Держитесь за свои шляпы, друзья! World Liberty Financial (WLFI), крипто-венчура, о связи которой с президентом США Дональдом Трампом вы бы никогда не догадались, решила раздать 8,4 миллиона WLFI токенов на сумму 1,2 миллиона долларов ранним пользователям, присоединившимся к их программе лояльности USD1 stablecoin. Только представьте себе, целую кучу цифровых долларов, падающих с неба, как конфеты на параде! 🎉💸
Вот как это работает: если вы один из тех опытных трейдеров, которые присоединились к USD1 Points Program, запущенной, ну, около двух месяцев назад (вероятно, пока вы еще разбирались, что такое стейблкоин), вы накапливали баллы. Вы зарабатывали их, торгуя парами USD1 на партнерских биржах и поддерживая свои балансы в порядке. Это как крипто-эквивалент коллекционирования наклеек — только эти могут стоить чего-то! 📈💎
О, но подождите, — говорит World Liberty, — критерии для получения баллов и наград могут варьироваться в зависимости от правил биржи, конечно. Так что не расслабляйтесь слишком сильно, вам нужно проверить мелкий шрифт правил вашей биржи. 🧐
И где же приземлится airdrop? Что ж, вознаграждения будут распределены по шести биржам: Gate.io, KuCoin, LBank, HTX Global, Flipster и MEXC. Каждая биржа сама определит, кто что получит. Так что, держим кулачки, друзья, потому что здесь нет универсального шаблона! 🍪🚀
World Liberty расширит программу баллов (Да, правда!)
Но подождите, это еще не все! World Liberty планирует расширить эту волшебную программу начисления баллов. И когда они говорят «расширить», они имеют в виду добавление новых площадок, интеграцию с децентрализованными финансами и массу других способов заработка и обмена вознаграждений. Это как бесконечный шведский стол с крипто-угощениями — только никто не просит чаевые. 🤑🍽️
О, и если вы не следили за своим крипто-календарем, USD1, который обеспечен реальными долларами США и управляется BitGo, занимает шестое место среди крупнейших стейбкойнов в мире! С рыночной капитализацией в 2,94 миллиарда долларов (да, миллиард с буквой B), очевидно, что они делают что-то правильно. 📊💵
Ранее в этом году Эрик Трамп вскользь упомянул, что инвестиционная фирма из Абу-Даби, MGX, использует 1 USD для расчетов по инвестициям в размере 2 миллиардов долларов в Binance. Это знаменует собой первую институциональную инвестицию в биржу. Ну а почему бы и нет, верно? 🤷♂️💼
Сейчас, если вы проверяете цену WLFI и чувствуете себя немного… скептически, не паникуйте. Она торгуется по $0.14, снизившись на 0.5% за последние 24 часа. Но эй, это все еще не так плохо, как почти 70% падение с ее исторического максимума в $0.46 в сентябре. Так что, по сути, это крипто-американские горки, на которые мы все подписались. 🎢😅
Криптовалютная империя Трампа принесла прибыль более 1 миллиарда долларов.
И вот, финальный аккорд — крипто-империя Трампа принесла ошеломляющие $1 миллиард прибыли до налогообложения за последний год. Потому что, знаете ли, криптовалюта никогда не была просто о покупке Lamborghini, верно? Согласно сочному расследованию Financial Times, этот крипто-бум в основном благодаря World Liberty Financial. Они выручили $57.4 миллиона дохода только от этого небольшого предприятия. 🍾💰
Но подождите – есть еще кое-что! Доля семьи Трамп взлетела до 5 миллиардов долларов после недавнего разблокирования токенов. FT даже утверждает, что они заработали 550 миллионов долларов только от WLFI в этом году. Это как, что, достаточно, чтобы купить небольшую страну? 🇺🇸💸
И не думайте, что на этом всё заканчивается. Клан Трампа также имеет свои брендированные мемкоины — да, мемкоины — Official Trump (TRUMP) и Official Melania Meme (MELANIA), которые принесли им солидные $427 миллионов. Что дальше? Монета, которая превращается в кепку MAGA? Сделаем крипту великой снова! 😎🪙
Не стоит забывать о стейбкоине USD1 – этот цифровой самоцвет заработал внушительные $42 миллиона прибыли с апреля. Это целое состояние для того, кто, вероятно, даже не помнит, когда в последний раз использовал настоящие бумажные деньги. 💸🧾
С некоторой долей забавности и, возможно, с ноткой скептицизма, можно наблюдать за заявлениями г-на Роберта Кийосаки, джентльмена, ответственного за обучение публики добродетелям ‘Богатого папы’ и опасностям ‘Бедного папы’. Он заявляет – с уверенностью, которую можно было бы сохранить для идеально исполненного кантри-танца – что цифровая валюта, известная как Bitcoin, удвоится в цене в ближайший год! Можно только представить, какое волнение это должно вызвать в приличном обществе. ✨
Действительно, г-н Кийосаки отваживается предположить, что этот Bitcoin, эта самая современная из спекуляций, может подняться до поразительной высоты в $200,000. Сумма, которая, если будет реализована, безусловно позволит даме приобрести весьма красивый набор лент, а джентльмену — купить вполне достойное поместье… или, возможно, просто больше Bitcoin! 💸
Я думаю, что цена Bitcoin удвоится в этом году…. Возможно, достигнет максимума в $200k», — заявил он на самой публичной платформе — ‘публикации в социальных сетях’, как любят говорить молодые люди. Надеюсь, он посоветовался со своим финансовым консультантом, прежде чем делать такое смелое заявление, чтобы не оказаться в очень неловком положении. 🧐
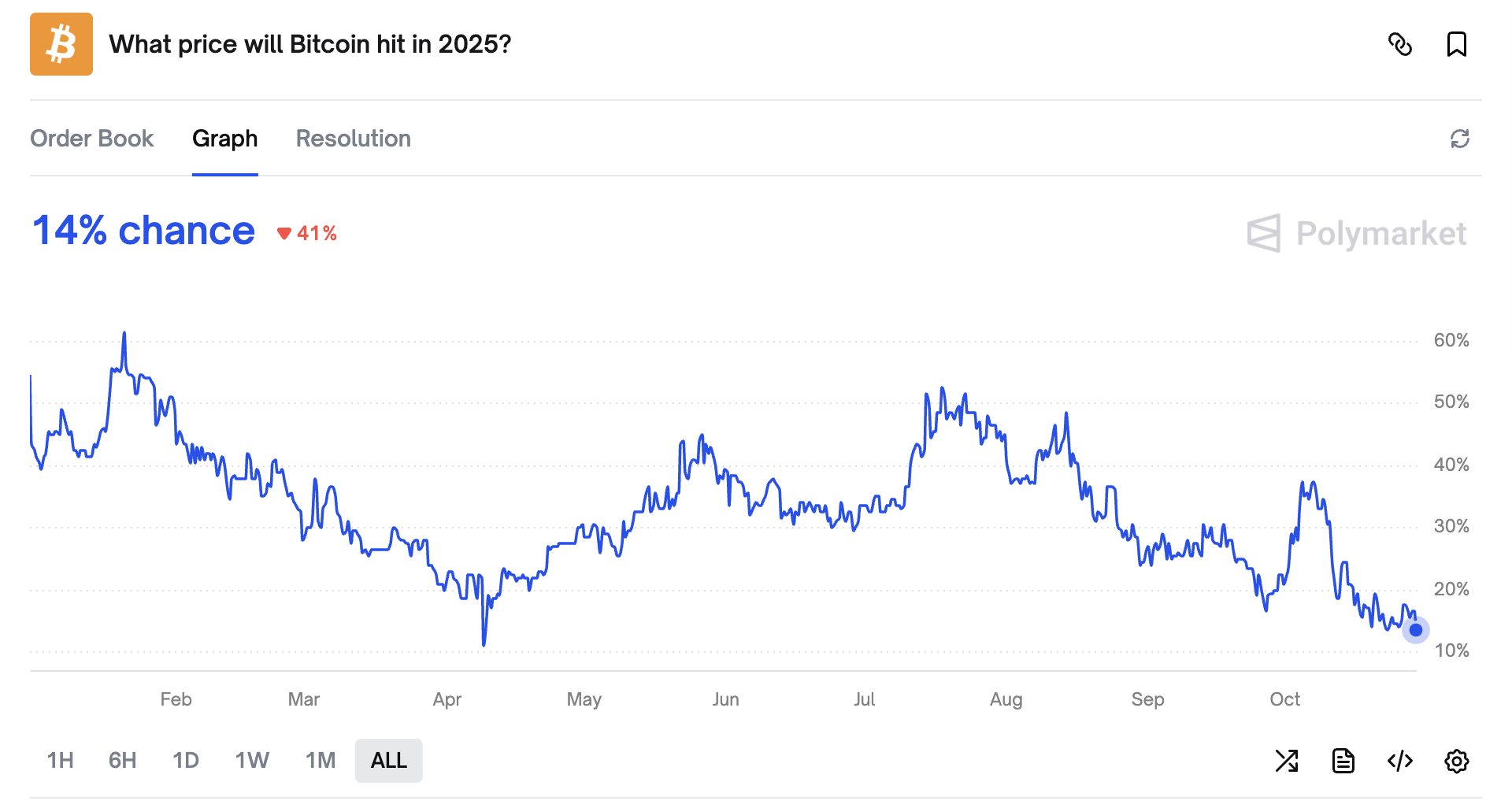
Текущая оценка этого Bitcoin, согласно тем, кто посвящает себя отслеживанию таких колебаний (довольно любопытное занятие, надо сказать), составляет значительные $113,108. Неплохая сумма, безусловно, хотя и значительно менее впечатляющая, чем упомянутые $200,000.
Различие во мнениях
Однако, похоже, не все поддались оптимизму г-на Кийосаки. Те, кто участвует в довольно современной форме ставок — ‘Polymarket’, как они это называют — присваивают лишь 2% вероятность реализации его предсказания. Такой мрачный прогноз! Заставляет задуматься, не прочитали ли эти игроки «Rich Dad Poor Dad». 🤷♀️
Действительно, шансы на то, что Bitcoin достигнет даже $150,000, оцениваются всего в 14%, что является существенным снижением по сравнению с 38%, которые наблюдались в начале месяца Октябрь. Кажется, этот ‘Uptober’ – довольно вульгарный термин, если вы спросите меня – оказался самым вопиющим разочарованием, и криптовалюта, похоже, обречена завершить месяц на явно неблагоприятной позиции.
В настоящее время Bitcoin снизился на 10.3% от своего пика в $126,080, зафиксированного 6 октября. Возможно, это поучительная история для тех, кто склонен полагаться на мимолетные удачи современной инновации. Можно предположить, что разумная инвестиция в землю остается гораздо более разумным курсом действий. 😎
Ваше традиционное SEO побеждает. Ваша AI-видимость терпит неудачу. Вот как это исправить.
Вы занимаете высокие позиции в Google, имеете сильное присутствие в сети по сравнению с конкурентами и стабильно наблюдаете рост органического трафика. Однако, когда люди обращаются к AI-чат-ботам, таким как ChatGPT или Perplexity, за информацией о вашей сфере, ваша компания не появляется в результатах.
Это разрыв в видимости ИИ, который приводит к упущенным возможностям в плане осведомленности и продаж.
Тот факт, что веб-сайт занимает высокие позиции в традиционных поисковых системах, не означает, что он будет заметно отображаться в поисковых системах на основе искусственного интеллекта. Акцент смещается с простого оптимизации контента на доказательство его точности и надежности.
Новый взгляд на то, как люди ищут информацию с помощью ИИ, показывает, что бренды, которые обычно занимают высокие позиции в Google, часто остаются незамеченными в результатах поиска на основе ИИ. Вместо этого, источники, такие как учебные заведения, отраслевые новостные сайты и веб-сайты, которые сравнивают продукты, последовательно отображаются, когда люди спрашивают о конкретных продуктах.
Ваш контент не является проблемой – проблема в том, как ИИ ранжирует информацию. ИИ сосредотачивается на понимании *смысла* поискового запроса, а не только ключевых слов. Он ценит проверенную экспертизу и четко организованные данные больше, чем маркетинговый шум или остроумное письмо.
Этот аудит выявляет 15 вопросов, которые отделяют бренды, невидимые для ИИ, от лидеров по цитированию.
Download the Full Audit
Вот первые 7 ключевых вопросов, которые помогут вам понять, где вы находитесь. Они сосредоточены на том, насколько хорошо вы видите, что происходит, подтверждаете, кто отвечает, и отслеживаете то, что имеет значение. Ответы на них быстро покажут, что требует внимания и какие шаги следует предпринять немедленно.
Вопрос 1: Видны ли мы в результатах поиска на основе искусственного интеллекта?
Многие известные бренды, занимающие высокие позиции в традиционных результатах поиска, удивительно сложно найти, когда люди задают вопросы инструментам искусственного интеллекта. Недавнее исследование IQuench показало, что менее 10% ответов, сгенерированных искусственным интеллектом, упоминают эти бренды, несмотря на их высокие позиции в поисковых системах. Вместо этого искусственный интеллект часто выделяет информацию из учебных заведений, отраслевых новостных источников и сравнительных веб-сайтов — даже если у этих коммерческих брендов более подробный и всесторонний контент. Эта проблема еще более остро стоит в отраслях со строгими правилами, поскольку эти правила ограничивают то, что бренды могут говорить, в то время как образовательные материалы свободно используются для обучения систем искусственного интеллекта.
Как проводить аудит:
Протестируйте основные запросы к продукту или услуге через несколько AI-платформ (ChatGPT, Perplexity, Claude)
Рассчитайте свой показатель видимости: запросы, в которых упоминается ваш бренд, по отношению к общему количеству протестированных запросов.
Добавьте ссылки на исследования и авторитетные цитаты к контенту продукта.
Создайте контент в формате FAQ с явной структурой вопрос-ответ.
Разверните структурированную разметку данных (Product, FAQ, Organization schemas)
IQRush отслеживает, как часто контент цитируется на AI-платформах. Анализируя вашу конкуренцию, он выявляет конкретные стратегии – такие как то, как они структурируют свой контент и укрепляют авторитет – которые помогают им получать цитирования, которые вы можете упускать.
Вопрос 2: Действительно ли наши заявления об опыте поддаются проверке?
Вот почему это важно: ИИ теперь полагается на проверяемые факты – такие как исследования, стандарты и официальные документы – при определении того, какие источники выделять. Пустые маркетинговые заявления, такие как утверждения о том, что вы ‘лидер отрасли’, не имеют значения. Недавний анализ одного из наших клиентов показал, что более 80% позитивных упоминаний бренда подкреплены надежными доказательствами. Многие компании преуспевают в создании привлекательного контента и сильного брендинга, но они часто упускают из виду структурированные данные, необходимые ИИ для признания их авторитета. Этот пробел объясняет, почему бренды с отличным традиционным маркетингом иногда испытывают трудности с тем, чтобы быть замеченными системами поиска и рекомендаций на базе ИИ.
Как проводить аудит:
Просмотрите ваши приоритетные страницы и определите каждое фактическое утверждение (статистика производительности, стандарты качества, описания методологии).
Рассчитать коэффициент проверки: утверждения с авторитетным подтверждением против общего количества сделанных фактических утверждений.
Действие: Для каждого неподтвержденного утверждения либо добавьте авторитетное подтверждение, либо удалите утверждение:
Добавьте конкретные цитаты к ключевым утверждениям (исследовательские базы данных, технические стандарты, отраслевые отчеты)
Свяжите технические спецификации с признанными организациями по стандартизации.
Включите детали сертификации или подтверждения соответствия, где это применимо.
Вопрос 3: Соответствует ли наш контент запросам пользователей в поисковых системах искусственного интеллекта?
Понимание *смысла*, стоящего за поисковыми запросами, сейчас важнее, чем простое повторение ключевых слов. Сайты, построенные с использованием устаревших стратегий ключевых слов, часто показывают плохие результаты в результатах поиска на основе искусственного интеллекта, потому что они не отвечают на вопросы так, как люди их задают. Например, страница, посвященная «лучшему программному обеспечению для управления проектами», может занимать высокие позиции в Google, но ИИ может игнорировать ее, если на странице не рассматриваются вопросы, такие как: «Какой инструмент управления проектами мне следует использовать для удаленной команды из 10 человек?» Недавние обзоры сайтов наших клиентов показывают, что видимость в ИИ варьируется в зависимости от отрасли — бренды, продающие продукты, часто фигурируют в ответах на вопросы, ориентированные на покупку, в то время как финансовые компании чаще появляются, когда люди ищут общую информацию. В конечном счете, то, покажет ли ИИ ваш контент, зависит от понимания *почему* люди ищут — они хотят узнать что-то новое, рассмотреть варианты или совершить покупку?
Как провести аудит:
Пример запросов, которые клиенты могли бы использовать в AI-движках для вашей категории продуктов.
Оцените, структурировано ли ваше содержание для типа намерения (информационное или транзакционное).
Оцените, использует ли контент разговорные языковые шаблоны по сравнению с традиционной ключевой оптимизацией.
Действие: Согласуйте контент с естественными вопросительными шаблонами и семантическим намерением:
Структурируйте контент, чтобы напрямую отвечать на вопросы, которые задают клиенты.
Создавайте контент для каждой стадии намерения: информационная (обучение), рассмотрение (сравнение), транзакционная (спецификации)
Используйте разговорные языковые шаблоны, которые соответствуют взаимодействиям с ИИ-движком.
Обеспечьте семантическую релевантность, выходящую за рамки простого сопоставления ключевых слов.
IQRush анализирует, насколько ваш контент соответствует тому, как люди на самом деле ищут информацию, используя ИИ, и выделяет пробелы между вашими страницами, ориентированными на ключевые слова, и тем, о чём пользователи *действительно* спрашивают.
Вопрос 4: Структурирована ли информация о нашем продукте для рекомендаций ИИ?
Рекомендации по продуктам основываются на чётких, организованных данных. Системы искусственного интеллекта анализируют детали, такие как спецификации, цены и характеристики, используя структурированные данные – часто называемые schema markup – вместо описательного текста. Продукты с полным schema markup гораздо более вероятно будут рекомендованы ИИ, когда люди ищут и сравнивают варианты. Фактически, поисковые запросы по конкретным продуктам или сравнения («best X for Y») почти полностью зависят от этих машиночитаемых данных.
Как провести аудит:
Проверьте, содержат ли страницы продуктов разметку схемы Product с полными спецификациями.
Проверьте, можно ли машинным способом считать технические детали (размеры, материалы, сертификаты, совместимость).
Протестируйте транзакционные запросы (сравнения продуктов, «лучший X для Y»), чтобы убедиться, что ваши продукты отображаются.
Оцените, структурирована ли информация о ценах, доступности и покупке.
Действие: Реализовать комплексную структуру данных продукта:
Развернуть схему продукта с полными техническими спецификациями.
Информация о сравнении структуры (таблицы, списки), которую ИИ может легко анализировать.
Включите точные измерения, сертификаты и сведения о совместимости.
Добавьте схему FAQ, отвечающую на распространенные вопросы о выборе продукта.
Убедитесь, что данные о ценах и наличии товара представлены в формате, пригодном для машинной обработки.
Аудит электронной коммерции от IQRush проверяет ваши страницы продуктов на наличие недостающей информации, такой как цена, наличие на складе, характеристики и отзывы. Затем он помогает исправить наиболее важные проблемы в первую очередь, сосредотачиваясь на терминах, которые люди ищут чаще всего в вашей продуктовой категории.
Вопрос 5: Действительно ли наш «Свежий» контент является свежим для AI-движков?
Поддержание актуальности контента важно для поисковой выдачи, но простого изменения даты публикации недостаточно. Хотя недавние даты являются положительным сигналом, страницы с устаревшей информацией фактически работают *хуже*, чем более старые страницы, которые были содержательно обновлены – например, добавление новых исследований, актуальных данных или пересмотренных деталей. Реальные улучшения контента имеют гораздо большее значение, чем просто повторная публикация с новой датой.
Как проводить аудит:
Проверьте, когда ваши приоритетные страницы были существенно обновлены (не только изменения временных меток).
Проверьте, ссылается ли контент на последние исследования, текущие отраслевые данные или обновленные стандарты.
Оцените, был ли обновлен «вечнозеленый» контент с использованием текущих примеров и информации.
Сравните свежесть вашего контента с контентом конкурентов, появляющихся в ответах ИИ.
Создавайте расписания обновлений для ключевых категорий контента
IQRush анализирует, насколько ваш контент актуален по сравнению с контентом ваших конкурентов, обращая внимание на такие вещи, как исследования и данные. Он определяет страницы, которые нуждаются в серьезной переработке с новой информацией, а также указывает на страницы, которым просто нужна свежая дата, чтобы выглядеть более актуальными.
Вопрос 6: Как мы измеряем то, что действительно работает?
Важно понимать, что стандартные SEO-меры, такие как рейтинги и трафик веб-сайта, не отражают, как ИИ влияет на клиентов. Когда бренды упоминаются в ответах ИИ (например, от чат-ботов), это может повлиять на решения о покупке, даже если никто не переходит по ссылке. Это похоже на то, как работает реклама для повышения узнаваемости бренда. Без отслеживания этих упоминаний ИИ, руководители маркетинга (CMO) не могут точно измерить возврат инвестиций, принимать разумные бюджетные решения или демонстрировать ценность своей работы руководству компании.
Как проводить аудит:
Просмотрите свои исполнительные информационные панели: Присутствуют ли метрики видимости ИИ наряду с SEO-метриками?
Изучите свои аналитические возможности: можете ли вы отслеживать, как частота цитирования меняется от месяца к месяцу?
Оцените конкурентную разведку: знаете ли вы свою долю цитирования относительно конкурентов?
Оцените охват: Какие категории запросов вы упускаете из виду?
Действие: Установить измерение цитирования ИИ:
Отслеживайте частоту цитирования основных запросов на платформах искусственного интеллекта.
Отслеживайте долю конкурентных упоминаний и изменения позиций.
Измеряйте настроения и точность упоминаний бренда.
Добавьте метрики видимости ИИ на исполнительные панели.
Соотнесите видимость ИИ с показателями рассмотрения и конверсии.
IQRush отслеживает частоту цитирования контента, анализирует производительность конкурентов и выявляет ежемесячные тенденции на платформах искусственного интеллекта – и всё это без необходимости ручного тестирования или создания пользовательских аналитических инструментов.
Вопрос 7: Где находятся наши самые большие пробелы в видимости?
Бренды обычно появляются в результатах поиска лишь для небольшой доли релевантных запросов, и это сильно варьируется в зависимости от того, на каком этапе покупательского пути находится клиент и какой это продукт. Наш анализ в IQRush показал, что потребительские бренды, как правило, появляются тогда, когда люди готовы к покупке, в то время как сервисные компании в основном показываются, когда люди только узнают о чем-то. В большинстве случаев бренды вообще не видны, когда клиенты что-то ищут. Улучшая видимость в эти ключевые моменты, бренды могут охватить больше потенциальных клиентов и получить преимущество перед конкурентами.
Как проводить аудит:
Список запросов, которые клиенты могут задать о ваших продуктах/услугах на разных этапах воронки продаж.
Сгруппируйте их по этапам воронки продаж (информационный, рассмотрение, транзакционный).
Проверьте каждый запрос на AI-платформах и задокументируйте: Появляется ли ваш бренд?
Вычислите, какой процент запросов приводит к упоминаниям брендов на каждом этапе воронки.
Выявляйте закономерности в запросах, где вас нет.
Действие: Сначала нацельтесь на этапы воронки продаж с наименьшей видимостью:
Если слабо в информационной стадии: Создавайте образовательный контент, отвечающий на запросы «что такое» и «как это работает».
Если испытываете затруднения на этапе рассмотрения: Создавайте сравнительный контент, структурированный в виде таблиц или сопоставленных схем.
Если слабые показатели на транзакционной стадии: добавьте полные спецификации продукта с использованием схемы разметки.
Анализ воронки от IQRush помогает вам точно определить, где потенциальные клиенты отваливаются, и насколько велики эти пробелы. Он также предсказывает, какие улучшения контента быстро принесут наибольшую новую видимость.
Совокупное преимущество ранних действий
Первые семь вопросов и шагов демонстрируют, чем традиционный успех в SEO отличается от видимости в результатах поиска на базе искусственного интеллекта. Они проясняют, почему бренды, занимающие высокие позиции в стандартном поиске, могут не отображаться в ответах, сгенерированных искусственным интеллектом.
После первоначальной оценки я перехожу к более глубокому анализу с помощью 8 дополнительных вопросов. Они действительно углубляются в детали того, как работает ваш веб-сайт – такие вещи, как организация контента, базовые технологии, обеспечивающие бесперебойную работу всего, и насколько хорошо вы используете семантическую разметку, чтобы показать поисковым системам – и ИИ – что вы являетесь настоящим экспертом в своей области. Речь идет о создании прочного фундамента для долгосрочного маркетингового успеха.
Как SEO-эксперт, я наблюдаю огромный сдвиг с появлением поисковых систем на базе ИИ. Речь идет не только о ранжировании; видимость фактически *усиливается* – это означает, что чем чаще вас находят, тем легче становится, и тем сложнее это становится для ваших конкурентов. Радж Сапру из Netrush точно подмечает: бренды, которые сейчас сосредотачиваются на том, чтобы их контент был легко понятен ИИ, будут доминировать в поисковом пространстве в будущем. Речь идет о подготовке к машинному чтению сегодня, чтобы победить завтра.
Возможность стать первопроходцем и закрепить присутствие вашего бренда с помощью ИИ не продлится долго. По мере того, как все больше компаний сосредотачиваются на видимости ИИ, конкуренция растет.
Получите нашу бесплатную проверку видимости в AI-поиске, чтобы узнать, насколько хорошо ваш веб-сайт позиционирован для поиска на базе искусственного интеллекта. Она включает в себя простые в использовании контрольные списки и структуры, а также 8 ключевых вопросов, охватывающих ваш контент, веб-технологии и использование языка. Вы получите четкие шаги для выявления и устранения слабых мест, помогая вам выделиться среди конкурентов, которые также оптимизируются для AI.
Недавнее исследование, проведенное IAB и Talk Shoppe, показывает, что ИИ ускоряет исследования и процесс сравнения вариантов, но он не является заменой человеческому суждению.
Вот основные моменты, прежде чем мы перейдем к деталям:
Искусственный интеллект подталкивает людей к проверке деталей на сайтах розничных продавцов, в поисковых системах, обзорах и на форумах, вместо того чтобы заменять эти шаги.
Только около половины полностью доверяют рекомендациям ИИ, что создает предсказуемые отклонения, когда ссылки не работают или характеристики и цены не совпадают.
Посещаемость розничных магазинов растет после внедрения ИИ, при этом каждый третий покупатель переходит по ссылке напрямую из ассистента.
О Отчете
Этот отчёт объединяет реальное покупательское поведение – зафиксированное более чем в 450 записанных сеансах ИИ – с данными, полученными в результате опроса 600 потребителей из США. Он предоставляет как то, что люди *делают*, так и то, что они *говорят* о покупках.
Он отслеживает, где помогает ИИ, где нарушается доверие и что люди делают дальше.
Ключевые выводы
Искусственный интеллект может ускорить исследования и помочь людям сосредоточиться на самом важном, особенно при взвешивании различных вариантов. Однако он часто требует дополнительных усилий от покупателей, чтобы перепроверить информацию из других источников.
Во время сессий участники в среднем делали 1,6 шага перед использованием ИИ и 3,8 шага после. Почти все – 95% – делали дополнительные шаги, чтобы перепроверить свою работу и убедиться, прежде чем завершить.
Как цифровой маркетолог, я анализировал, куда клиенты на самом деле идут, чтобы подтвердить информацию, которую они находят с помощью инструментов на базе ИИ. Мы видим, что большинство покупателей – около 78% – направляются на сайты розничной торговли или онлайн-маркетплейсы как часть своих исследований. Интересно, что значительные 32% из них переходят непосредственно из ИИ-инструмента на эти сайты, что показывает четкую связь между поиском на основе ИИ и немедленным потенциалом покупки.
После внедрения ИИ количество посетителей сайтов розничных продавцов удвоилось, увеличившись с 20% до 50%. Эти посетители в основном интересовались проверкой цен, поиском различных вариантов, чтением отзывов и подтверждением наличия товара.
Низкое доверие к рекомендациям ИИ
Доверие — это ограничение. Только 46% полностью доверяют рекомендациям по покупкам, сделанным ИИ.
Общие точки трения, где люди теряли доверие, были:
Несоответствующие характеристики или цены
Устаревшая доступность
Рекомендации, которые не соответствовали бюджету или требованиям совместимости
Эти проблемные моменты заставили людей вернуться к поиску, ритейлерам, обзорам и форумам.
Почему это важно
AI чат-боты теперь формируют исследования mid-journey.
Если информация о ваших продуктах – например, детали, сравнения и обзоры – не соответствует тому, что покупатели находят на сайтах розничных продавцов, они быстро обнаружат несоответствие.
Это подчёркивает необходимость согласованности деталей на всех каналах, чтобы сохранить доверие клиентов.
Что делать с этой информацией?
Вот конкретные шаги, которые вы можете предпринять, основываясь на информации из отчета:
Поддерживайте синхронизацию спецификаций, цен, доступности и вариантов с данными поставщиков.
Создавайте страницы сравнения и «альтернатив», основываясь на атрибутах, которые пользователи запрашивают.
Расширьте структурированные данные для спецификаций, вариантов, доступности и обзоров.
Создавайте контент, чтобы отвечать на распространенные возражения, возникающие на форумах и в комментариях.
Отслеживайте запросы и сообщества, где покупатели проверяют информацию, чтобы устранить повторяющиеся пробелы.
Заглядывая в будущее
Искусственный интеллект продолжит играть большую роль в том, как люди находят продукты, но в конечном итоге покупатели по-прежнему будут полагаться на веб-сайты розничных продавцов и брендов, чтобы получить конкретную информацию, необходимую им перед совершением покупки.
Для получения более подробной информации о том, как ИИ влияет на процесс покупок, ознакомьтесь с полным отчётом.
Figment, гуру стейкинга, решил, что Coinbase – это больше не только для вашего утреннего кофе! ☕ Последний ход дуэта позволяет крупным инвесторам стейкать огромное разнообразие активов proof-of-stake (PoS) прямо из Coinbase Custody – потому что Ethereum был явно слишком мейнстрим. 🤷♀️
Клиенты Coinbase Prime теперь могут продемонстрировать свои возможности стейкинга с Solana (SOL), Sui (SUI), Aptos (APT), Avalanche (AVAX) и другими. Это как крипто-версия шведского стола – просто не переусердствуйте и не обрушьте сеть. 🃏
С 2023 года это партнерство уже заблокировало $2 миллиарда в застейканных активах. Изысканно! 🎩
Coinbase Prime? Это VIP-зал криптовалют, предлагающий торговлю, финансирование и хранение более 440 цифровых активов. Честно говоря, больше, чем просто список покупок в продуктовом магазине. 🛒
Figment, между тем, владеет активами в залоге на сумму $18 миллиардов через 40 протоколов. Кому-нибудь пора вызвать финансового терапевта! 💸
Тем временем, в мире криптовалют… США получили свои ETF для стейкинга! BSOL от Bitwise – новый игрок на рынке, а Grayscale осуществляет стейкинг $150 миллионов ETH. Зачем же не превратить свою криптовалюту в денежное дерево? 🌳💰
SEC наконец-то отступила и заявила: «На самом деле, стейкинг не является преступлением в сфере ценных бумаг.» Фух! Председатель Пол Аткинс назвал это «значительным шагом» — кодовая фраза для «мы все еще в замешательстве, но делаем вид, что нет». 😅