

Как опытный специалист по SEO с многолетним опытом работы в цифровой среде за плечами, я искренне поддерживаю использование инструментов аудита веб-сайтов, таких как WebSite Auditor, Screaming Frog, Lumar, Oncrawl или SE Ranking, для обеспечения бесперебойного взаимодействия с пользователем и оптимизации производительности вашего сайта.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Идея краулингового бюджета относится к важнейшему принципу SEO, применимому к обширным веб-сайтам, содержащим миллионы страниц, а также к небольшим сайтам с тысячами ежедневно меняющихся страниц. Все дело в том, как боты поисковых систем распределяют свое время и ресурсы при сканировании этих веб-сайтов.
Примером веб-сайта с миллионами страниц может служить eBay.com, а веб-сайтами с десятками тысяч страниц, которые часто обновляются, могут быть веб-сайты с обзорами пользователей и рейтингами, подобные Gamespot.com.
SEO-специалист обычно сталкивается с многочисленными задачами и проблемами, из-за чего процесс сканирования веб-сайта иногда задерживается или ему уделяется меньше внимания.
Но краулинговый бюджет можно и нужно оптимизировать.
В этой статье вы узнаете:
- Как улучшить свой краулинговый бюджет.
- Изучите изменения в краулинговом бюджете как концепции за последние пару лет.
Если ваш сайт содержит всего несколько сотен страниц, но они не индексируются, мы советуем вам взглянуть на нашу статью, в которой обсуждаются распространенные причины проблем с индексацией. Вряд ли проблема кроется в краулинговом бюджете, если на вашем сайте такое небольшое количество страниц.
Что такое краулинговый бюджет?
Термин «бюджет сканирования» описывает, сколько веб-страниц исследуется роботами поисковых систем (такими как пауки и боты) в течение определенного периода.
Существуют определенные соображения, влияющие на бюджет сканирования, например, предварительный баланс между попытками робота Googlebot не перегружать ваш сервер и общим желанием Google сканировать ваш домен.
Улучшение оптимизации бюджета сканирования включает в себя реализацию стратегий, направленных на повышение эффективности и скорости доступа роботов поисковых систем к вашим веб-страницам, тем самым повышая частоту их посещений.
Почему важна оптимизация бюджета сканирования?
Первоначальное появление в результатах поиска начинается с изучения или «сканирования» поисковыми системами. Если страница не сканируется, ни новые, ни обновленные страницы не будут включены в базу данных поисковой системы.
Частое посещение сканерами ваших веб-страниц означает более быстрое включение обновлений и вновь созданных страниц в индекс поисковой системы. Это, в свою очередь, сокращает время, необходимое для того, чтобы ваши стратегии оптимизации стали эффективными и повлияли на ваш поисковый рейтинг.
Индекс Google охватывает бесчисленные миллиарды веб-страниц, и это число ежедневно увеличивается. Чтобы сэкономить на затратах, связанных со сканированием каждого URL-адреса, по мере создания большего количества сайтов, поисковые системы стремятся замедлить скорость сканирования URL-адресов и выборочно включать их в свои индексы, тем самым минимизируя затраты на вычисления и хранение.
Растет ощущение необходимости сократить выбросы углекислого газа из-за изменения климата, и у Google есть комплексный план по повышению устойчивости и минимизации выбросов углекислого газа в долгосрочной перспективе.
Итак, давайте обсудим, как вы можете оптимизировать свой краулинговый бюджет в современном мире.
1. Запретить сканирование URL-адресов действий в robots.txt
Это может стать шоком, но Google подтвердил, что запрет на индексацию определенных URL-адресов не повлияет на скорость сканирования вашего сайта. Другими словами, Google продолжит исследовать ваш сайт с той же скоростью. Однако вы можете задаться вопросом, почему эта тема актуальна здесь. Причина в том, что понимание того, как работает краулинговый бюджет, может помочь оптимизировать наиболее важные для вас страницы вашего сайта, обеспечивая их тщательное исследование поисковыми роботами Google.
Если вы ограничиваете несущественные URL-адреса, по сути, вы просите Google чаще сканировать ценные разделы вашего сайта.
Если ваш сайт включает встроенную функцию поиска с использованием таких запросов, как /search/term=Google, поисковые системы, такие как Google, будут индексировать эти URL-адреса, когда они будут найдены в ссылках в других местах сети.
Аналогичным образом на веб-сайте электронной коммерции вы можете встретить URL-адреса, созданные с использованием фасетных фильтров, например: /filter-options/color/red/and/filter-options/size/small
Эти параметры, обнаруженные в строках запроса, могут генерировать бесконечное количество различных версий URL-адресов, которые Google может попытаться изучить в процессе сканирования веб-страниц.
По сути, в этих URL-адресах отсутствует эксклюзивный контент, и они в основном сортируют уже имеющиеся у вас данные, что полезно для взаимодействия с пользователем, но не идеально для веб-сканеров, таких как Googlebot.
Ограничение сканирования определенных URL-адресов Google с помощью инструкций robots.txt может помочь оптимизировать бюджет сканирования и сделать его более эффективным. Таким образом, Google будет расставлять приоритеты и направлять свои ресурсы сканирования на более полезные страницы вашего веб-сайта, тем самым улучшая общую возможность сканирования вашего сайта.
Вот как заблокировать внутренний поиск, фасеты или любые URL-адреса, содержащие строки запроса, через robots.txt:
Disallow: *?*s=*
Disallow: *?*color=*
Disallow: *?*size=*
Каждое правило запрещает любой URL-адрес со своим конкретным параметром запроса, независимо от каких-либо дополнительных параметров, которые он может иметь.
- * (звездочка) соответствует любой последовательности символов (включая отсутствие).
- ? (Знак вопроса): указывает начало строки запроса.
- =*: Соответствует знаку = и всем последующим символам.
Использование этого метода предотвращает повторение, делая определенные URL-адреса с указанными параметрами запроса невидимыми для сканеров поисковых систем.
Имейте в виду, что при использовании этого метода любые URL-адреса с указанными символами будут запрещены независимо от их местоположения. Это может непреднамеренно заблокировать определенные URL-адреса. Например, параметр запроса, состоящий из одного символа, может запретить доступ ко всем URL-адресам, содержащим этот символ, даже если он находится в другой части URL-адреса. Если вы хотите запретить URL-адреса с определенным одним символом, рассмотрите возможность использования вместо этого набора правил: таким образом вы можете специально настроить таргетинг на символы, которые хотите запретить, без потенциальной блокировки других действительных URL-адресов.
Disallow: *?s=*
Disallow: *&s=*Критическое изменение заключается в том, что между символами «?» и «s» нет звездочки «*». Этот метод позволяет запретить определенные точные параметры «s» в URL-адресах, но вам придется добавлять каждый вариант индивидуально.
Включите эти рекомендации в свои уникальные сценарии для любых URL-адресов, которые не предлагают эксклюзивный контент. Например, если ваши кнопки списка желаний ведут к URL-адресам типа «?add_to_wishlist=1», вам следует запретить доступ к ним с помощью правила: Исключить или заблокировать использование таких URL-адресов.
Disallow: /*?*add_to_wishlist=*Это простой и естественный первый и самый важный шаг, рекомендованный Google.
Запретив учитывать определенные параметры, Google удалось уменьшить количество сканируемых страниц с нерелевантными строками запросов. Это произошло потому, что Google сталкивался с многочисленными URL-адресами с разными значениями параметров, которые приводили к несуществующим или бессмысленным страницам.
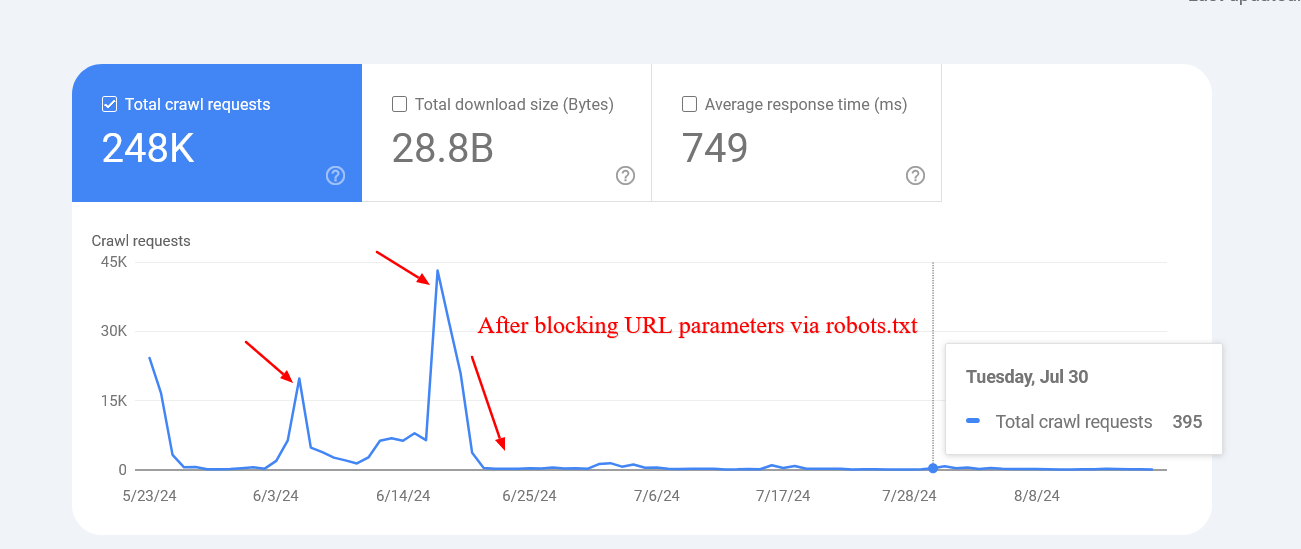
Иногда поисковые системы потенциально могут сканировать и индексировать URL-адреса, которые должны быть запрещены. Это может показаться необычным, но обычно не стоит беспокоиться. Чаще всего это указывает на то, что другие сайты ссылаются на эти конкретные URL-адреса.
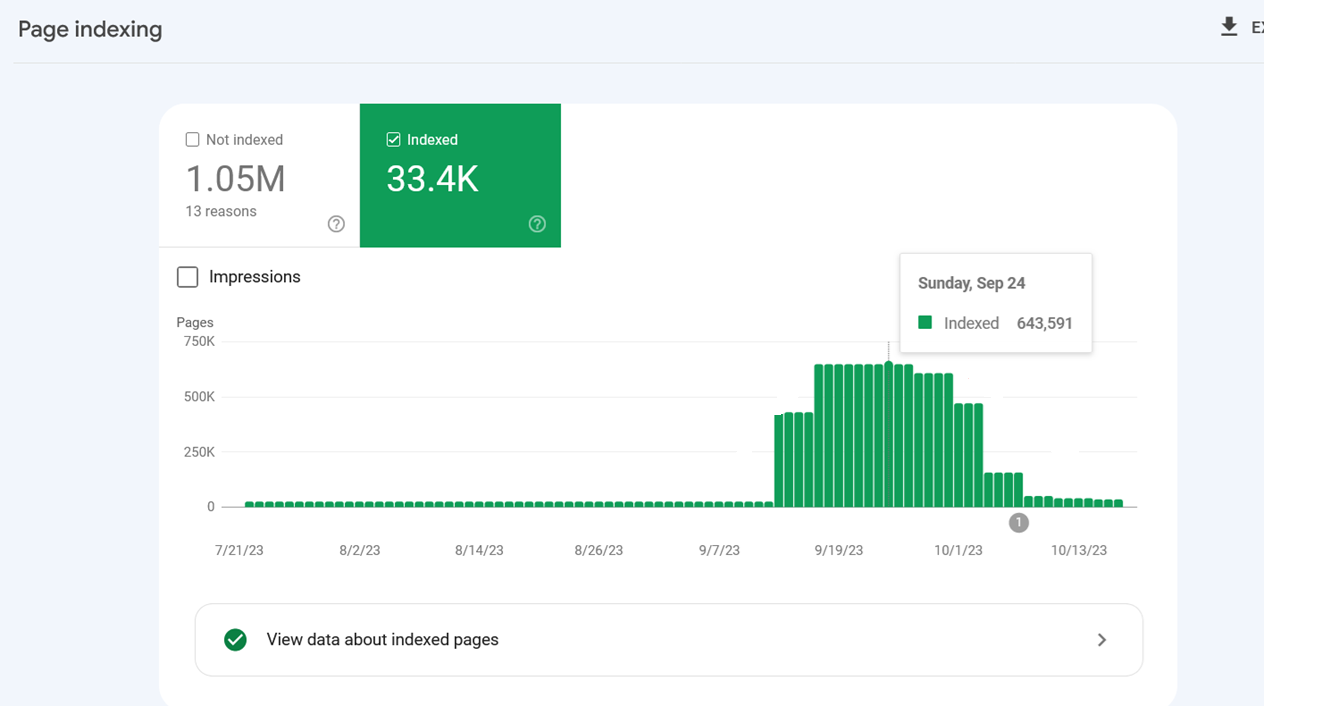
Google подтвердил, что в этих случаях активность сканирования со временем снизится.
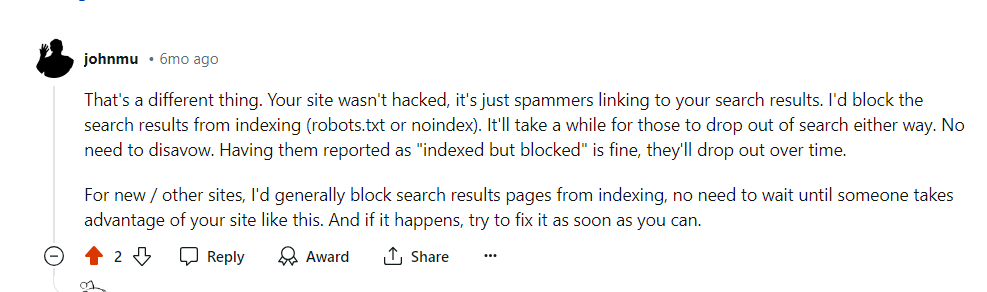
Избегайте применения «мета-тегов noindex» в целях блокировки, так как роботу Googlebot необходимо сделать запрос на просмотр тега, что неоправданно расходует ваш краулинговый бюджет, поскольку он не сразу распознает блокировку. Вместо этого рассмотрите возможность использования соответствующих кодов ответов HTTP или файла robots.txt для эффективного управления индексированием.
1.2. Запретить URL-адреса неважных ресурсов в файле Robots.txt
Как опытный веб-мастер, я бы рекомендовал предпринять дополнительный шаг для защиты вашего сайта: заблокировать все внешние файлы JavaScript, которые не влияют на структуру или внешний вид сайта. Это помогает гарантировать, что в вашем домене выполняются только нужные сценарии.
Например, если у вас есть файлы JavaScript, отвечающие за открытие изображений во всплывающем окне при нажатии пользователем, вы можете запретить их использование в файле robots.txt, чтобы Google не тратил бюджет на их сканирование.
Вот пример правила запрета файла JavaScript:
Запретить: /assets/js/popup.js
Дополнительная иллюстрация включает интерфейсы REST API для отправки форм. Предположим, у вас есть форма, которая указывает на URL-адрес «/api/form-submissions». Этот URL-адрес служит местом назначения, куда будут отправлены отправленные данные из вашей формы.
Вполне возможно, что эти URL-адреса могут быть проиндексированы Google. Однако они не имеют ничего общего с аспектом отображения, поэтому было бы разумно запретить к ним доступ.
Запретить: /rest-api/form-submissions/
Вместо этого важно убедиться, что конечные точки REST API, используемые автономной CMS, не заблокированы, поскольку они обычно используются для динамической загрузки контента.
Короче говоря, посмотрите на все, что не связано с рендерингом, и заблокируйте их.
2. Следите за цепочками перенаправления
Вместо прямого пути цепное перенаправление происходит, когда несколько веб-адресов ведут к другим адресам, которые продолжают перенаправляться. Если этот процесс повторяется слишком часто, сканеры поисковых систем могут отказаться от попыток добраться до конечного пункта назначения до того, как они туда доберутся.
Один URL-адрес ведет к другому, который затем ведет к третьему, и эта закономерность может продолжаться. Стоит отметить, что эти цепочки иногда могут создавать бесконечные циклы, в которых URL-адреса продолжают перенаправляться друг на друга.
Избегать этого — разумный подход к здоровью веб-сайта.
В идеале вы могли бы избежать наличия хотя бы одной цепочки перенаправлений на всем вашем домене.
Однако решение проблем с перенаправлением на большом сайте может оказаться сложной задачей из-за появления как 301, так и 302 перенаправлений. К сожалению, исправить перенаправления, вызванные входящими ссылками, сложно, поскольку нам не хватает контроля над внешними веб-сайтами.
Несколько случайных перенаправлений не вызовут серьезных проблем, но расширенные цепочки или циклы могут привести к осложнениям.
Чтобы определить цепочки перенаправления для устранения неполадок, рассмотрите возможность использования инструментов SEO, таких как Screaming Frog, Lumar или Oncrawl. Эти удобные инструменты помогут вам найти цепи.
Когда вы сталкиваетесь с цепочкой, оптимальным решением будет исключить все URL-адреса от начальной страницы до последней. Например, если ваша цепочка охватывает семь страниц, вместо этого напрямую перенаправьте первый URL-адрес на седьмой.
Как опытный веб-мастер, я хотел бы поделиться практическим советом по минимизации цепочек перенаправлений: вместо того, чтобы полагаться на перенаправления, обновите свою систему управления контентом (CMS), указав конечные пункты назначения внутренних URL-адресов, которые в настоящее время перенаправляют. Эта простая настройка может значительно улучшить производительность сайта и удобство для пользователей.
В зависимости от используемой вами системы управления контентом (CMS) могут применяться различные методы; например, вы можете использовать определенный плагин в среде WordPress. Однако если вы работаете с другой CMS, вам может потребоваться индивидуальное решение или обратитесь за помощью к своей команде разработчиков.
3. Используйте рендеринг на стороне сервера (HTML), когда это возможно.
Говоря о Google, его инструмент веб-сканирования работает с самой последней версией Chrome, гарантируя, что он может легко воспринимать контент, динамически генерируемый с помощью JavaScript, без каких-либо проблем.
Имейте в виду, что минимизация вычислительных затрат имеет решающее значение для Google, поскольку они стремятся сделать эти затраты настолько низкими, насколько это возможно.
Зачем усложнять работу Google, генерируя контент страниц с помощью JavaScript (на стороне клиента), тем самым увеличивая вычислительные затраты Google на сканирование ваших веб-страниц?
По этой причине, когда это возможно, вам следует придерживаться HTML.
Таким образом, вы не ухудшите свои шансы при использовании любого сканера.
4. Улучшите скорость страницы
Гугл говорит:
Процесс сканирования Google ограничивается такими факторами, как пропускная способность, время и количество доступных экземпляров Googlebot. Обеспечив быструю обработку запросов вашим сервером, вы сможете обеспечить более полное сканирование страниц вашего веб-сайта Google.
Использование рендеринга на стороне сервера действительно является разумным шагом для повышения скорости загрузки страницы, однако крайне важно убедиться, что ваши основные веб-показатели точно настроены, особенно время ответа сервера.
5. Позаботьтесь о своих внутренних ссылках
Когда Google сканирует веб-страницу, он определяет уникальные URL-адреса внутри нее, рассматривая каждый отдельный URL-адрес как отдельный объект или страницу, которая индивидуально индексируется сканерами поисковой системы.
Чтобы обеспечить единообразие на вашем сайте, направьте все внутренние ссылки в навигации (и в других местах) на версию вашей веб-страницы с «www». Это особенно актуально при ссылках на страницы, которые также доступны без www. Другими словами, если к странице можно получить доступ и как «www.example.com», и как «example.com», убедитесь, что они указывают друг на друга, причем одна из них является версией «www», а другая — ее аналогом.
Частой ошибкой, на которую следует обратить внимание, является забывание включить закрывающую косую черту в URL-адреса. Чтобы обеспечить согласованность, всегда не забывайте добавлять косую черту как к внешним, так и к внутренним URL-адресам, которые вы используете.
//www.example.com/sample-page» на «https://www.example.com/sample-page/» может предотвратить двойное сканирование одного URL-адреса. Это связано с тем, что поисковые системы могут рассматривать две версии как отдельные URL-адреса и сканировать их отдельно.
Важно помнить, что на ваших веб-страницах нет неработающих внутренних ссылок, поскольку они могут потреблять ваш краулинговый бюджет и приводить к ошибкам 404. Проще говоря, важно убедиться, что все ссылки на вашем сайте ведут на рабочие страницы, чтобы не тратить зря время поисковых ботов и не разочаровывать пользователей.
И если этого было недостаточно, они еще и навредили вашему пользовательскому опыту!
В данном случае я опять же за использование инструмента для аудита сайта.
Эти инструменты — WebSite Auditor, Screaming Frog, Lumar, Oncrawl и SE Ranking — являются отличными вариантами для проведения тщательного анализа или аудита веб-сайтов.
6. Обновите карту сайта
Опять же, позаботиться о вашей XML-карте сайта — это действительно беспроигрышный вариант.
Ботам будет намного лучше и легче понять, куда ведут внутренние ссылки.
Используйте только те URL-адреса, которые являются каноническими для вашей карты сайта.
Также убедитесь, что он соответствует последней загруженной версии robots.txt и загружается быстро.
7. Внедрите код состояния 304.
Как эксперт по SEO, я бы объяснил, что когда робот Googlebot посещает веб-страницу (URL), он включает заголовок «If-Modified-Since» с датой последнего посещения этой конкретной страницы. Эта дополнительная информация помогает системе определить, был ли обновлен контент с момента предыдущего сканирования.
Если содержимое вашей веб-страницы не изменилось с даты, указанной в «If-Modified-Since», вы можете ответить кодом состояния «304 Not Modified», не предоставляя никаких новых данных. Это указывает поисковым системам, что содержимое страницы не было обновлено, что позволяет роботу Googlebot использовать ранее сохраненную версию при следующем посещении.
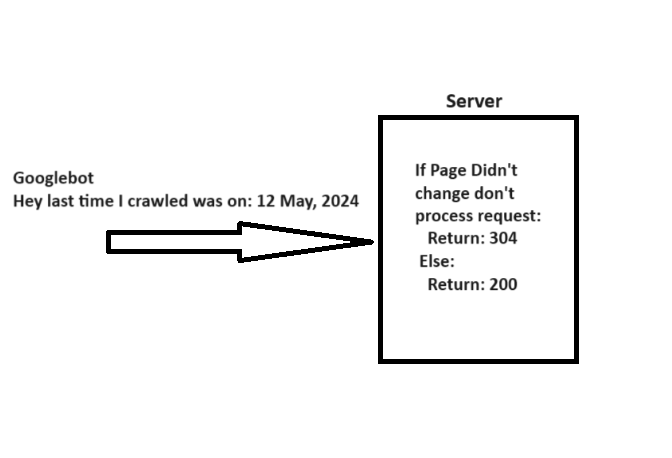
Однако при реализации кода состояния 304 есть предостережение, на которое указал Гэри Иллис.
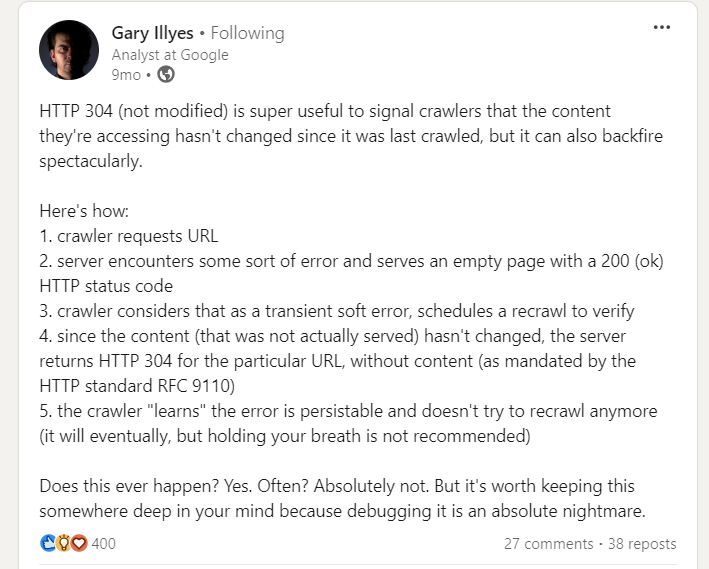
Будьте осторожны: пустые страницы, возвращаемые серверами со статусом 200 в результате ошибок сервера, могут помешать веб-сканерам повторно посещать их, что потенциально может вызвать постоянные проблемы при индексации сайта.
8. Теги Hreflang жизненно важны
Чтобы анализировать различные версии ваших веб-страниц, адаптированные для конкретных регионов, важно использовать теги hreflang. Таким образом, вы можете эффективно информировать Google о различных локализованных версиях ваших страниц.
Первоначально обязательно включите в заголовок вашей веб-страницы следующее:
Чтобы указать конкретный URL-адрес, рекомендуется использовать элемент «
9. Мониторинг и обслуживание
Чтобы следить за необычными действиями сканирования и устранять возможные проблемы, регулярно просматривайте журналы своего сервера и отчет «Статистика сканирования» в консоли поиска Google.
В большинстве случаев, если вы наблюдаете повторяющиеся всплески ошибок 404, это либо связано с проблемой бесконечных областей сканирования сайта (тема, которую мы рассматривали ранее), либо это может сигнализировать о других трудностях, с которыми может столкнуться ваш сайт.
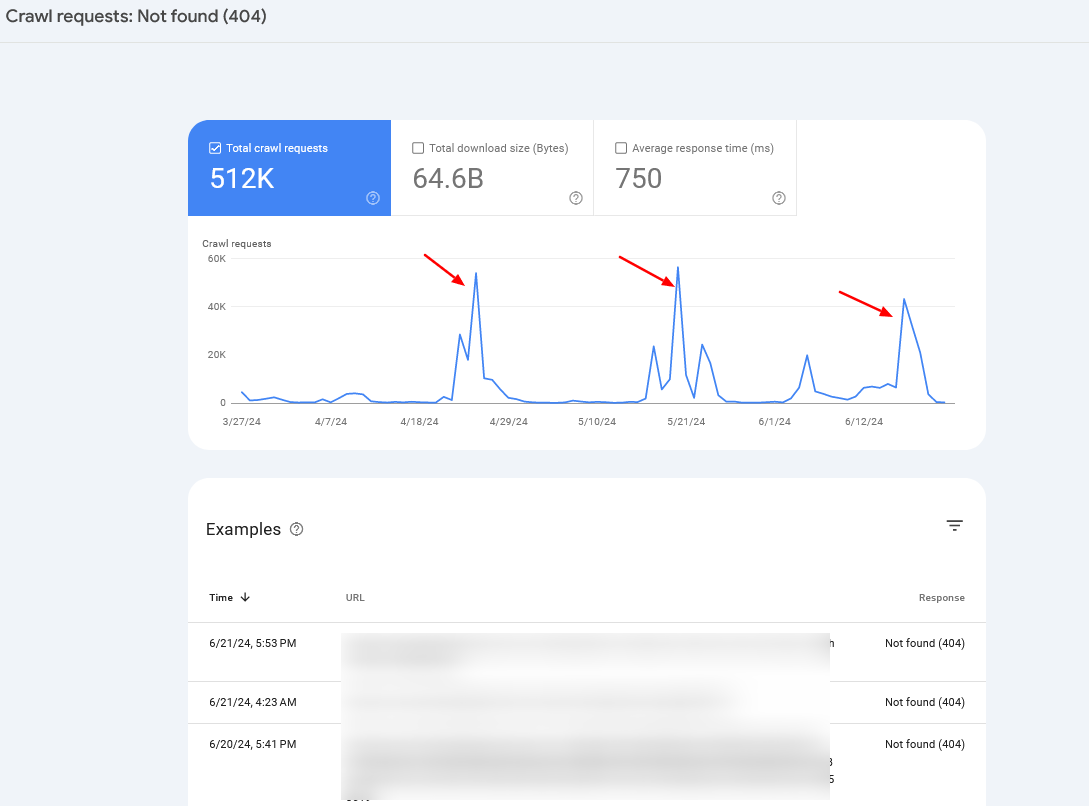
Зачастую вам может оказаться полезным объединить данные журналов сервера со статистикой Search Console, чтобы точно определить основную проблему.
Краткое содержание
Действительно, если вы размышляли над тем, остается ли оптимизация краулингового бюджета вашего сайта решающей, я могу вас заверить, что это определенно важно!
Понятие краулингового бюджета имеет решающее значение для каждого специалиста по SEO, который следует учитывать как сейчас, так и, вероятно, в будущем.
Вполне вероятно, что эти предложения помогут вам точно настроить бюджет сканирования и улучшить результаты SEO — просто имейте в виду, что сканирование поисковыми системами не означает, что ваши страницы будут автоматически проиндексированы.
Смотрите также
- Google: заманчиво оптимизировать показатели инструментов; Нет ярлыков для SEO
- e-pick: Ваши заветные карты ждут! 🎉
- TIA/USD
- Bing Поддерживает data-nosnippet для поисковых сниппетов и ответов ИИ.
- Публикации в Google Business Profiles Объединяют изображения, улучшенные с помощью искусственного интеллекта
- Ваша стратегия SEO адаптирована к эпохе искусственного интеллекта? [Вебинар]
- ДжейПи Морган против Близнецы: Сказка о гигантах банковского дела и двойных нарушителях спокойствия 💸
- WordPress объявляет об AI Agent Skill для ускорения разработки
- 11 лучших книг по SEO, которые вам стоит прочитать
- Google Реклама API версии 18 уже доступна
2024-09-10 13:39