

Понимание намерений поиска — сложная задача, которую можно решать различными способами. Один из подходов включает использование продвинутых алгоритмов обучения для интерпретации намерений поиска путем классификации текста и разбора названий страниц результатов поисковой системы (SERP) с использованием методов обработки естественного языка (NLP). Другой стратегией является группировка результатов по их семантической близости, при этом детально объясняются преимущества этих методик.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Помимо распознавания преимуществ понимания поискового намерения (intent), мы обладаем несколькими методами эффективного масштабирования и автоматизации.
Так почему нам нужна ещё одна статья об автоматизации интентов поиска?
Ищет намерение сейчас еще важнее, так как появился поиск на основе искусственного интеллекта.
В отличие от эпохи поиска с десятью синими ссылками, когда результаты были изобильными, технология ИИ для поисковых систем стремится снизить затраты на вычисления в операциях над плавающей точкой (FLPO), чтобы эффективно предоставлять свои услуги.
Поисковые результаты по-прежнему содержат лучшие инсайты относительно намерений поиска
Как специалист по SEO, я добился успеха с двумя основными стратегиями. Первая стратегия заключается в создании собственной системы искусственного интеллекта: собираются названия контента со страниц высокого ранга для конкретного ключевого слова, после чего данные вводятся в специально созданную и проверенную модель нейросети. В качестве альтернативы я использую обработку естественного языка (NLP) для группировки ключевых слов, что позволяет выявлять паттерны, тренды и потенциальные возможности для эффективного улучшения усилий по SEO.
https://www.searchenginejournal.com/wp-json/sscats/v2/tk/Middle_Post_Text
Как быть, если у вас нет времени или знаний для создания собственного ИИ (искусственного интеллекта) или использования API Открытого Искусственного Интеллекта?
Вместо того чтобы полагаться исключительно на сходство косинусов как идеальное решение для экспертов по поисковой оптимизации в вопросе определения тем и структуры веб-сайта, я считаю группирование результатов поиска по результатам SERP значительно более эффективным подходом.
Это связано с тем, что ИИ сильно зависит от результатов поисковых систем как основы для своих выводов, и этому есть веская причина – он разработан для имитации поведения пользователей.
Альтернативный подход использует встроенные возможности ИИ от Google для выполнения задач за вас, позволяя обойти необходимость вручную собирать данные с страниц результатов поиска и создавать собственную модель ИИ.
Предположим, Google ранжирует URL-адреса вебсайтов в зависимости от того, насколько хорошо их содержимое соответствует запросу пользователя, причем наиболее релевантные находятся сверху. Это значит, что если две ключевые слова имеют одну и ту же цель, результаты поиска (SERPs) будут очень похожи.
В течение долгого времени эксперты по поисковой оптимизации анализировали страницы результатов поисковых систем (SERP) для конкретных ключевых слов, чтобы понять и не отставать от общих намерений пользователей за этими запросами, что не является чем-то новым в контексте основных обновлений.
Здесь главное преимущество заключается в автоматизации и расширении процесса сравнения, обеспечивая эффективность и повышенную точность.
Как кластеризовать ключевые слова по поисковому намерению на масштабном уровне с помощью Python (с кодом)
Предполагая, что у вас есть результаты поисковой выдачи в формате CSV, давайте импортируем их в вашу записную книжку на Python.
Импортируйте список в свой блокнот на Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Ниже представлен файл SERP, который сейчас импортирован в DataFrame Pandas.
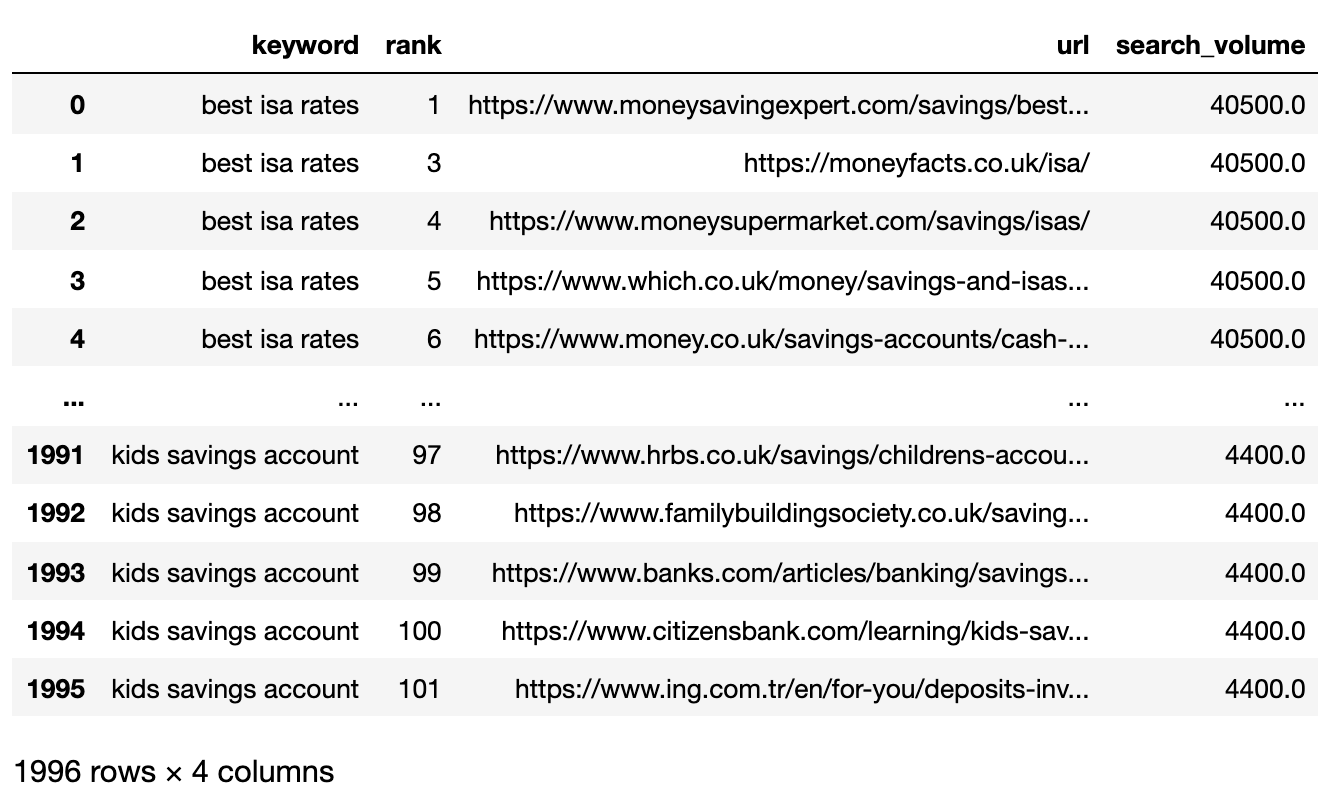
Фильтрация данных для страницы 1
Мы хотим сравнить результаты на первой странице каждого SERP между ключевыми словами.
Чтобы наша функция фильтрации работала эффективно, мы разделим большой датафрейм на более мелкие датафреймы по ключевым словам. Таким образом, можно будет фильтровать данные на уровне ключевых слов, а затем объединить все эти мини-датафреймы обратно в один всеобъемлющий датафрейм.
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
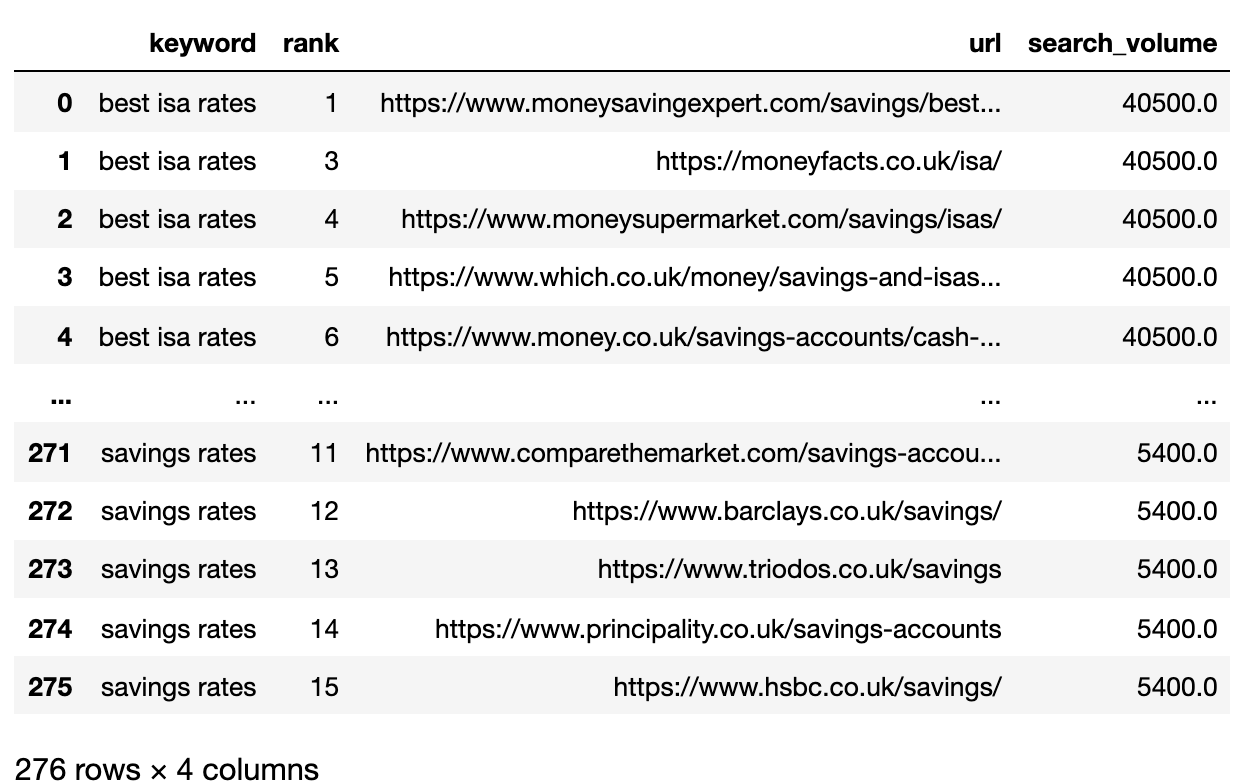
Преобразовать URL рейтинга в строку
Поскольку URL-адреса из результатов поисковых запросов превышают количество уникальных ключевых слов, необходимо сократить эти URL в краткий формат одной строки, который включает ключевое слово и его SERP.
Вот как:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Ниже показано описание поисковой выдачи (SERP), сжатое в одну строку для каждого ключевого слова.
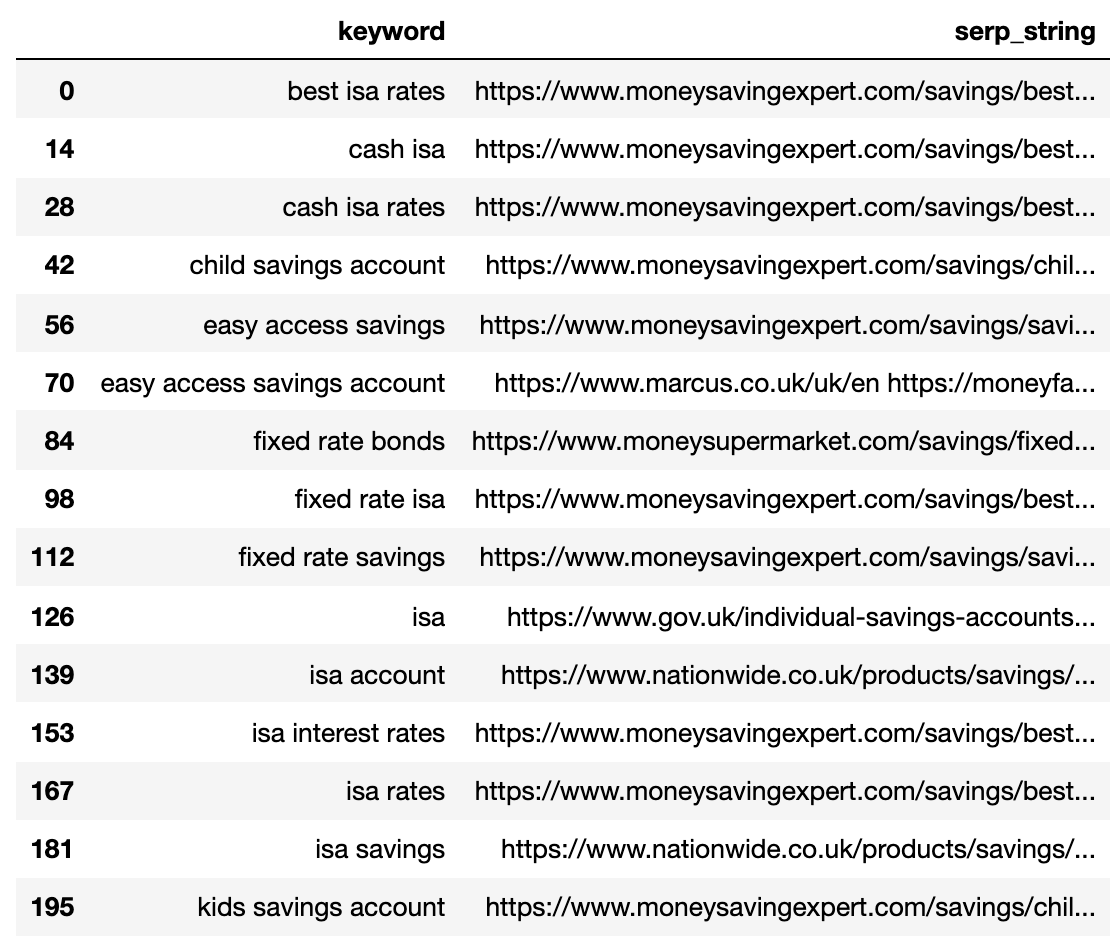
Сравните расстояние до поисковой выдачи (SERP)
Для выполнения сравнения нам теперь необходимы все возможные сочетания пар ключевых слов (SERP) с другими парами.
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

Предоставленная выше информация отображает все пары ключевых слов и соответствующие им страницы результатов поисковой системы (SERP), что позволяет легко сравнивать строки SERP.
Функция serp_compare оценивает схожесть, проверяя соответствующие сайты и их расположение на страницах результатов поисковой системы (SERP).
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Теперь что сравнения выполнены, можно начать кластеризацию ключевых слов.
Мы будем рассматривать любые ключевые слова, у которых взвешенное сходство составляет 40% или более.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
We now have the potential topic name, keywords SERP similarity, and search volumes of each.
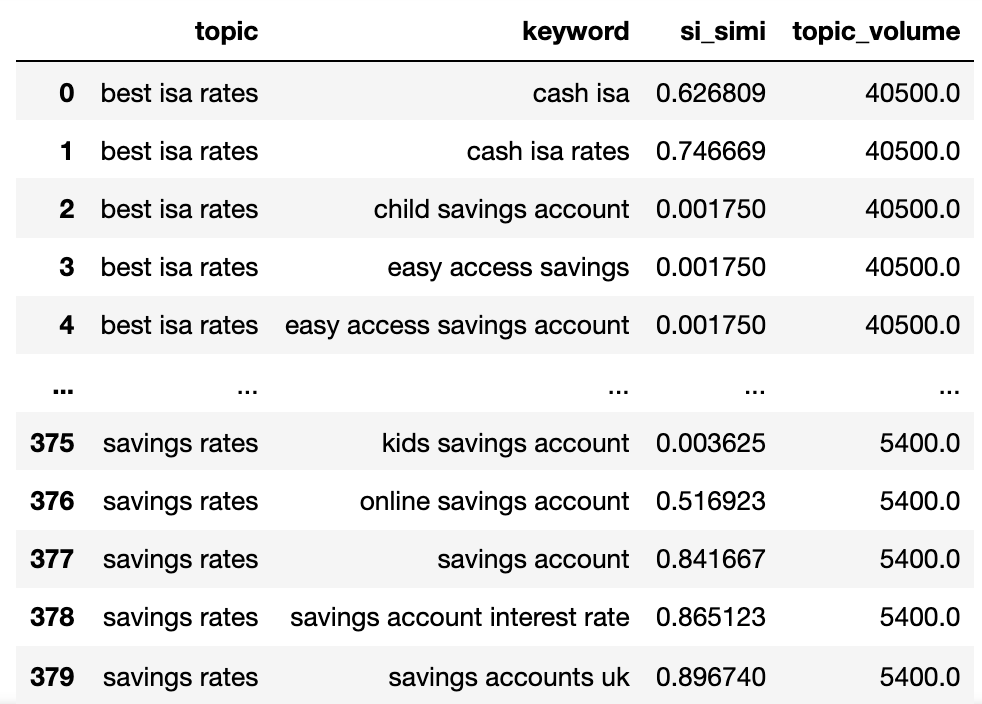
Вы заметите, что ключевое слово и keyword_b были переименованы в тему и ключевое слово соответственно.
Теперь мы будем перебирать столбцы в датафрейме, используя технику лямбда.
Использование лямбда-функций может повысить эффективность прохода по строкам в Pandas DataFrame, поскольку преобразует каждую строку в список вместо использования метода .iterrows(), который проходит по индексу и значениям каждой строки отдельно.
Здесь идёт:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
Вот организованный словарь ключевых слов, разделенных по их предназначению для поисковых запросов: 1. Информационные ключевые слова 2. Навигационные ключевые слова 3. Транзакционные ключевые слова 4. Коммерческие исследовательские ключевые слова 5. Словарные ключевые слова 6. Бренды-ключевые слова 7. Сравнительные ключевые слова 8. Модифицирующие ключевые слова 9. Отрицательные ключевые слова 10. Географические ключевые слова Каждая группа представляет категорию ключевых слов, которые пользователи могут использовать при поиске конкретного вида информации или действий в интернете.
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Давайте поместим это в DataFrame.
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
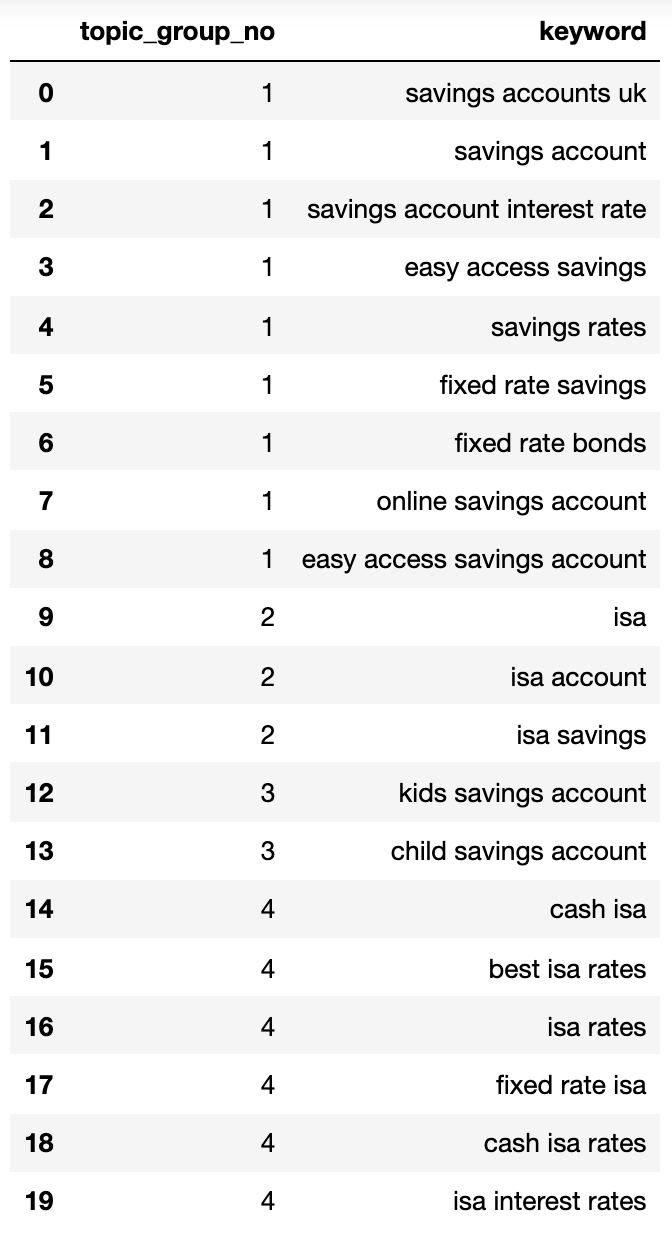
Как специалист по цифровому маркетингу могу с уверенностью сказать, что предоставленные категории поискового намерения предлагают надежное представление ключевых слов, охватываемых каждой группой. Обычно именно такого уровня точности стремятся достичь специалисты по поисковой оптимизации (SEO).
Подход, даже с задействованием нескольких ключевых слов, очевидно имеет потенциал для расширения, чтобы вместить гораздо больше (потенциально намного более тысяч).
Активация выходов для улучшения вашего поиска
Абсолютно верно, мы можем углубиться ещё дальше с помощью нейронных сетей для улучшения процесса кластеризации, обеспечивая более высокий уровень точности на основе ранжирования контента. Некоторые существующие коммерческие решения уже внедрили такой подход для лучшего группирования и именования кластеров.
Сейчас с этим результатом вы можете:
- Встройте это в свои собственные системы дашбордов SEO, чтобы сделать тренды и отчеты по SEO более значимыми.
- Создавайте более эффективные платные поисковые кампании, структурируя аккаунты Google Рекламы по поисковому намерению для повышения качества оценок.
- Объедините дублирующиеся URL-адреса поиска товаров
- Структурируйте таксономию сайта по продаже товаров в соответствии с намерением поиска, а не обычным каталогом продуктов.
Безусловно, буду рад обсудить любые дополнительные приложения, которые вы считаете значимыми и не были затронуты до сих пор.
Кстати, ваше исследование ключевых слов SEO стало немного более эффективным, точным и быстрым!
Скачайте полный код здесь для собственного использования.
Смотрите также
- Google: заманчиво оптимизировать показатели инструментов; Нет ярлыков для SEO
- TIA/USD
- Bing Поддерживает data-nosnippet для поисковых сниппетов и ответов ИИ.
- Великий поворот: почему агентства заменяют PPC предсказуемым SEO
- ДжейПи Морган против Близнецы: Сказка о гигантах банковского дела и двойных нарушителях спокойствия 💸
- Биткоин-киты становятся толще, но продолжают вести себя как нервные коровы – вот почему вам стоит об этом беспокоиться
- Google заявляет, что временные аномалии влияют на сканирование Googlebot
- 11 лучших книг по SEO, которые вам стоит прочитать
- Резкое падение Bitcoin: утонет ли он в супе за $60k? 🍲💰
- 8 из 10 видеороликов брендов в TikTok не привлекают внимание
2025-05-19 15:39