлагающих быстро меняющиеся данные, таких как платформы азартных игр или Форекс, зачастую более эффективно реализовать клиентский рендеринг (CSR), а не серверный рендеринг (SSR), поскольку эти сайты часто обновляют свой контент каждую секунду. Однако выбор между CSR и SSR может зависеть от вашей стратегии привлечения пользователей; вы можете выбрать CSR только на определенных целевых страницах, а не применять его по всему сайту.
Повышение скорости сайта (SSR) работает лучше всего, когда контент вашего веб-сайта не требует активного взаимодействия с пользователем. Это повышает доступность, сокращает время загрузки страниц, улучшает поисковую оптимизацию (SEO) и усиливает интеграцию с социальными сетями.
Вместо этого позвольте мне сказать следующее: по сравнению с другими методами рендеринг контент-сервисов (CSR) предлагает доступное решение для визуализации веб-приложений. Его также проще создавать и управлять. Кроме того, он превосходно улучшает задержку первого входа (FID).
Можно сказать так: ключевой аспект CSR (корпоративной социальной ответственности) включает в себя обеспечение того, чтобы метатеги (заголовок, описание), канонические URL-адреса и теги Hreflang предоставлялись сервером в начале ответа HTML для сканеров поисковых систем. чтобы оперативно их обнаружить. Это не идеально, если они появляются только в окончательном HTML-коде.
Особенности платформы
Как специалист по цифровому маркетингу, я часто обнаруживаю, что поддержка технологии CSR (клиентский рендеринг) обходится дороже. Это связано с тем, что почасовые ставки для разработчиков, владеющих продвинутыми языками, такими как React.js или Node.js, как правило, значительно выше, чем у их коллег, специализирующихся на более традиционных платформах, таких как PHP или WordPress.
Кроме того, вы найдете меньший выбор готовых плагинов или готовых решений, разработанных для рамок правил безопасности контента (CSR), в отличие от обширного разнообразия плагинов, которые могут использовать пользователи WordPress.
Если вы обдумываете автономную конфигурацию WordPress, такую как Frontity, помните, что для беспрепятственной настройки вам потребуются услуги не только разработчиков React.js, но и разработчиков PHP.
Эта настройка работает благодаря тому, что WordPress без управления использует React.js в пользовательском интерфейсе, хотя он продолжает зависеть от PHP для своих серверных операций.
Как специалист по цифровому маркетингу, я всегда имею в виду, что не каждый плагин WordPress работает без проблем с безголовыми конфигурациями. Это может ограничить функциональность или потребовать дополнительных обходных решений в области кодирования.
Функциональность и назначение веб-сайта
Иногда нет необходимости выбирать только один подход, поскольку существуют смешанные варианты. Фактически, элементы как социальной ответственности (CSR), так и отзывчивости поисковых систем (SSR) могут быть включены в один и тот же сайт или страницу в Интернете.
Как специалист по цифровому маркетингу, я всегда гарантирую, что страницы описания моих продуктов на нашем онлайн-рынке динамически генерируются на стороне сервера. Это связано с тем, что эти страницы содержат статический контент, который необходимо быстро и легко сканировать и индексировать поисковыми системами, чтобы повысить нашу видимость и привлечь больше потенциальных клиентов.
В сфере электронной коммерции, если ваш сайт предлагает пользователям значительную персонализацию на нескольких страницах, может возникнуть проблема с созданием контента, отображаемого на стороне сервера (SSR), который смогут понять боты. В результате вам потребуется создать некоторый стандартный резервный контент специально для робота Googlebot, который работает без файлов cookie и без сохранения состояния.
Поскольку страницы учетных записей пользователей обычно не имеют отношения к результатам поисковых систем, вместо этого стратегия релевантности контента (CRS) может предложить более удобный интерфейс.
Приступая к ранним этапам разработки продукта, вы столкнетесь с двумя широко используемыми методами рендеринга веб-сайтов: рендеринг на стороне клиента (CSR) и рендеринг на стороне сервера (SSR). Крайне важно сделать выбор между этими методами, исходя из требований вашего проекта.
Как опытный эксперт по SEO с более чем десятилетним опытом работы за плечами, я видел много изменений в алгоритмах и документации Google. Однако недавнее обновление документации Google Crawler — это то, что бросается в глаза не только потому, что это значительное изменение, но и потому, что оно решает общую проблему, с которой мы, специалисты по SEO, часто сталкиваемся — слишком много информации на одной странице может сделать ее перегруженной. и менее полезны для пользователей, которые ищут конкретные детали.
Google значительно обновил свое руководство по поисковому роботу, уменьшив размер основной вводной страницы и разделив контент на три новые специализированные страницы. Хотя журнал изменений предполагает незначительные изменения, был добавлен новый раздел, а главная страница обзора сканера существенно была переписана. Новые страницы предоставляют более целенаправленную информацию и расширяют общий охват тем, связанных с поисковым роботом Google.
Что изменилось?
В журнале изменений документации Google отмечены два изменения, но на самом деле их намного больше.
Добавлена обновленная строка пользовательского агента для сканера GoogleProducer.
Добавлена информация о кодировке контента.
Добавлен новый раздел о технических свойствах.
В этом разделе технических характеристик вы найдете совершенно новые детали, которых раньше не было. В поведение сканера не было внесено никаких изменений; однако, создав три тематические страницы, Google может расширить информацию на странице сводки сканера, не увеличивая ее размер.
Сканеры и сборщики Google могут обрабатывать несколько типов сжатия контента для эффективной передачи данных: gzip, deflate и Brotli (с аббревиатурой br). Каждый пользовательский агент Google указывает поддерживаемые кодировки в заголовке Accept-Encoding, который является частью каждого отправляемого запроса. Например, типичный заголовок может выглядеть так: «Accept-Encoding: gzip, deflate, br».
Помимо подробного описания сканирования с помощью HTTP/1.1 и HTTP/2, важно также отметить, что эти методы направлены на просмотр как можно большего количества веб-страниц, минимизируя при этом любую нагрузку на хост-сервер.
Какова цель реконструкции?
Изменение документации было необходимо, поскольку главная страница значительно расширилась. Добавление дополнительных деталей сканера только сделает его больше. Чтобы разместить более конкретный контент сканера и обеспечить больший объем общей информации на странице обзора, было решено разделить страницу на три отдельных раздела или подтемы. Выделение этих тем на отдельные страницы — это инновационный подход к обеспечению удобства обслуживания.
Из-за большого объема документации нам стало сложно добавлять более подробную информацию о наших сканерах и сборщиках, инициируемых пользователями, поскольку это ограничивало наши возможности по расширению.
Мы упростили документацию Google, включая рекомендации для их веб-сканеров и сборщиков, которые активируются пользователями. Мы также включили четкие метки, указывающие, на какой продукт влияет каждый сканер, и добавили примеры фрагментов robots.txt для каждого сканера, чтобы помочь с использованием токенов пользовательского агента. Основная часть контента осталась без изменений.
В журнале изменений изменения преуменьшаются, описывая их как реорганизацию, поскольку обзор сканера существенно переписан, а также созданы три совершенно новые страницы.
Как эксперт по SEO, я недавно усовершенствовал свой подход, разбив более крупные темы на подразделы. Таким образом, Google может легко индексировать и воспринимать каждую часть как уникальный фрагмент контента, а не просто расширять исходную страницу. Например, обзор, ранее озаглавленный «Сканеры и сборщики Google (пользовательские агенты)», был разделен на более специализированные страницы, обеспечивающие более четкое и полное понимание каждого аспекта.
Общие сканеры
Гусеницы для особых случаев
Сборщики данных, запускаемые пользователем
1. Обычные краулеры
Судя по заголовку, это часто встречающиеся веб-сканеры; некоторые из них связаны с GoogleBot, например Google-InspectionTool, который работает под именем пользователя GoogleBot. Каждый бот, которого вы видите здесь, следует рекомендациям, установленным в файле robots.txt.
Googlebot
Изображение робота Googlebot
Видео робота Google
Новости Googlebot
Google StoreBot
Google-InspectionTool
GoogleДругое
GoogleOther-Image
GoogleДругое-Видео
Google-CloudVertexBot
Google-расширенный
3. Краулеры для особых случаев
Здесь мы обсуждаем ботов, привязанных к конкретным продуктам. Они получают доступ к этим продуктам на основе пользовательских соглашений и работают с уникальных IP-адресов, отличных от тех, которые используются сканерами GoogleBot.
Список сканеров для особых случаев:
AdSense
Пользовательский агент для файла Robots.txt: Mediapartners-Google
AdsBot
Пользовательский агент для Robots.txt: AdsBot-Google
AdsBot для мобильных устройств
Пользовательский агент для файла Robots.txt: AdsBot-Google-Mobile
API-Google
Пользовательский агент для файла Robots.txt: API-Google
Безопасность Google
Пользовательский агент для файла Robots.txt: Google-безопасность
3. Сборщики данных, запускаемые пользователем
На странице «Сборщики, запускаемые пользователем» описаны боты, которые активируются по запросу пользователя, что объясняется следующим образом:
Сборщики данных, инициируемые пользователем, активируются пользователями с целью сбора данных в службе Google. Например, Google Site Verifier реагирует на команды пользователя, или сайт на Google Cloud Platform (GCP) позволяет своим пользователям получать внешний RSS-канал. Поскольку эти действия инициируются пользователями, эти сборщики обычно игнорируют правила, указанные в файлах robots.txt. Основные технические характеристики веб-сканеров Google также распространяются на сборщики данных, инициированные пользователем.
Сборщик данных
Центр издателей Google
Google Читать вслух
Google Проверка сайта
Еда на вынос:
Страница сводки поискового робота Google могла оказаться слишком подробной и, следовательно, менее практичной, поскольку не всем нужна такая подробная страница; вместо этого они обычно ищут конкретную информацию. Теперь страница предлагает более четкую перспективу в качестве точки входа, позволяя пользователям более подробно изучать более конкретные подтемы, связанные с тремя типами сканеров.
Пересмотр этого подхода может дать ценные предложения о том, как оживить страницу, которая может работать неэффективно из-за чрезмерной детализации. Разделив обширную страницу на отдельные, автономные страницы, каждая тема может удовлетворить различные потребности пользователей, что потенциально повышает их полезность и увеличивает шансы на более высокий рейтинг в результатах поиска.
Мне кажется, что это изменение не является отражением какой-либо корректировки алгоритма Google; скорее, это, по-видимому, улучшение их документации для улучшения пользовательского опыта, что потенциально открывает путь для добавления дополнительной информации.
Прочтите новую документацию Google
Обзор сканеров и сборщиков Google (пользовательских агентов)
Список распространенных сканеров Google
Список сканеров Google для особых случаев
Список сборщиков Google, запускаемых пользователем