

Как опытный цифровой маркетолог с более чем десятилетним опытом работы за плечами, я должен сказать, что идеи, представленные в этом всестороннем анализе, являются не чем иным, как откровением. То, как структурированные данные формируют будущее взаимодействия поиска и искусственного интеллекта, поистине увлекательно.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)В 2024 году произошли существенные изменения в структуре структурированных данных, в первую очередь под влиянием резкого роста использования искусственного интеллекта (ИИ) в функциях поиска, растущей актуальности контента, который может быть прочитан машинами, а также необходимости привязывать обширные языковые модели к фактическим данным. .
Основываясь на последних результатах веб-альманаха HTTP Archive, исследование структурированных данных примерно на 16,9 миллионах сайтов указывает на явный переход от традиционных стратегий SEO к созданию расширенных графов знаний, которые подпитывают системы обнаружения, управляемые искусственным интеллектом.
В 2023 году Google прекратил поддержку некоторых расширенных результатов, таких как часто задаваемые вопросы и инструкции, но в то же время представил исключительное разнообразие новых типов структурированных данных, которые теперь включают списки автомобилей, информацию о курсах, аренду на время отпуска, страницы профиля и 3D модели изделий.
В феврале 2024 года компания расширила свою поддержку по вариантам продуктов и GS1 Digital Link, после чего в марте последовал бета-выпуск организованных каруселей данных.
Как человек, проработавший много лет в технологической отрасли, я могу с уверенностью сказать, что быстрая эволюция, которую мы наблюдаем в нашей экосистеме данных, действительно поразительна. Речь идет уже не только об улучшении результатов поиска; речь идет о создании прочной основы для реальных ответов ИИ, обучения языковых моделей и создания расширенного цифрового опыта.
Анализ и методология
Информация, представленная в этой статье, взята из раздела «Структурированные данные» веб-альманаха HTTP Archive за 2024 год. В этом годовом отчете рассматривается текущее состояние Интернета путем оценки использования структурированных данных примерно на 16,9 миллионах веб-сайтов. Доступ к этим наборам данных можно получить публично через BigQuery в таблицах под `httparchive.all.*` на дату `date = ‘2024-06-01’`. В отчете используются такие инструменты, как WebPageTest, Lighthouse и Wappalyzer, для сбора показателей форматов структурированных данных, уровня внедрения и производительности.
Тенденции внедрения структурированных данных
Анализ показывает убедительный рост основных форматов структурированных данных:
- JSON-LD достиг 41% внедрения (+7% в годовом сопоставлении).
- РДФа сохраняет лидерство с присутствием 66% (+3% г/г).
- Внедрение Open Graph выросло до 64% (+5% г/г).
- Использование метатегов X (Twitter) увеличивается до 45 % (+8 % в годовом сопоставлении).
Широкое использование подразумевает, что компании не только вкладывают деньги в структурированные данные для улучшения рейтинга в поисковых системах, но и для того, чтобы помочь ИИ и веб-сканерам понять и улучшить свои цифровые взаимодействия.
Графики открытий и знаний искусственного интеллекта
Отношения между структурированными данными и системами искусственного интеллекта развиваются сложным образом.
Хотя несколько многообещающих поисковых систем с генеративным искусственным интеллектом совершенствуют свои методы для использования структурированных данных, устоявшиеся системы, такие как Bing Copilot, Google Gemini и такие инструменты, как SearchGPT, похоже, демонстрируют ценность сущностно-ориентированного понимания, особенно для локальных целях поиска и проверки фактов.
Обучение и понимание сущностей
Поисковые системы с генеративным ИИ активно изучают большие базы данных, содержащие аннотации структурированных данных. Этот процесс обучения формирует то, как они работают и достигают результатов.
- Распознавайте и классифицируйте объекты (продукты, местоположения, организации).
- Реакция земли. Мы видим это в таких системах, как DataGemma, которые используют структурированные данные для обоснования ответов на проверяемых фактах.
- Типы запросов, специфичные для процесса, такие как поиск местного бизнеса и продуктов.
Это обучение формирует то, как системы ИИ интерпретируют запросы и отвечают на них, что особенно заметно в:
- Локальные бизнес-запросы, в которых атрибуты сущностей соответствуют шаблонам структурированных данных.
- Запросы продуктов, отражающие структурированные данные, предоставленные продавцом.
- Информация панели знаний, соответствующая определениям сущностей.
Интеграция с поисковыми системами
Различные платформы демонстрируют влияние структурированных данных посредством:
- Традиционный поиск. Богатые результаты и панели знаний, основанные непосредственно на структурированных данных.
- Интеграция поиска с использованием искусственного интеллекта:
<ул> - Bing Copilot показывает улучшенные результаты для структурированных объектов.
- Google Gemini отражает информацию о диаграмме знаний.
- Специализированные системы, такие как Perplexity.ai, демонстрируют понимание сущностей в запросах местоположения.
- Последний эксперимент Google с ИИ-консультантом по продажам, интегрированным в поисковую выдачу для запросов о покупках (это грандиозно! Вот на X, обнаружено с помощью SERP Alert).
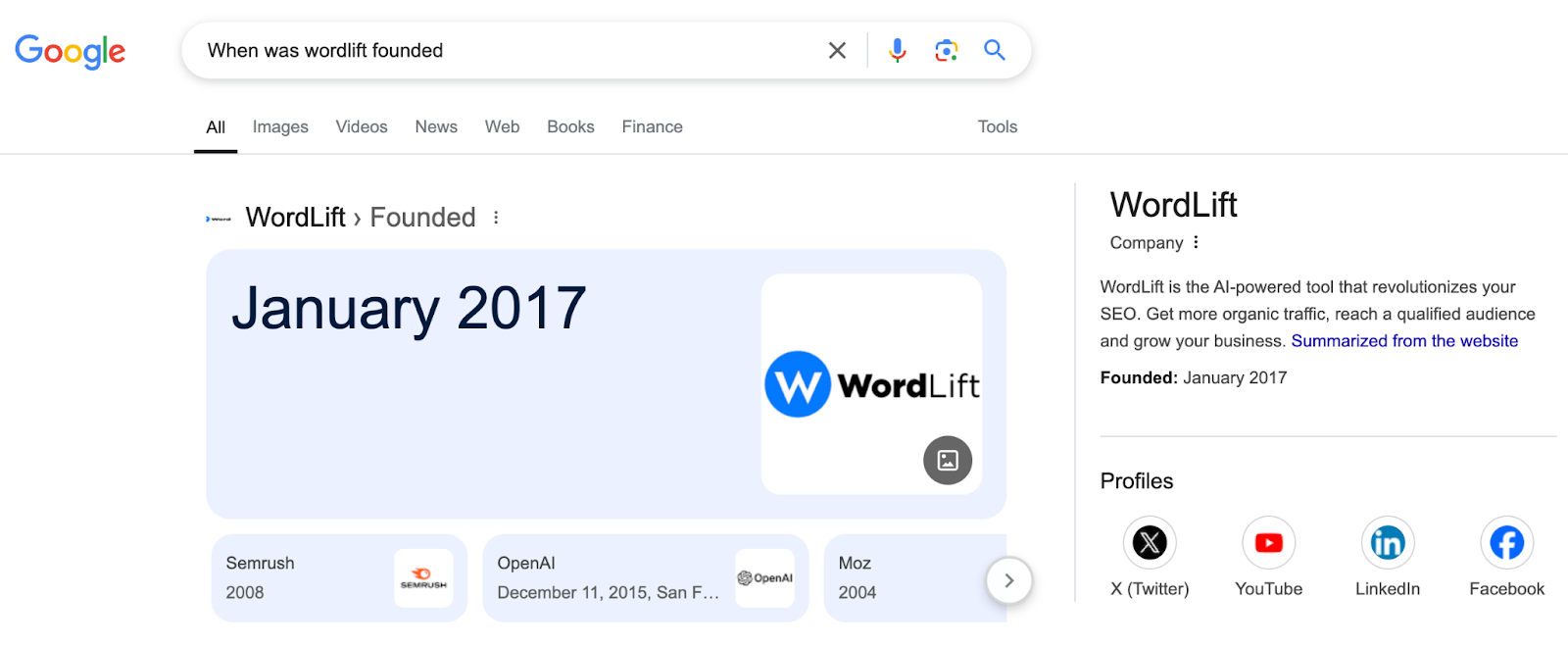 |
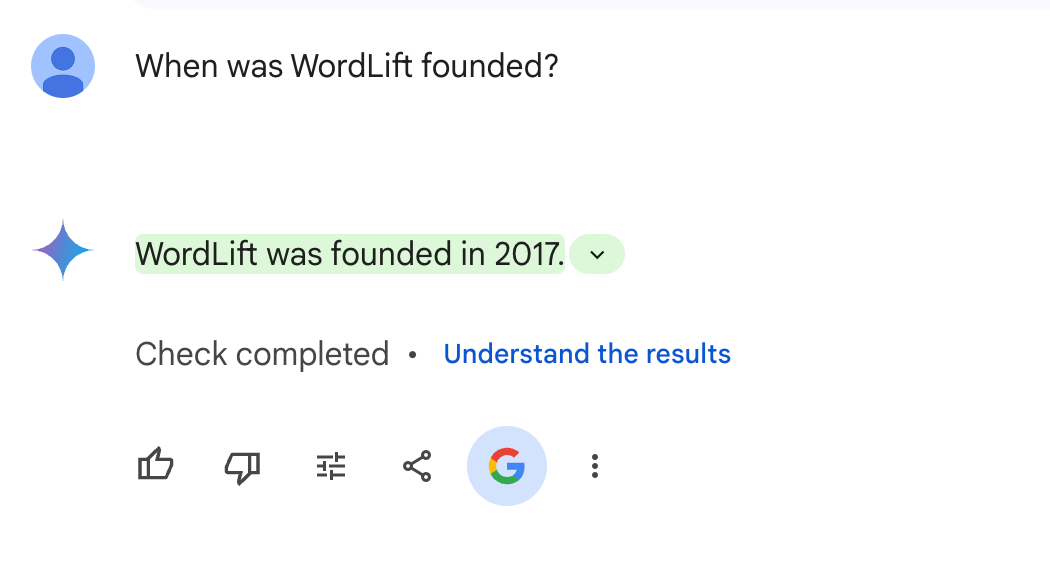 |
Вот пример того, как Gemini и Google Search используют один и тот же факт.
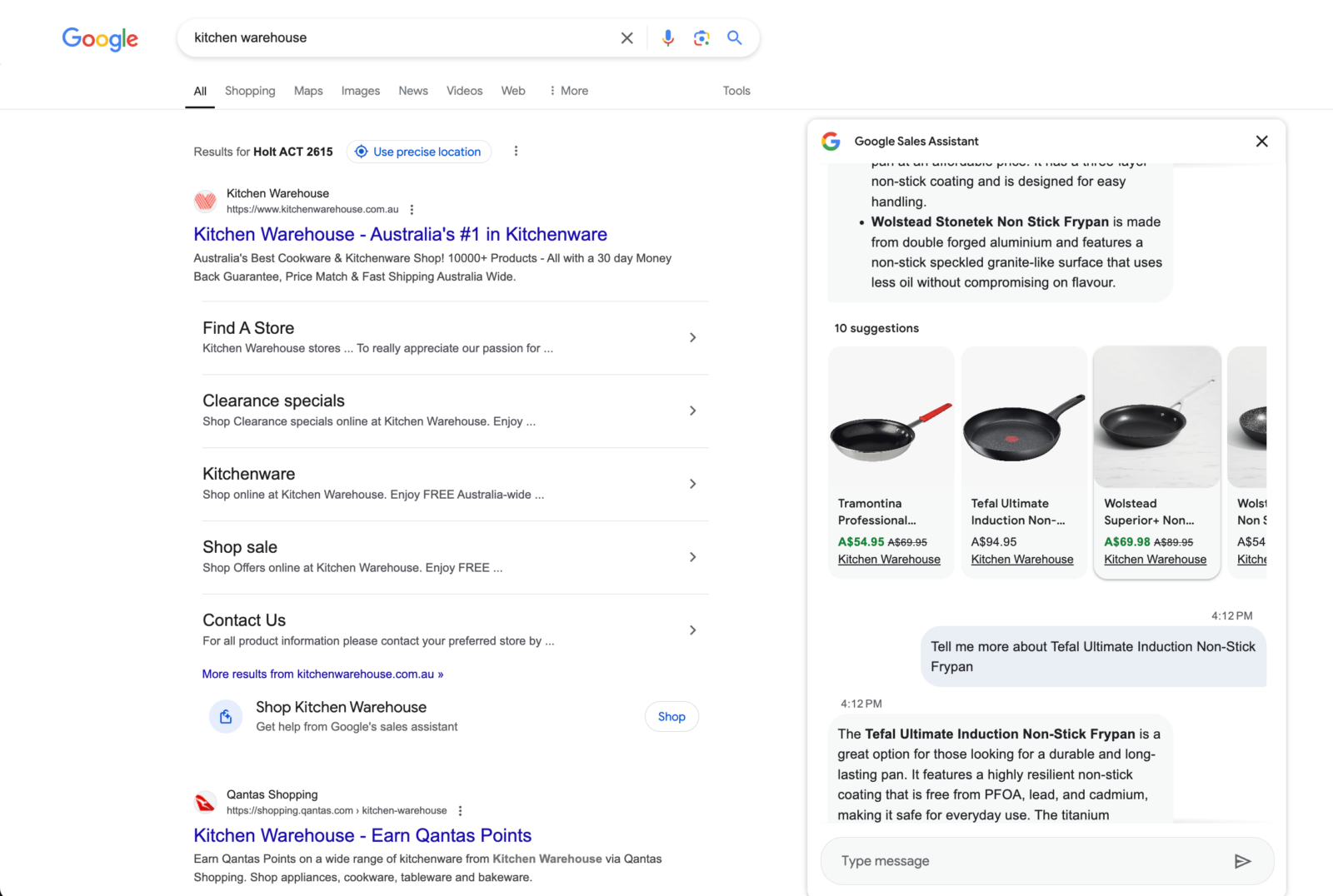
Проверка и проверка данных
Структурированные данные обеспечивают механизмы проверки посредством:
- График знаний. Такие системы, как Data Commons Google, используют структурированные данные для проверки фактов.
- Обучающие наборы. Разметка Schema.org создает надежные обучающие примеры для распознавания объектов.
- Конвейеры проверки. Инструменты создания контента, такие как WordLift, используют структурированные данные для проверки результатов ИИ.
Ключевое отличие заключается в том, что структурированные данные не влияют напрямую на ответы LLM, а скорее формируют поисковые системы ИИ посредством:
- Данные обучения, включающие структурированную разметку.
- Определения классов сущностей, которые помогают понять.
- Интеграция с традиционными расширенными результатами поиска.
Поскольку структурированные данные становятся все более важными, жизненно важно обеспечить их видимость как в обычных, так и в интеллектуальных поисковых системах, основанных на искусственном интеллекте.
В эпоху развития искусственного интеллекта инвестиции в организованные данные больше не предназначены только для поисковой оптимизации. Вместо этого речь идет о создании значимой основы или семантического слоя, который позволит машинам эффективно понимать и точно отображать вашу сущность.
Эволюция семантического SEO: от структурированных данных к семантическим данным
Практика SEO превратилась в семантическое SEO, выходя за рамки традиционной оптимизации ключевых слов и охватывая семантическое понимание:
Оптимизация на основе сущностей
- Сосредоточьтесь на четких определениях сущностей и отношениях.
- Реализация комплексных атрибутов объекта.
- Стратегическое использование свойств SameAs для устранения неоднозначности сущностей.
Контентные сети
- Разработка взаимосвязанных контент-кластеров.
- Четкая разметка авторства и указания авторства.
- Определения мультимедийных отношений.
Ключевые шаблоны реализации в JSON-LD
Публикация контента
Изучение структур данных на многочисленных веб-сайтах, которых насчитывается в общей сложности миллионы, позволяет выделить три основные стратегии, которые часто используют контент-провайдеры.
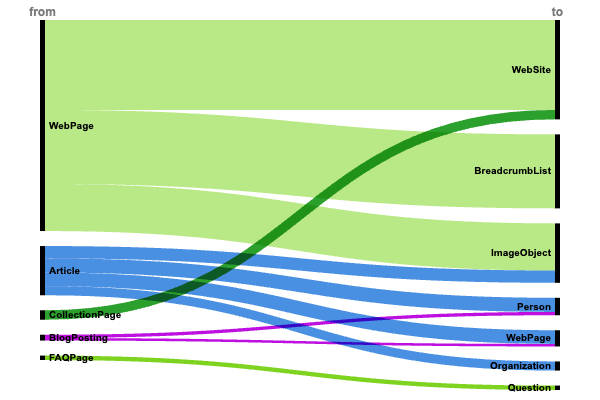
Структура и навигация веб-сайта (+6 миллионов внедрений)
Преобладание веб-страниц, принадлежащих веб-сайтам (более 5,8 миллиона), и наличие веб-страниц, связанных с хлебными списками (около 4,8 миллиона), ясно указывают на сильный акцент на структурированном макете сайта и удобной навигации на крупных онлайн-платформах.
Структура сайта служит основой для реализации структурированных данных, а это означает, что поисковые системы придают большое значение этим показателям при интерпретации порядка информации и ее релевантности.
Атрибуция и авторитет контента
Вокруг атрибуции контента возникают устойчивые закономерности:
- Статья → автор → Человек (925 000).
- Статья → Издатель → Организация (597 000).
- Публикация в блоге → автор → Человек (217 000).
Акцент на том, кто создал часть контента, и на авторитете ее организации становится все более важным, поскольку поисковые системы придают большее значение показателям экспертности, авторитетности, надежности (E-A-T) и общей авторитетности контента в своих системах ранжирования.
Мультимедийная интеграция
Последовательная реализация разметки изображений для всех типов контента:
- Веб-страница → PrimaryImageOfPage → ImageObject (3 миллиона)
- Статья → изображение → ImageObject (806 000)
Большое количество связей между СМИ позволяет предположить, что они признают важность хорошо организованного визуального контента, поскольку это повышает их видимость при поиске и улучшает взаимодействие с пользователем.
Данные показывают, что издатели выходят за рамки базовой SEO-разметки и создают комплексные машиночитаемые графики контента, которые поддерживают как традиционный поиск, так и новые системы обнаружения искусственного интеллекта.
Местный бизнес и розничная торговля
Анализ того, как местные предприятия реализовали свои структурированные данные, показывает три основных шаблона, которые наиболее распространены, когда речь идет о разметке на основе местоположения.
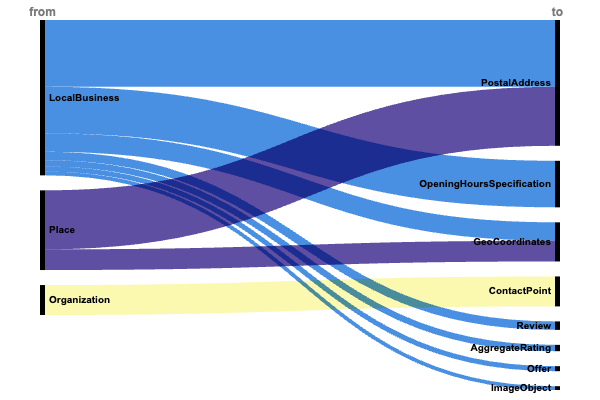
Расположение и доступность (+1,4 миллиона внедрений)
Широкое распространение разметки физического местоположения демонстрирует ее фундаментальную важность:
- LocalBusiness → адрес → PostalAddress (745 000).
- Место → адрес → Почтовый адрес (658 000).
- Организация → contactPoint → ContactPoint (334 000).
- LocalBusiness → Спецификация открытияHoursSpecification (519 000).
Ярким свидетельством того, что эти важные оперативные аспекты играют жизненно важную роль в обеспечении заметности местных обысков, является их солидный внешний вид.
Географическая точность
Значительная реализация географических координат показывает сосредоточенность на точном местоположении:
- Место → гео → Геокоординаты (231 000).
- LocalBusiness → geo → GeoCoordinates (205 000).
Использование адреса и координат при поиске местоположения подчеркивает важность, которую поисковые системы придают точному географическому расположению, повышая точность результатов локального поиска.
Сигналы доверия
Меньшая, но заметная группа шаблонов фокусируется на репутации:
- LocalBusiness → обзор → Обзор (94 000)
- LocalBusiness → AggregateRating → AggregateRating (70 000)
- LocalBusiness → фотографии → ImageObject (42 000)
- LocalBusiness → makeOffer → Offer (56 000)
Включение этих функций укрепления доверия, хотя и не всегда используется, обогащает местный бизнес, расширяя его присутствие в Интернете, а также помогая пользователям принимать обоснованные решения.
Электронная торговля (расширенный список)
Изучение организованной информации в интернет-магазинах показывает, что используются передовые стратегии, в первую очередь направленные на облегчение поиска продуктов и повышение шансов на продажу.
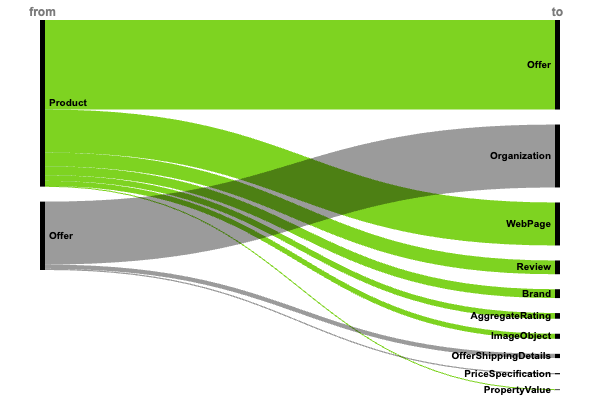
Информация об основном продукте (+4,7 миллиона внедрений)
Доминирование базовой товарной наценки показывает ее принципиальную важность:
- Товар → предложения → Предложение (3,1 млн).
- Предложение → Продавец → Организация (2,2 млн).
- Продукт → mainEntityOfPage → Веб-страница (1,5 миллиона).
Быстрое признание этих фундаментальных связей между продуктами позволяет предположить, что они играют решающую роль в процессе изучения продукта и его воздействия на продавцов.
Доверие и социальное доказательство
Значительная реализация разметки, связанной с отзывами:
- Товар → обзор → Обзор (490 000).
- Продукт → AggregateRating → AggregateRating (201 000).
- Обзор → ОбзорРейтинг → Рейтинг (110 000).
Как специалист по цифровому маркетингу, я не могу не отметить важную роль, которую разметка отзывов играет в повышении конверсий в электронной коммерции. Другими словами, похоже, что социальное доказательство по-прежнему имеет огромное значение, когда дело доходит до решений о покупках в Интернете.
Расширенный контекст продукта
Реализация расширенных атрибутов продукта демонстрирует акцент на подробной информации о продукте:
- Товар → бренд → Бренд (315 000).
- Продукт → Дополнительное свойство → Значение свойства (253 000).
- Товар → изображение → ImageObject (182 000).
- Предложение → Сведения о доставке → ПредложениеСведения о доставке (151 000).
- Предложение → Спецификация цены → Спецификация цены (42 000).
- Совокупное предложение → предложения → Предложение (69 000).
Использование многоуровневой стратегии для функций продукта создает подробные профили продуктов, повышая их обнаруживаемость при поиске, а также помогая пользователям принимать обоснованные решения.
Перспективы на будущее
Значимость структурированных данных выходит за рамки их первоначальной цели в качестве SEO-актива для создания расширенных фрагментов и специализированных функций поиска. В эпоху искусственного интеллекта структурированные данные становятся важнейшим средством машинного понимания, меняя способы понимания и связывания контента в Интернете. Этот переход заставляет отрасль сосредоточиться на стратегиях оптимизации, которые выходят за рамки подходов, ориентированных на Google, и ценят структурированные данные как ключевой элемент семантической сети, интегрированной с искусственным интеллектом.
Структурированные данные служат основой для создания взаимосвязанных, понятных систем, предназначенных для машин. Эти системы имеют решающее значение для современных приложений искусственного интеллекта, таких как диалоговый поиск, карты знаний и системы, которые улучшают генерацию с использованием графов (GraphRAG или RAG). Эта разработка требует двойной стратегии: использование практических типов схем для получения немедленных преимуществ SEO (богатых результатов) и одновременной разработки подробных описательных схем для создания более широкой сети данных.
Как профессионал в области цифрового маркетинга, я твердо верю, что будущее нашей области лежит на перекрестке структурированных данных, семантического моделирования и интеллектуальных систем обнаружения контента. Перейдя к более комплексному подходу, организации могут превратить использование структурированных данных из тактического улучшения SEO в стратегическую основу для обеспечения взаимодействия ИИ и обеспечения прозрачности на нескольких платформах.
Кредиты и Благодарности
Полная глава «Структурированные данные веб-альманаха» предлагает еще более глубокое понимание меняющейся ситуации в области реализации структурированных данных.
На нашем пути к будущему, в котором доминирует искусственный интеллект, значимость хорошо организованных данных будет только возрастать с точки зрения их стратегической ценности.
Смотрите также
- Акции AKRN. Акрон: прогноз акций.
- Обновление Google о спаме, декабрь 2024 г. Жесткое деиндексирование и понижение рейтинга некоторых сайтов
- Структурированные данные в 2024 году: ключевые закономерности открывают будущее открытий искусственного интеллекта [исследование данных]
- e-pick: Ваши заветные карты ждут! 🎉
- Snapchat-маркетинг: подробное руководство для бизнеса
- Голосовой поиск SEO: как это работает?
- Google может меньше полагаться на Hreflang и перейти на автоматическое определение языка
- Google Персонализирует Некоторые Обзоры ИИ и Ответы в Режиме ИИ
- Акции NVTK. НОВАТЭК: прогноз акций.
- В Google Ads появился новый флажок: измененный или синтетический контент
2024-12-03 15:39