На протяжении многих лет цифровая сфера в основном характеризовалась гиперссылками — простым, но мощным средством связи документов в обширной, неупорядоченной базе данных. Однако изначальное великое видение для сети последовательно стремилось к чему-то гораздо более масштабному.
Задуманная концепция заключалась в создании семантической сети — сети, в которой значение связей между идеями столь же важно, как и связи между веб-страницами. Это позволяет машинам понимать не только буквальный текст, но и контекст и суть данных, с которыми они сталкиваются.
С новым экспериментом Search Labs инновации Google меня восхищают, поскольку они делают значительный шаг в этом конкретном направлении.
Web-гид Google структурирован таким образом, чтобы помогать в поиске подробной информации, а не просто веб-страниц. Он служит альтернативой режиму ИИ и обзору ИИ, предназначенной для решения сложных, многогранных вопросов или предоставления широкой перспективы на тему, рассматривая её с разных углов.
Веб-гид, работающий на основе специализированной версии модели Gemini AI, организует результаты поиска в удобные категории для облегчения просмотра.
Это знаменует собой решающий поворотный момент, поскольку фундаментальная структура поисковых систем продвигается к естественному пониманию концепции семантического понимания. Это значительный сдвиг, указывающий на то, что базовая основа поисковых систем развивается, чтобы естественно усваивать идею семантического понимания.
Web Guide означает переход от традиционного веба, основанного на страницах и общих рейтингах, к более интеллектуальному вебу, ориентированному на понимание и индивидуальную настройку.
Эта статья рассматривает принципы работы Web Guide, исследует его влияние на издателей и предлагает потенциальные обновления наших стратегий в контексте поисковой оптимизации (SEO) или, более конкретно, генеративной поисковой оптимизации (GEO).
Как опытный специалист по SEO, я рассматриваю Web Guide не просто как дополнительный инструмент, а как взгляд в будущее поиска и потребления знаний.
Как работает поисковая справка Google: технология гиперперсонализированной SERP
Внешне Google Web Guide сигнализирует о редизайне страницы результатов поиска. Вместо привычного линейного расположения
В поисковом запросе, таком как «Как путешествовать в одиночку по Японии», пользователь может столкнуться с чётко обозначенными, разворачивающимися разделами «Подробные руководства», «Личные истории» и «Советы по безопасности».
Эта функция позволяет пользователям быстро сосредоточиться на наиболее важной части их вопроса, немедленно.
Как профессионал в области цифрового маркетинга, я рад поделиться тем, что настоящее преображение заключается не только в поверхностных изменениях, но и происходит в глубине системы! Волшебство, стоящее за нашим процессом отбора, питается индивидуальной версией модели Gemini от Google. Однако то, что действительно отличает нас, — это инновационная техника под названием «расширение запросов». Этот метод расширяет область нашего поиска, предоставляя вам более полные и целевые результаты.
Когда пользователь вводит вопрос или команду, ИИ не просто ищет точное соответствие. Вместо этого он разбирает вероятный смысл ввода на несколько связанных, более точных подвопросов. Затем он расширяет поиск, одновременно просматривая информацию по этим подвопросам.
Для запроса «путешествие в Японию в одиночку» процесс ветвления может вызвать внутренние поиски, такие как «Советы по безопасности для одиноких женщин-путешественниц в Японии», «Лучшие публикации в блогах о путешествиях по Японии» и «Как использовать Japan Rail Pass».
Расширяя свой охват, ИИ собирает более полную и разнообразную подборку результатов. Впоследствии он сортирует и классифицирует эти результаты по конкретным темам, которые затем отображаются пользователю. Этот механизм обеспечивает персонализированный опыт в широком масштабе.
Страница результатов поиска (SERP) больше не является стандартным списком для всех пользователей; теперь она адаптируется и динамически создается, чтобы соответствовать различным, часто невысказанным, целям уникального поискового запроса пользователя. Я обнаружил это, изучая сетевые данные конкретного запроса — анализ HAR-файла.
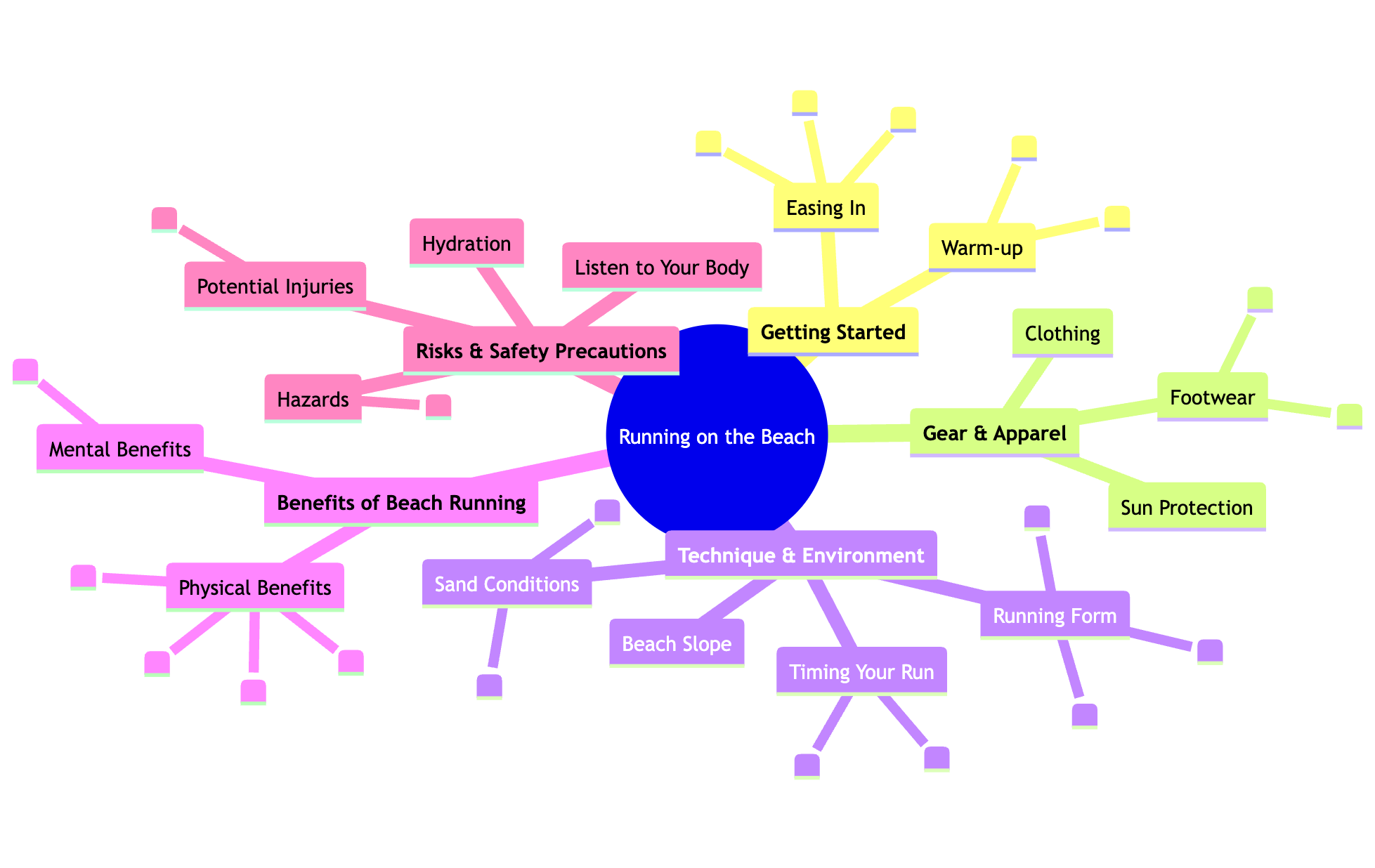
Давайте представим понимание этой концепции в более понятной форме. Рассмотрите вопрос: «Что мне нужно знать о беге по песку?» Затем ИИ разбирает этот вопрос на следующие ключевые аспекты: 1. Действия (бег) 2. Местоположения (пляж/песок) 3. Необходимая информация (что нужно знать). Разбивая запрос на эти основные компоненты, ИИ может эффективно анализировать и генерировать соответствующую информацию для более точного ответа.

Пользовательский интерфейс WebGuide состоит из различных компонентов, каждый из которых призван обеспечить всесторонний и индивидуальный пользовательский опыт.
- Основная тема: Центральная тема или запрос, который ввел пользователь.
Давайте рассмотрим Web Guide в контексте других инициатив Google в области искусственного интеллекта.
Уникальная роль Web Guide заключается в том, что он является куратором или библиотекарем на базе искусственного интеллекта.
Система искусственного интеллекта улучшает свои организационные возможности, не изменяя основной опыт перехода по ссылкам, тем самым предлагая уникальный и, возможно, менее спорный подход к интеграции искусственного интеллекта в поиск.
Дилемма издателя: угроза или возможность?
Ключевая проблема, связанная с поисковыми системами на основе искусственного интеллекта, заключается в том, что они могут значительно снизить органический трафик, который имеет решающее значение для финансового выживания большинства создателей контента. Эта обеспокоенность не только теоретическая. Основная проблема, связанная с поисковыми системами на основе ИИ, — это потенциальное снижение органического трафика, являющегося важным источником дохода для большинства разработчиков контента. Этот страх не является чисто гипотетическим.
Генеральный директор Cloudflare открыто выразил неодобрение этих действий, заявив, что они наносят ущерб нарушению потоков доходов издателей, мнение, которое разделяют многие в индустрии цифрового контента.
Этот страх проистекает из широко признанных последствий связанной функции Web Guide, AI Overviews. Основа для этого опасения заключается в широко продемонстрированных последствиях связанной функции Web Guide, AI Overviews.
Согласно всестороннему исследованию, проведенному Исследовательским центром Пью, наличие краткого обзора, сгенерированного искусственным интеллектом, в начале страницы результатов поиска (SERP) значительно снижает вероятность выбора пользователем органической ссылки. Это снижение соответствует примерно половине обычной доли кликов, согласно их выводам.
Google утверждает, что наблюдает устойчивый ответ, заявляя, что не заметил существенного снижения общего веб-трафика и что переходы со страниц с обзорами на основе искусственного интеллекта имеют более высокое качество.
В свете этих обстоятельств Web Guide предлагает более подробную перспективу. Разумно предположить, что, сохраняя традиционную модель кликов по ссылкам, эта платформа может оказаться полезной для издателей при применении искусственного интеллекта.
Метод «Запрос» может оказаться выгодным для подробного нишевого контента, который испытывает трудности с достижением более высоких рейтингов поисковой системы из-за конкуренции с более широкими ключевыми словами.
С оптимистической точки зрения, Web Guide функционирует как полезный и знающий библиотекарь, направляя пользователей к правильному отделу библиотеки, а не просто предоставляя краткий обзор на стойке регистрации.
Как эксперт по SEO, я бы перефразировал это предложение так: хотя оптимизация ссылок может привлечь больше трафика, важно отметить, что мы, по сути, передаем значительную редакционную власть сложному алгоритму. Точное влияние на общий трафик нашего сайта остается несколько непредсказуемым.
Новая инструкция: разработка для «распределения запросов»
Более современная и эффективная цель – это отход от стремления исключительно к топовым позициям в результатах поиска по конкретному ключевому слову, поскольку такой подход может вскоре считаться устаревшим и недостаточно всеобъемлющим.
Как специалист по цифровому маркетингу, работающий в современной динамичной среде, я обнаружил, что заметность зависит от контекстуальной значимости и позиционирования в группах, созданных искусственным интеллектом. Чтобы преуспеть в этой новой области, важно принять свежий тактический подход — оптимизацию генеративных движков (GEO).
GEO меняет свою стратегию оптимизации, чтобы улучшить видимость не только для поисковых роботов, но и в средах с искусственным интеллектом, стремясь к большей обнаруживаемости в системах на основе искусственного интеллекта.
В этом новом подходе достижение успеха зависит от понимания и применения системы «распределённых запросов». Эта система относится к тому, как один запрос или требование может быть распределено между несколькими источниками или сущностями.
Этап 1: Создание для «Распределения Запросов» с Тематическим Авторитетом
Более удачным способом сформулировать это было бы: чтобы получить наилучшие результаты, полезно заранее создавать контент, который тесно соответствует тем типам вопросов, которые может задать ИИ.
Перефразируя это более простым языком, можно сказать, что речь идет о разделении основных предметов на главные темы и поддерживающие их детали, а затем о создании подробных групп контента, которые всесторонне охватывают все аспекты темы.
Создание основной «ключевой» страницы для широкой темы, связывание её с множеством подробных статей, исследующих каждый аспект её подтем. Оба перефразирования сохраняют исходный смысл, используя более естественный и легко читаемый язык.
Создайте исчерпывающее руководство, которое будет служить центром, направляя читателей к подробным статьям. Эти статьи могут включать такие темы, как «Преимущества и недостатки бега по мокрому и сухому песку», «Выбор правильной обуви (или ее отсутствие) для бега по пляжу», «Стратегии гидратации и защиты от солнца для бегунов по пляжу» и «Улучшение вашей техники для бега по более мягким поверхностям».
Благодаря продуманной организации и связи связанных материалов издатель демонстрирует системам искусственного интеллекта свои обширные знания и опыт во всей предметной области.
Как эксперт по SEO, я бы перефразировал это утверждение следующим образом: оптимизируя поиск нашей ИИ в пределах конкретной области, мы значительно повышаем шансы обнаружить множество высококачественных результатов из этой области. Это делает его идеальным кандидатом для представления в различных отобранных группах Web Guide, что повышает его видимость и авторитетность.
Для эффективной реализации этого подхода он должен основываться на фундаментальных принципах E-E-A-T от Google (экспертность, опыт, авторитетность и надёжность). В условиях, где всё движется искусственным интеллектом, эти принципы приобретают ещё больший вес.
Столб 2: Освоение технического и семантического SEO для аудитории ИИ
Согласно данным Google, в настоящее время нет новых технических требований к элементам искусственного интеллекта; однако переход к модерации на основе искусственного интеллекта подчеркивает важность соблюдения установленных надлежащих практик.
- Структурированные данные (Schema Markup): Это сейчас важнее, чем когда-либо. Структурированные данные выступают в качестве прямой линии связи с моделями искусственного интеллекта, явно определяя сущности, свойства и взаимосвязи внутри вашего контента. Это делает контент «читаемым» для ИИ, помогая системе понимать контекст с большей точностью. Это может означать разницу между правильным определением как «руководство» и «личный блог», и, следовательно, размещением в соответствующем кластере.
- Базовое здоровье сайта: Модель искусственного интеллекта должна видеть страницу так же, как и пользователь. Хорошо организованная архитектура сайта с чистыми URL-структурами, которые группируют похожие темы в каталоги, предоставляет ИИ сильные сигналы о тематической структуре вашего сайта. Индексируемость, хороший пользовательский опыт и мобильная адаптивность являются важными условиями для эффективной конкуренции.
- Пишите, учитывая семиотику: как сказал бы Джанлука Фиорелли, сосредоточьтесь на сигналах, скрытых за сообщением. ИИ-системы теперь полагаются на гибридное разбиение; они разделяют контент на содержательные сегменты, которые объединяют текст, структуру, визуальные элементы и метаданные. Чем яснее ваши семиотические сигналы (заголовки, сущности, структурированные данные, изображения и связи), тем легче ИИ интерпретировать цель и контекст вашего контента. В этой поисковой среде, контролируемой ИИ, смысл и контекст стали вашими новыми ключевыми словами.
Невидимые риски: предвзятость в чёрном ящике
Серьёзной проблемой, связанной с системами на основе искусственного интеллекта, такими как Web Guide, является их непрозрачность, часто называемая проблемой «чёрного ящика». Это затрудняет обеспечение подотчётности и продвижение справедливости в их работе.
Как эксперт по SEO, я не могу раскрыть конкретные критерии, используемые моделью Gemini для генерации категорий и выбора страниц, поскольку эти процессы остаются конфиденциальными. Отсутствие прозрачности вызывает глубокие вопросы относительно справедливости процесса отбора и курации контента.
Существует большая вероятность того, что искусственный интеллект может не только имитировать, но и усугублять предрассудки, существующие в обществе и брендах. Чтобы проиллюстрировать это, давайте рассмотрим оценку сложных вопросов как способ оценить беспристрастность руководства по эксплуатации веб-сайта.


В связи с тем, что в основе этой системы лежат те же фундаментальные структуры, что и у традиционного поиска, существует большая вероятность того, что она продолжит или даже усугубит существующие предубеждения.
Заключение: Эпоха семантического веб, курируемого ИИ
Изменение веб-интерфейса Google — это не просто краткосрочная корректировка дизайна; скорее, это сигнализирует о значительном и постоянном изменении в том, как мы получаем информацию.
Усилия Google можно рассматривать как мост между традиционным, открытым и основанным на ссылках вебом и новой эрой искусственного интеллекта, который генерирует ответы, а не просто предоставляет ссылки.
Понимание влияния функции «расширение запросов» и последующего стратегического сдвига имеет решающее значение для всех участников. Адаптация в данном контексте является обязательной для всех заинтересованных сторон.
Наступило время управляемых ИИ «сегментов», и победа достанется тем, кто создаст обширную, семантически богатую базу знаний, которую ИИ сможет уверенно понимать, использовать и представлять.
Смотрите также
- Какой самый низкий курс евро к венгерскому форинту?
- Анализ динамики цен на криптовалюту TAO: прогнозы TAO
- Какой самый низкий курс доллара к швейцарскому франку?
- Какой самый низкий курс доллара к венгерскому форинту?
- Какой самый низкий курс индийской рупии к рублю?
- Анализ динамики цен на криптовалюту RENDER: прогнозы RENDER
- Акции PIKK. ПИК: прогноз акций.
- Рекомендации по видеоподтверждению профиля компании в Google
- Бесплатный помощник по написанию WordPress с искусственным интеллектом от Jetpack
- 7 терминов ИИ, которые хочет знать Microsoft в 2025 году
2025-08-11 15:20