Как человек, который годами создаёт и дорабатывает веб-сайты, я внимательно слежу за тем, как люди используют наш поиск на основе искусственного интеллекта. На прошлой неделе я опубликовал результаты действительно всестороннего исследования удобства использования – самого масштабного, которое мы проводили для этого нового ‘AI Mode‘, – и оно дало нам несколько интересных выводов о том, как пользователи фактически с ним взаимодействуют.
Они сосредотачиваются на тексте режима ИИ в 88% случаев, игнорируют иконки ссылок и редко переходят по ним.
Вторая часть этой недели посвящена тому, что мы можем отслеживать с помощью данных, что мы оцениваем и что может произойти дальше в отношении того, как AI Mode влияет на видимость, укрепляет доверие и генерирует доход.
Чтобы узнать больше о том, как мы проводили наши исследования и что мы обнаружили о том, как люди используют поиск на основе искусственного интеллекта, пожалуйста, прочитайте наш отчет, ‘Что наше исследование поведения пользователей режима AI раскрывает о будущем поиска’.
Потому что на этой неделе мы сразу же окунаемся в процесс.
Какие элементы режима ИИ вы можете «оптимизировать» для?
Прежде чем поделиться дополнительными выводами из прошлой недели, давайте быстро обсудим, как ваш бренд может использовать возможности с помощью ИИ.
Существует несколько различных возможностей видимости, каждая из которых имеет разные функции:
- Встроенные текстовые ссылки или встроенные ссылки: Гиперссылка непосредственно в тексте, генерируемом AI Mode, которая открывает функцию на боковой панели для изучения пользователем; крайне редко встроенная текстовая ссылка в AI Mode может открыть внешнюю страницу в новой вкладке.
- Значки ссылок: Серое изображение ссылки, которое отображает цитаты в правой боковой панели.
- Боковая панель/боковая панель с цитированием: Список внешних ссылок (с миниатюрой изображения), из которых AI Mode берет информацию; отображается в правой колонке. Иконка ссылки «перемешивает» этот список при нажатии.
- Пакеты предложений: Они выглядят как карусели предложений в классическом органическом поиске и отображаются в левой панели в текстовом выводе AI Mode.
- Локальные пакеты: Это аналогично локальным пакетам, сопоставленным со встроенной картой в классическом органическом поиске, и они отображаются в левой панели в текстовом выводе AI Mode (очень похоже на Shopping packs выше).
- Карта продавца: После выбора в наборе покупок открывается карта продавца для дальнейшего изучения.
- Карточка Google Business Profile (GBP): Она появляется справа при нажатии на карточку продавца из локального пакета. После нажатия карточка GBP открывается для дальнейшего изучения.
- Встраиваемая карта: Встроенная локальная карта, отображающая решения запроса/поиска в данной области.
Мы провели исследование удобства использования с 37 участниками, чтобы понять, как люди используют наш AI Mode. Они выполнили 250 различных поисковых заданий, предоставив нам ценную информацию о том, как пользователи взаимодействуют с его различными функциями.
Наш анализ показал, что не все возможности для повышения видимости одинаково эффективны, и самые выгодные из них могут вас удивить.
Честно говоря, у меня пока нет полного руководства о том, как попасть в эти новые опции AI Mode. Но я активно изучаю и исследую, поскольку AI Mode становится доступен большему количеству пользователей и моих клиентов, и я поделюсь тем, что узнаю.
На данный момент ни у кого из нас нет достаточной информации, чтобы с уверенностью сказать, какие конкретные стратегии будут последовательно помогать веб-сайтам быть найденными в новых поисковых системах, работающих на базе AI-чатботов.
По сути, сильный SEO и создание авторитетного бренда помогают улучшить видимость вашего контента в поисковых системах с использованием искусственного интеллекта и в AI-режимах.
Доверие к бренду является фактором №1, влияющим на AI Mode.
Я постоянно подчёркиваю, что доверие к бренду и авторитет невероятно важны в эпоху AI-функций, таких как AI Mode и Overviews, и это потому, что многие люди упускают из виду этот момент.
Как и моё UX-исследование AI Overviews, проведённое в мае 2025 года, моё недавнее исследование AI Mode—опубликованное на прошлой неделе—показывает то же самое:
Если AI Mode — это игра на влияние, то доверие оказывает наибольшее влияние на решения пользователей.
Чтобы добиться успеха, вам нужно убедиться, что люди доверяют вашему бренду и что он появляется, когда люди используют инструменты с искусственным интеллектом и осуществляют поиск.
Я объясню.
Участники исследования выполнили следующие семь задач:
- Что говорят люди о Liquid Death, компании-производителе напитков? Нравятся ли вам их напитки?
- Представьте, что вы собираетесь купить трекер сна, и доступны только два варианта: Oura Ring 3 или Apple Watch 9. Какой бы вы выбрали и почему?
- Вы получаете информацию о преимуществах кредитной карты Ramp по сравнению с Brex Card для малого бизнеса. Какая из них кажется лучше? Что заставило бы бизнес перейти на другую карту: детали комиссий, условия участия или вознаграждения?
- В поле «Спроси что угодно» в режиме AI введите «Помоги мне купить водонепроницаемую холщовую сумку». Выберите ту, которая лучше всего соответствует вашим потребностям и которую бы вы купили (например, сумку для фотоаппарата, сумку-тоут, дорожную сумку и т.д.).
- Перейдите на страницу продавца. Нажмите, чтобы добавить в корзину и завершите эту задачу, не продвигаясь дальше.
- Сравните приложения для изучения языков по подписке со бесплатными приложениями. Готовы ли вы платить и в какой ситуации? Какой продукт вы бы выбрали?
- Предположим, вы навещаете друга в большом городе и хотите пойти либо: 1. В виртуальный аркадный зал ИЛИ 2. В выставочный зал умного дома. Как называется город, который вы посещаете?
- Предположим, вы работаете за небольшим столом, и ваши кабели в беспорядке. В поле «Задайте любой вопрос» в режиме AI введите: «Провода от устройств загромождают моё рабочее пространство. Что я могу купить сегодня, чтобы помочь?» Затем выберите один продукт, который, по вашему мнению, является лучшим решением. Поместите его в корзину на внешнем веб-сайте и завершите эту задачу.
Посмотрите на эти цитаты от пользователей, когда они принимали решения о покупке:
За исключением базовых товаров, где люди в основном выбирают, исходя из стоимости и наличия на складе, репутация бренда действительно важна для клиентов.
Ответы людей сильно зависели от того, насколько хорошо они знали продукт и насколько сложным, по их мнению, было его использование.
Использование повседневных предметов, таких как кабельные стяжки или сумки-шопперы, помогло людям полагаться на то, что они уже знали, позволяя им легко принимать решения, даже когда ИИ не предоставлял чётких указаний.
Когда люди сталкивались с новыми или менее конкретными категориями продуктов – такими как консервированная вода, программы изучения языков или различные варианты обработки платежей – они гораздо охотнее придерживались брендов, которые уже знали.
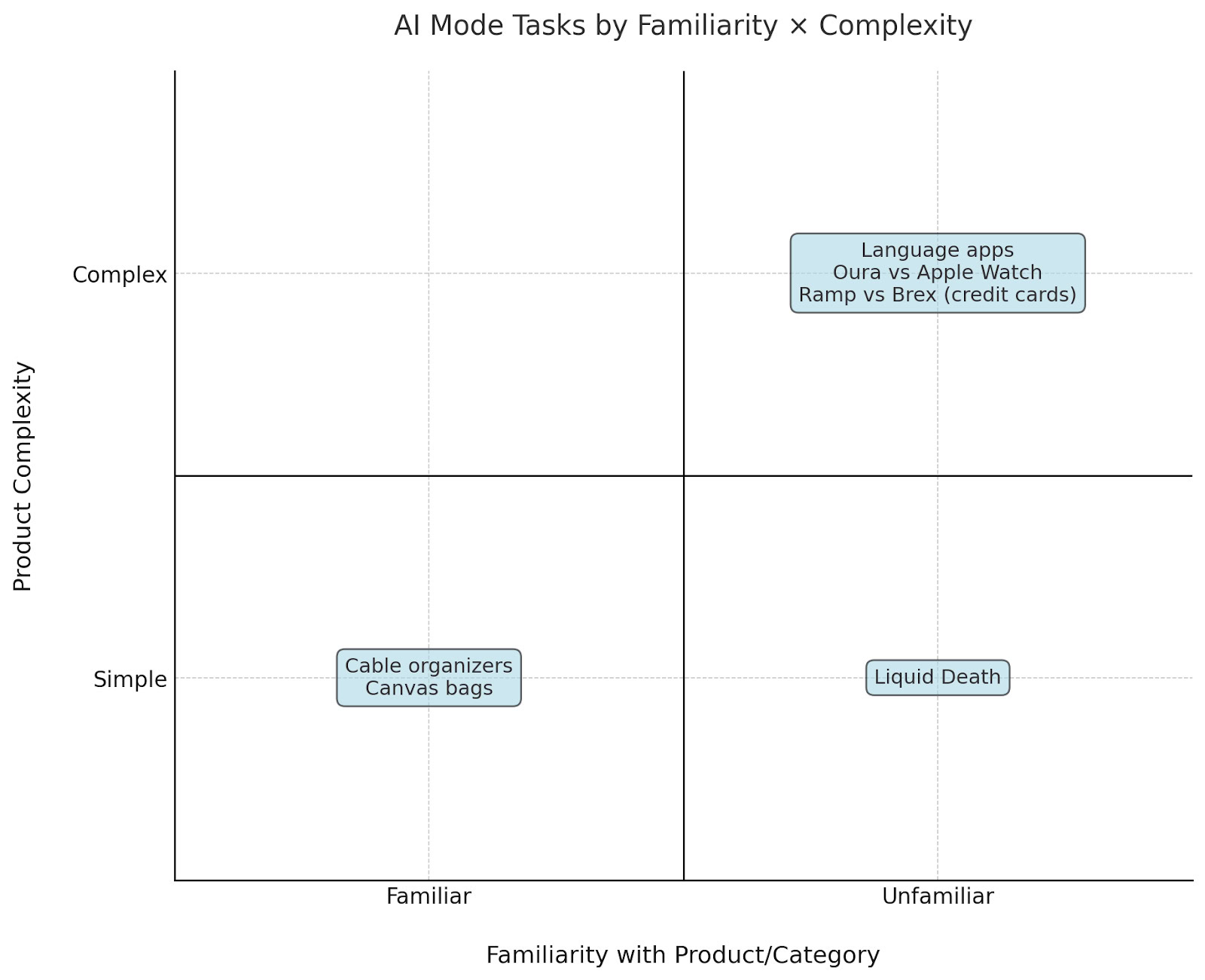
Наше недавнее исследование о том, как люди используют наш ИИ, показало, что если покупатели не узнают бренд, они, как правило, переходят на онлайн-маркетплейсы – или продолжают изучать предоставленную информацию.
Когда участники просматривали результаты AI Mode, большинство из них – около 89% (221 из 248) – сразу же сосредоточились и взаимодействовали с текстом, сгенерированным AI.
Это нельзя подчеркнуть достаточно.
AI-сгенерированный текст гораздо более вероятно привлечет чье-либо внимание, чем любые изображения или другие визуальные элементы.
Встроенные текстовые ссылки Бьют иконки ссылок.
Недавно VP Product Search в Google, Робби Штайн, сказал в X:
Мы можем подтвердить, почему Google сделала этот выбор, используя данные.
Но прежде чем вы погрузитесь в текст ниже, вот некоторая дополнительная информация:
- Встроенные текстовые ссылки – это то, что мы называем фактическими гиперссылками URL внутри копии AI Mode, о чём говорит Робби Штайн в своей цитате выше.
- Серый значок ссылки, над которым наводят пользователи, мы называем (в этом исследовании) значком ссылки.
- Богатый сниппет на правой стороне режима ИИ — это то, что мы называем боковой панелью или сайдом.
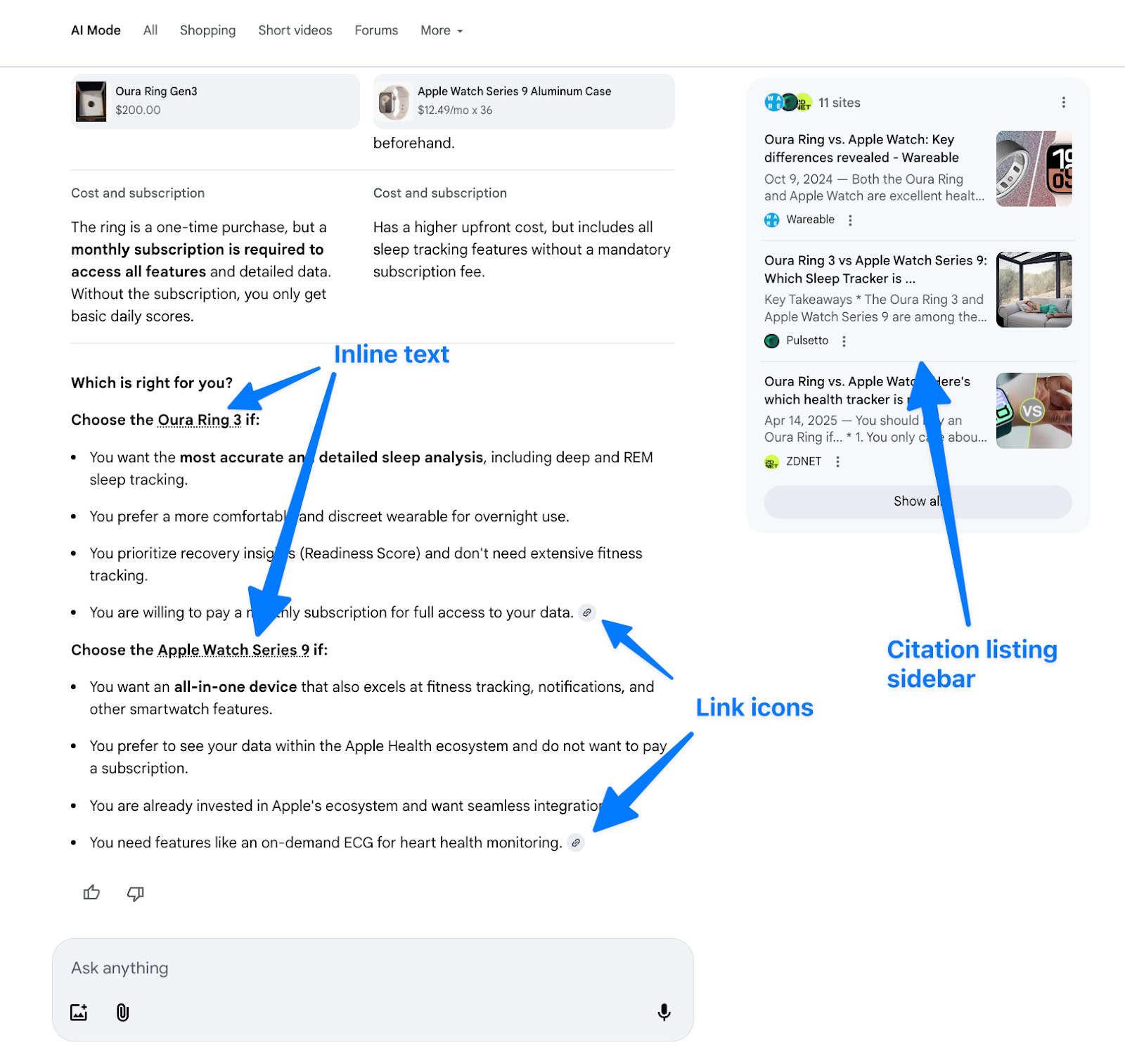
Мы обнаружили, что встроенные текстовые ссылки получают примерно на 27% больше кликов, чем правая боковая панель цитирований.
Ссылки, встроенные непосредственно в текст, кажутся более естественными, поскольку они являются частью того, что люди уже читают. Иконки ссылок, с другой стороны, могут казаться отдельными и требовать от пользователей переключения внимания. Большинство людей привыкли нажимать на текст или кнопки для навигации, а не на иконки.
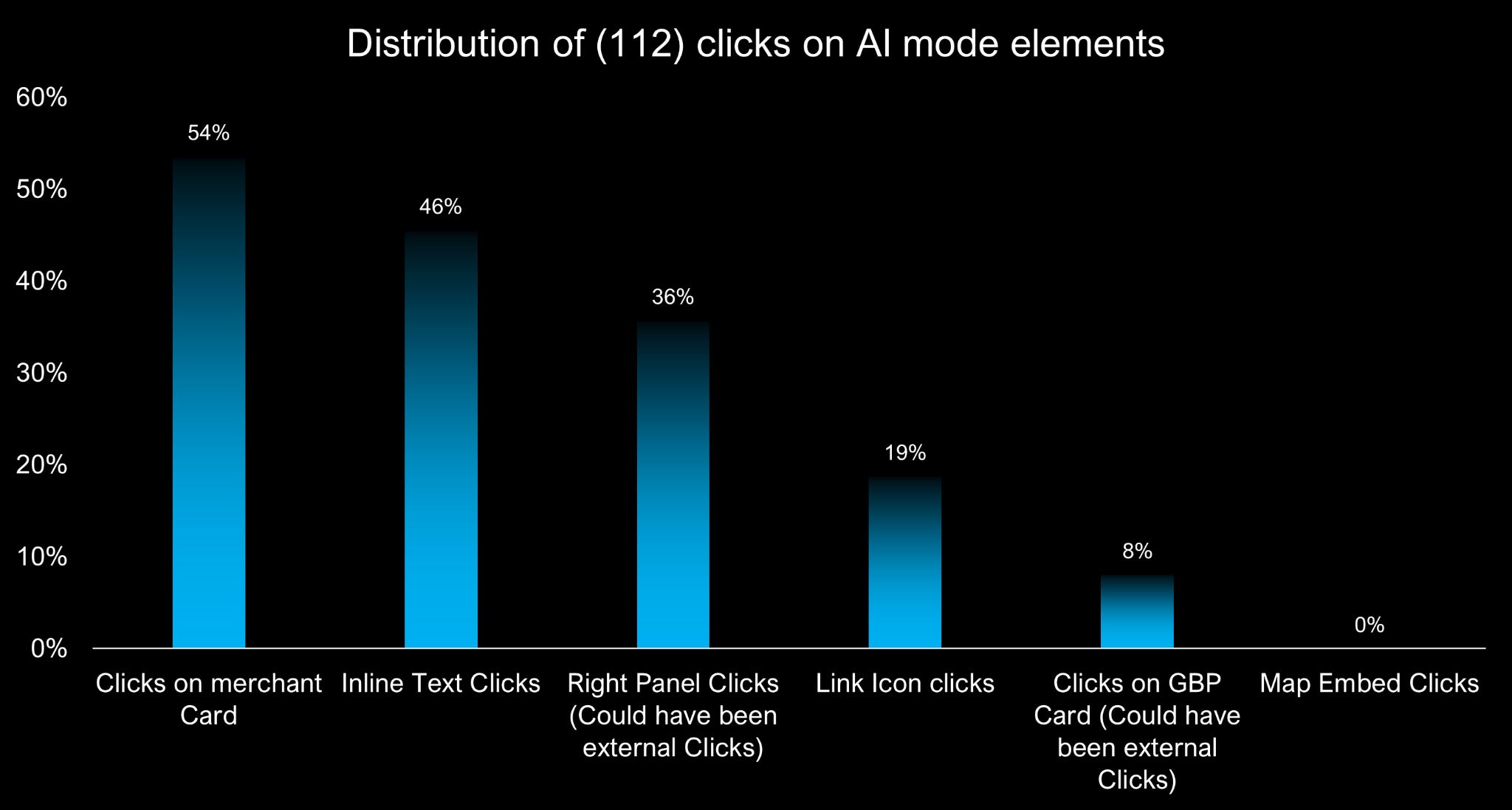
Это важно, потому что если Google начнет автоматически включать ссылки в свои ответы, сгенерированные ИИ, это может привести к тому, что больше людей будут переходить по этим ссылкам.
Главный вывод из этого?
Ссылка, которая просто упоминает ваш сайт, не так полезна, как ссылка, где ваш сайт напрямую связан в основном тексте статьи или публикации.
Стоит отметить, что некоторые SEO-специалисты и маркетологи могут считать, что появление в цитатах предпросмотра ссылок дает преимущества их брендам или клиентам. Однако, это не обязательно так.
Безусловно, ценно получать видимость через результаты поиска в наши дни. Однако, наше недавнее исследование удобства использования показывает, что упоминание в ссылке, вероятно, не влияет на поведение посетителей. Поэтому, хорошей идеей будет исправить это недопонимание внутри нашей индустрии и с нашими клиентами.
Локальные пакеты, карты и GBP-карты требуют больше данных.
Ещё одна интересная находка?
В нашем исследовании Local Pack появлялся только примерно в 9,6% случаев выполненных участниками задач. Карта Google Business Profile, отображающая информацию о компаниях, редко была видна в ходе тестирования.
Только 3% поисковых запросов в рамках исследования показали наличие карты GBP в какой-либо форме.
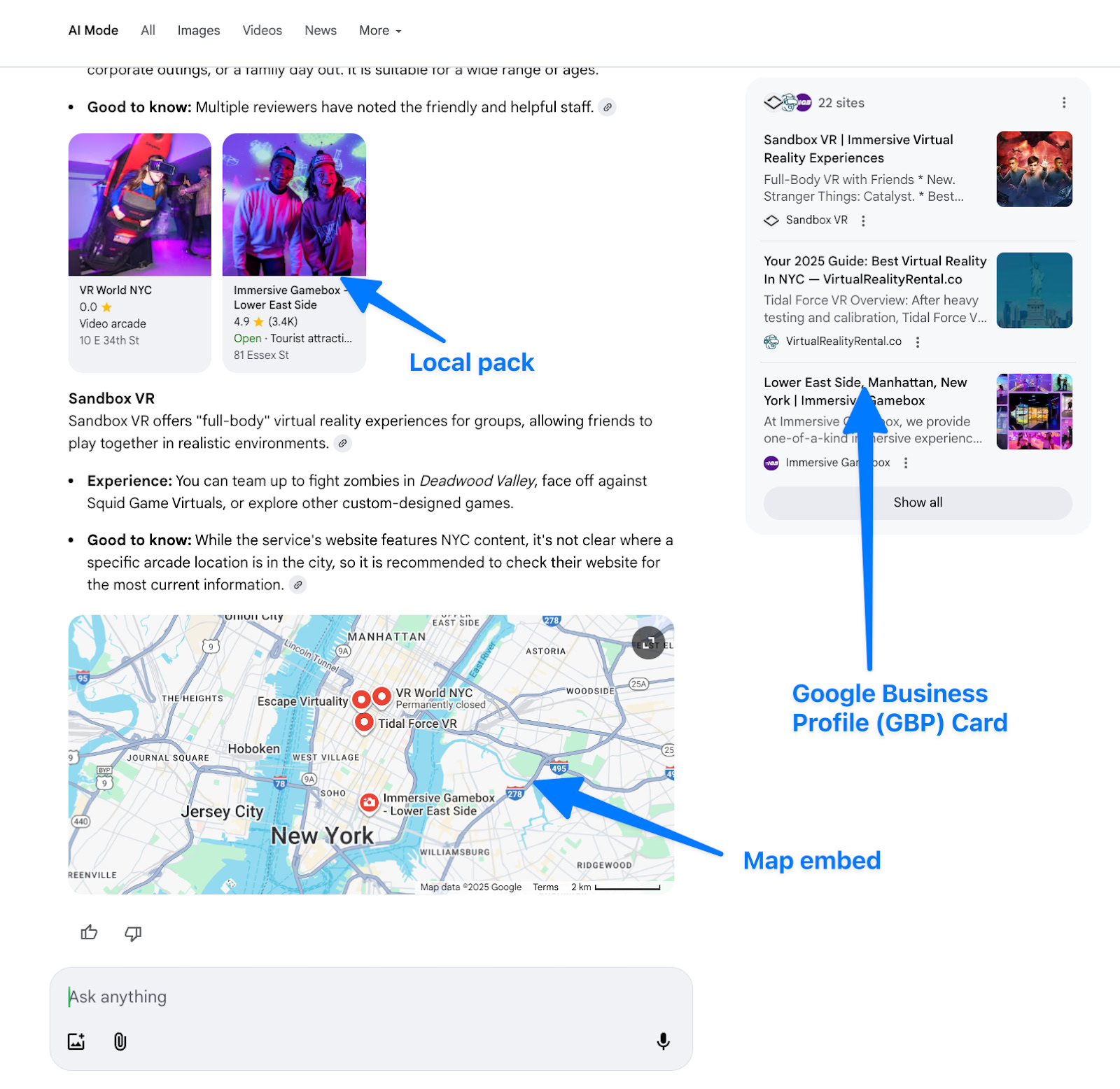
Интересно, что, несмотря на то, что они не появлялись на каждой странице поисковой выдачи, ‘GBP cards’ (карты с информацией из Google Business Profile) удивительным образом оказались эффективными для привлечения пользователей к взаимодействию с результатами поиска. Люди быстро просматривали эти карты, но также довольно часто на них нажимали.
Эти опции кажутся сильной альтернативой традиционным внешним ссылкам и рекламным карточкам, поскольку последние использовались гораздо реже в аналогичных ситуациях.
Активность пользователей, которую мы наблюдали, интересна и заслуживает внимания, но важно помнить, что только один из поисковых запросов в нашем исследовании был конкретно направлен на поиск локальной или географически-связанной информации.
Нам нужно больше информации, чтобы полностью понять, как люди ведут себя при поиске местных предприятий. SEO-специалистам также следует сосредоточиться на оптимизации списков Google Business Profile, поскольку пользователи активно взаимодействуют с этой функцией.
SEO-специалисты по электронной коммерции могут выдохнуть: задачи покупок отбирают внешние клики.
В прошлой записке я выделил следующее:
Здесь я собираюсь развить эту находку. Это более тонкий момент, чем просто «пользователи редко кликают вообще».
Зависит от того, нажмет ли кто-то на ссылку на другой сайт – пытаются ли они совершить покупку или просто найти информацию? Если их поиск был связан с покупками, они нажимали на внешнюю ссылку каждый раз.
Пакеты покупок появились примерно в четверти (26%) заданий, которые мы наблюдали. Когда пользователи их видели, они довольно часто на них нажимали – в 34 из 65 случаев.
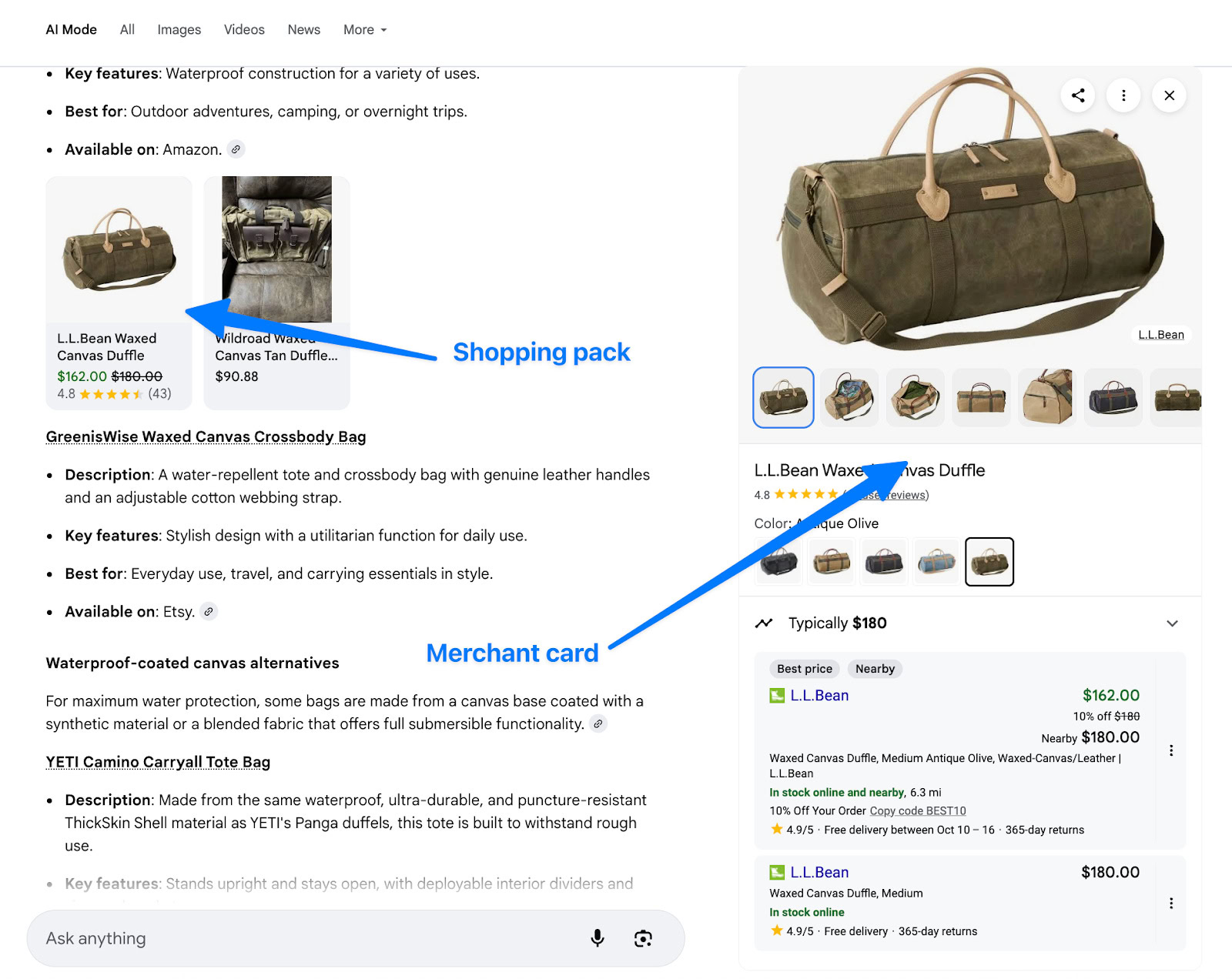
В ходе исследования участникам было предложено выполнить весь процесс покупок, от просмотра товаров до добавления их в корзину, имитируя поведение типичного покупателя, готового совершить покупку.
- Нажатие на Shopping Pack → Открытие всплывающего окна Merchant Card (количество: 28 раз).
- Нажатие на встроенную текстовую ссылку → Открытие всплывающего окна Карточки Торговца (произошло: 17 раз).
- Правая панель нажата только (встречается: 15 раз).
Пакеты покупок – это распространенный способ для клиентов просматривать и находить интересующие их продукты. При нажатии на товар в пакете вы попадаете на специальную страницу с более подробной информацией об этом конкретном продукте.
Одна логичная причина? У них есть изображения (распространенная мудрость UX говорит, что люди нажимают там, где есть изображение).
Вопросы – это новая привычка поиска – и раскрывают интересный поведенческий паттерн.
С тех пор, как такие инструменты, как ChatGPT, стали популярными, всё больше и больше людей используют поиск в разговорном стиле – по сути, они ищут, задавая вопросы, а не просто вводя ключевые слова.
Это исследование режима ИИ подтвердило это еще раз, но данные также выявили интересную находку.
Мы проанализировали 250 запросов и обнаружили, что большинство – 88.8% – были написаны так, как будто обращаются к AI-чатботу, используя разговорный язык. Оставшиеся 11.2% были больше похожи на традиционные поисковые запросы, использующие ключевые слова. Важно помнить, что мы проанализировали только самый первый запрос, который отправил каждый пользователь, а не какие-либо последующие вопросы или запросы.
Наши данные показывают, что люди гораздо больше предпочитают взаимодействовать с чат-ботами и вести беседы, чем вводить поисковые запросы, как они делали раньше.
Но вот необычный паттерн, который мы заметили в данных:
Пользователи, которые формулировали запросы в разговорной форме, гораздо чаще переходили на внешние веб-сайты.
Это примечательно, потому что это предполагает, что люди, которые уже знакомы с поиском на основе искусственного интеллекта или чат-ботами, могут быть более склонны нажимать на результаты, чтобы перепроверить или узнать больше.
Это одна из гипотез, объясняющих, почему эта закономерность возникает. Ещё одна идея?
Когда кто-то печатает вопрос, он обычно вдумчив и полон решимости найти исчерпывающий ответ, что означает, что он, вероятно, будет изучать источники, выходящие за рамки того, что может предложить ИИ в одиночку. Понимание этого может быть ценным при создании профилей клиентов для вашего бренда.
Мы не нашли однозначного объяснения того, почему более длинный, более разговорный язык, казалось, стимулировал больше кликов на внешние веб-сайты, но эта связь всё равно заслуживает упоминания.
Смотрите также
- Анализ динамики цен на криптовалюту NEXO: прогнозы NEXO
- Какой самый низкий курс доллара к швейцарскому франку?
- Какой самый низкий курс евро к венгерскому форинту?
- Какой самый низкий курс доллара к венгерскому форинту?
- Анализ динамики цен на криптовалюту TAO: прогнозы TAO
- Какой самый низкий курс евро к юаню?
- 25 Альтернативных Поисковых Систем, Которые Вы Можете Использовать Вместо Google
- Какой самый низкий курс индийской рупии к рублю?
- Анализ динамики цен на криптовалюту RENDER: прогнозы RENDER
- Анализ динамики цен на криптовалюту ALGO: прогнозы ALGO
2025-10-15 17:12