

Многие люди полагают, что добавление структурированных данных на ваш веб-сайт улучшит его отображение в результатах поиска на основе искусственного интеллекта. Однако недавние тесты показывают, что это в настоящее время не так – добавление структурированных данных, по крайней мере на данный момент, не оказывает влияния на видимость в поиске с использованием ИИ.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Марк Уильямс-Кук первым начал это исследовать, поделившись экспериментом в LinkedIn. Он продемонстрировал, что большие языковые модели (БЯМ) фактически не используют структурированные данные во время своего основного обучения. Его эксперимент показал, что когда БЯМ обрабатывают веб-страницу, они эффективно удаляют структурированные данные, что означает, что они не используются.
Он написал:
Большие языковые модели работают, разбивая контент на ‘токены’. Это означает, что они берут распространенные последовательности символов, найденные в тексте, и создают уникальный ‘токен’ для этого набора. Затем модель использует миллиарды образцов ‘окон’ из этих наборов токенов для построения прогноза о том, что будет дальше.
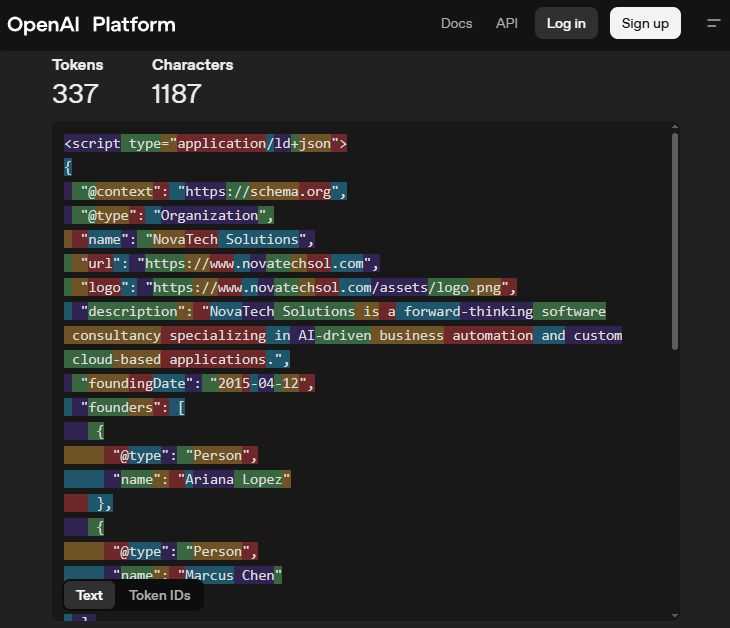
На изображении показан пример того, как GPT-4o выделяет уникальные слова или части слов изменением цвета. Это облегчает идентификацию каждого отдельного ‘токена’, который использует модель.
Схема структурированных данных фрагментируется в процессе обработки. Например, схема вроде ‘@type’: ‘Organization’ разбивается на отдельные токены: ‘type’ и ‘Organization’. Это означает, что система относится к этим терминам схемы так же, как к обычным словам, что затрудняет их различение во время токенизации.
Если в обучающих данных содержалась информация об определенной структуре, это означало бы лишь небольшую вероятность увидеть такие символы, как ‘@’ перед словом ‘content’. Этот эффект, вероятно, не важен.
Вот его скриншот:
Я сам разбирался в этом, и Хулио К. Гевара также провёл несколько очень интересных тестов, которыми он поделился в LinkedIn. По сути, он создал две идентичные страницы продукта для полностью вымышленного товара – чего-то, с чем ни Gemini, ни ChatGPT раньше не сталкивались. На одной странице был весь контент, который вы обычно видите – текст и структурированные данные – а на другой *только* структурированные данные, что делало её полностью пустой для обычного пользователя. Это был умный способ выяснить, насколько каждая ИИ полагается на видимый текст по сравнению с данными, скрытыми за кулисами.
Тесты не показали никаких положительных результатов. Как он объяснил, они экспериментировали с множеством различных запросов, пытаясь заставить модели искусственного интеллекта извлекать такие детали, как цена, цвета и коды продуктов. Однако это работало только тогда, когда эта информация уже была представлена в виде текста на странице.
Его тест показал, что LLM даже не могли увидеть текст внутри структурированных данных.
Конечно, все это может измениться в будущем, но вот некоторые предварительные результаты тестирования.
Смотрите также
- Проверка статуса судебных дел против Google.
- Солана: Цены как американские горки, о которых вы не подозревали!
- Google добавляет атрибут «Сборка на заказ» для объявлений о транспортных средствах.
- Выпуск WordPress Security 6.9.4 исправляет проблемы, которые не были решены в 6.9.2.
- Волатильность ранжирования Google Search нарастает 3 и 4 декабря.
- Google обновляет политику запрещенного использования генеративного искусственного интеллекта
- Google: #1 Запуски Google Ads в 2025 году
- Как заставить социальные сети и SEO работать вместе
- Обновление ядра Google от июня 2025 года в процессе развертывания — что мы видим на текущий момент
- Мечты об ETF для Биткойна разрушены: Традиционные финансы отказываются от криптовалюты, как это было в 2018 году!
2025-09-15 15:16