Как опытный веб-мастер с многолетним опытом работы за плечами, я могу подтвердить важность правильного создания файла robots.txt. Это похоже на работу вышибалой в клубе, только вместо людей вы управляете ботами поисковых систем.
Как профессионал в области цифрового маркетинга, умение использовать файл robots.txt имеет важное значение для любой успешной стратегии SEO, которую я использую. Ошибки в этом файле могут повлиять на индексацию моего сайта поисковыми системами и повлиять на видимость отдельных страниц. Однако при правильном использовании он может повысить эффективность сканирования и уменьшить потенциальные проблемы при сканировании.
Как опытному веб-мастеру, Google только что напомнил мне о важности использования хорошо продуманного файла robots.txt для предотвращения нежелательных URL-адресов на моих веб-сайтах. Все дело в сохранении контроля над тем, как боты поисковых систем взаимодействуют с моим контентом и индексируют его.
Как специалист по цифровому маркетингу, я часто в своей повседневной работе сталкиваюсь с такими терминами, как страницы «добавление в корзину», «вход» и «оформление заказа». Однако реальная проблема заключается в их эффективном использовании. Вот простая разбивка:
В этой статье мы расскажем вам обо всех нюансах, как это сделать.
Что такое Robots.txt?
Проще говоря, файл robots.txt, расположенный в основной папке вашего веб-сайта, служит руководством для веб-сканеров, указывая им, какие страницы или разделы вашего сайта доступны для индексации.
В таблице ниже приведены краткие ссылки на ключевые директивы файла robots.txt.
| Директива | Описание |
| Пользовательский агент | Указывает, к какому сканеру применяются правила. См. токены пользовательского агента. Использование * нацелено на всех сканеров. |
| Запретить | Запрещает сканирование указанных URL-адресов. |
| Позволять | Разрешает сканирование определенных URL-адресов, даже если родительский каталог запрещен. |
| Карта сайта | Указывает местоположение вашего XML-файла Sitemap, помогая поисковым системам обнаружить его. |
Это пример файла robot.txt с сайта ikea.com с несколькими правилами.
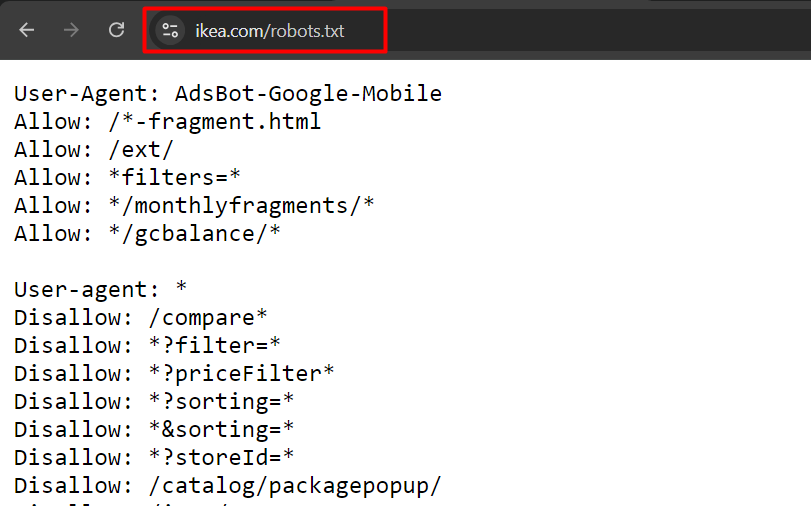
Обратите внимание, что файл robots.txt не поддерживает полные регулярные выражения и содержит только два подстановочных знака:
- Звездочки (*), соответствующие 0 или более последовательностям символов.
- Знак доллара ($), соответствующий концу URL-адреса.
Также обратите внимание, что его правила чувствительны к регистру, например, «filter=» не равно «Filter=».
Порядок приоритета в robots.txt
Чтобы эффективно создать файл robots.txt, важно понимать, как поисковые системы расставляют приоритеты и выбирают между противоречивыми рекомендациями. Это означает знание последовательности, которой они следуют при работе с конкурирующими правилами в вашем файле.
Они следуют этим двум ключевым правилам:
1. Самое конкретное правило
Будет применено правило, соответствующее большему количеству символов в URL-адресе. Например:
User-agent: *
Disallow: /downloads/
Allow: /downloads/free/Правило «Разрешить: /downloads/free/» более точное, чем «Запретить: /downloads/», поскольку оно конкретно обращается к подкаталогу в основном каталоге.
Google разрешает сканирование подпапки «/downloads/free/», но запрещает индексирование всего остального в папке «/downloads/».
2. Наименее ограничительное правило
Когда несколько правил одинаково специфичны, например:
User-agent: *
Disallow: /downloads/
Allow: /downloads/Google выберет наименее ограничительный вариант. Это означает, что Google разрешит доступ к /downloads/.
Почему файл robots.txt важен для SEO?
Как специалист по цифровому маркетингу, я считаю полезным стратегически использовать файл robots.txt, чтобы ограничить доступ робота Googlebot к несущественным веб-страницам. Это позволяет боту сконцентрировать свой краулинговый бюджет на ценных разделах сайта и вновь созданных страницах. Кроме того, блокируя ненужные страницы, мы помогаем поисковым системам экономить вычислительные ресурсы, способствуя большей устойчивости наших усилий в области цифрового маркетинга.
Представьте себе такой сценарий: вы управляете огромным онлайн-рынком с сотнями тысяч веб-страниц. Некоторые области веб-сайта, такие как результаты поиска или списки продуктов на основе фильтров, потенциально могут иметь неограниченное количество вариантов.
Именно здесь на помощь приходит файл robots.txt, который не позволяет ботам поисковых систем сканировать эти страницы.
Неправильная обработка параметров URL-адресов может привести к тому, что Google попытается просканировать бесконечный массив URL-адресов, некоторые из которых могут даже не существовать. Это может привести к скачкам ресурсов и растрате краулингового бюджета вашего сайта.
Когда использовать robots.txt
В большинстве случаев важно задаться вопросом о назначении конкретных веб-страниц и определить, есть ли смысл для сканеров поисковых систем сканировать и составлять их списки.
Если исходить из этого принципа, то, конечно, мы всегда должны блокировать:
- URL-адреса, содержащие параметры запроса, такие как:
<ул> - Внутренний поиск.
- URL-адреса фасетной навигации, созданные с помощью параметров фильтрации или сортировки, если они не являются частью структуры URL-адресов и стратегии SEO.
- URL-адреса действий, например «Добавить в список желаний» или «Добавить в корзину».
- Частные части веб-сайта, такие как страницы входа.
- Файлы JavaScript, не имеющие отношения к содержимому или рендерингу веб-сайта, например сценарии отслеживания.
- Блокируйте парсеры и чат-боты с искусственным интеллектом, чтобы они не могли использовать ваш контент в своих учебных целях.
Давайте углубимся в то, как вы можете использовать robots.txt для каждого случая.
1. Блокируйте страницы внутреннего поиска
Важнейшим и незаменимым действием является предотвращение индексации внутренних поисковых ссылок поисковыми системами, такими как Google, поскольку почти все веб-сайты оснащены встроенной функцией поиска.
На веб-сайтах WordPress это обычно параметр «s», а URL-адрес выглядит следующим образом:
https://www.example.com/?s=googleКак специалист по цифровому маркетингу, я прислушался к неоднократному совету Гэри Иллиеса о том, чтобы запретить доступ Googlebot к URL-адресам «действия». Эти типы URL-адресов могут привести к тому, что робот Googlebot будет их бесконечно сканировать, даже если эти URL-адреса не существуют или представляют собой разные комбинации. Чтобы избежать потенциальных проблем с бесконечным сканированием, я гарантирую, что эти URL-адреса действий эффективно блокируются в структуре нашего веб-сайта.
Вот правило, которое вы можете использовать в файле robots.txt, чтобы заблокировать сканирование таких URL-адресов:
User-agent: *
Disallow: *s=*- Строка User-agent: * указывает, что правило применяется ко всем веб-сканерам, включая Googlebot, Bingbot и т. д.
- Строка Disallow: *s=* сообщает всем сканерам не сканировать URL-адреса, содержащие параметр запроса «s=». Подстановочный знак «*» означает, что он может соответствовать любой последовательности символов до или после «s=». Однако он не будет сопоставлять URL-адреса с заглавной буквой «S», например «/?S=», поскольку он чувствителен к регистру.
На этом сайте им удалось существенно снизить скорость сканирования нефункциональных внутренних поисковых ссылок, заблокировав их с помощью файла robots.txt.
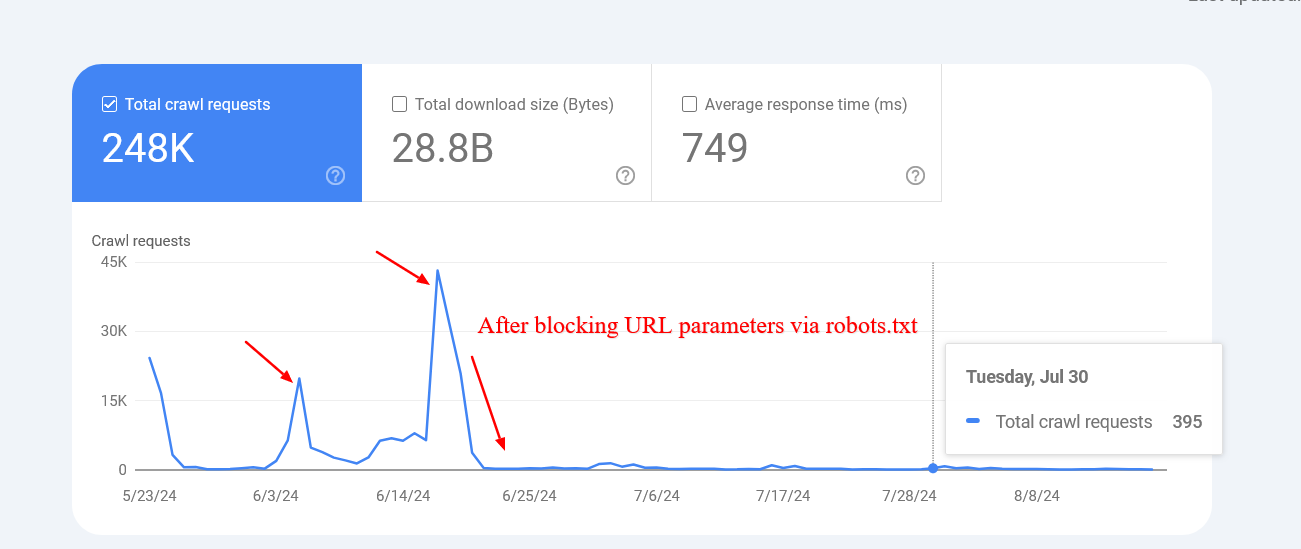
Имейте в виду, что Google может внести в каталог заблокированные вами страницы, но не стоит беспокоиться, поскольку они постепенно исчезнут из своих записей.
2. Блокируйте URL-адреса фасетной навигации.
В каждом интернет-магазине фасетная навигация играет решающую роль. Иногда эта функция также включается в план SEO с целью появления в результатах поиска для широких категорий продуктов.
Например, Zalando структурирует свои URL-адреса, используя фасетную навигацию для выбора цвета, что помогает ему ранжироваться по более широким терминам продукта, таким как «серая футболка».
Обычно эти параметры фильтра не используются по назначению; вместо этого они служат в основном инструментом для фильтрации элементов, в результате чего множество страниц заполняются повторяющимся контентом.
С моей точки зрения как опытного веб-мастера, эти параметры имеют сходство с параметрами внутреннего поиска, но есть ключевое отличие: они могут проявляться в нескольких формах. Очень важно заблокировать все варианты, чтобы сохранить целостность и безопасность вашего сайта.
Вот способ перефразировать данный текст:
User-agent: *
Disallow: *sortby=*
Disallow: *color=*
Disallow: *price=*В зависимости от вашего конкретного случая параметров может быть больше, и вам может потребоваться добавить их все.
А как насчет параметров UTM?
Параметры UTM используются для отслеживания.
Согласно тому, что Джон Мюллер опубликовал на Reddit, нет необходимости беспокоиться о внешних ссылках, указывающих на ваши веб-страницы с использованием параметров URL.
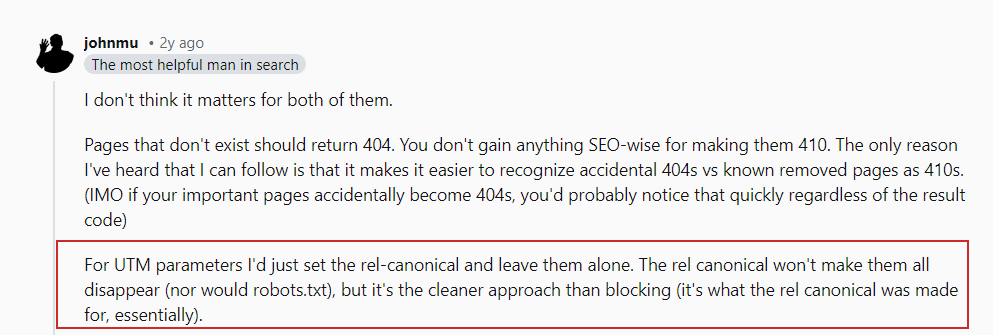
Убедитесь, что вы исключили любые произвольные переменные, используемые в вашей системе, и воздержитесь от внутреннего подключения к таким страницам, например, не связывайте статьи со страницей поиска с помощью поискового запроса типа «https://www.example.com/search?q». = Гугл.» Вместо этого стремитесь к более чистым и удобным для пользователя URL-адресам.
3. Блокируйте URL-адреса PDF-файлов
Предположим, у вас под рукой имеется множество PDF-файлов — руководств пользователя, каталогов или статей для загрузки — и вы хотите запретить их поиск или индексирование.
Вот простое правило robots.txt, которое блокирует доступ поисковых роботов к этим документам:
User-agent: *
Disallow: /*.pdf$Строка «Disallow: /*.pdf$» указывает сканерам не сканировать URL-адреса, заканчивающиеся на .pdf.
Использование `/*`, как правило, соответствует любому пути на сайте. Следовательно, URL-адреса, заканчивающиеся на .pdf, не будут разрешены для сканирования.
Чтобы предотвратить загрузку PDF-файлов в каталог загрузок вашего веб-сайта WordPress через систему управления контентом (CMS), вы можете реализовать это правило:
User-agent: *
Disallow: /wp-content/uploads/*.pdf$
Allow: /wp-content/uploads/2024/09/allowed-document.pdf$Вы можете видеть, что у нас здесь противоречивые правила.
Если существует несколько правил, противоречащих друг другу, приоритет будет иметь более подробное или конкретное правило. Это означает, что сканирование будет разрешено только PDF-документу, расположенному в папке «wp-content/uploads/2024/09/allowed-document.pdf».
4. Заблокировать каталог
Предположим, вы работаете с формой, которая отправляет данные через конечную точку API. URL-адрес этой конечной точки может выглядеть примерно так: «/form/submissions/.
Проблема в том, что Google может попытаться получить доступ к URL-адресу «/form/submissions/», который вы, вероятно, не собираетесь посещать. Чтобы предотвратить индексацию таких URL-адресов, рассмотрите возможность реализации этого правила:
User-agent: *
Disallow: /form/Как специалист по цифровому маркетингу, я хотел бы поделиться эффективным способом контроля над тем, как сканеры поисковых систем перемещаются по вашему веб-сайту: определяя каталог в правиле Disallow, вы, по сути, даете им указание обходить все страницы в этом конкретном каталоге. Это означает, что вам больше не нужно использовать подстановочный знак (*), например «/form/*». Этот метод может быть полезен, если вы хотите ограничить доступ к определенным разделам вашего сайта во время SEO-оптимизации.
Не забывайте всегда использовать относительные пути вместо абсолютных URL-адресов при определении директив Disallow и Allow. Например, вместо использования «https://www.example.com/form/» вам следует написать просто «/form/» или любой другой путь относительно корневого каталога вашего проекта.
Чтобы предотвратить создание неправильных правил, составляйте их тщательно. Например, отсутствие косой черты в конце «/form» может непреднамеренно совпадать с такими URL-адресами, как «/form-design-examples/», которые могут быть публикацией из вашего блога, которую вы хотите исключить из индексации.
5. Блокируйте URL-адреса учетных записей пользователей.
На сайте электронной коммерции вполне возможно, что вы найдете папки, начинающиеся с «/myaccount/», например «/myaccount/orders/» и «/myaccount/profile/».
Чтобы ваша страница входа, расположенная по адресу «/myaccount/», была легко доступна пользователям через поисковые системы, было бы полезно запретить сканирование ее подстраниц ботом Google (Googlebot). Таким образом, фокус сохраняется на главной странице входа.
Вы можете применить правило «Запретить», а затем правило «Разрешить», чтобы запретить доступ ко всему содержимому папки «/myaccount/», за исключением самой страницы «/myaccount/».
User-agent: *
Disallow: /myaccount/
Allow: /myaccount/$
Перефразируя, Google не разрешает индексировать ничего в папке «/myaccount/», за исключением самой главной страницы «/myaccount/». В этом случае следует более конкретное правило.
В этом сценарии рассмотрите возможность использования сочетания директив «Запретить» и «Разрешить» для достижения оптимального результата. Например, если ваши поисковые запросы расположены в каталоге «/search/» и вы хотите, чтобы их можно было обнаружить и проиндексировать, но исключить фактические URL-адреса поиска, вот пример того, как вы можете его структурировать:
User-agent: *
Disallow: /search/
Allow: /search/$
6. Блокируйте файлы JavaScript, не связанные с рендерингом
Большинство веб-сайтов используют JavaScript, причем большая часть этих скриптов служит целям, не связанным с отображением контента, включая сценарии отслеживания, загрузчики AdSense и т. д.
Ниже приведен пример строки, запрещающей пример JavaScript, содержащий пиксели отслеживания.
User-agent: *
Disallow: /assets/js/pixels.js7. Блокируйте чат-ботов и скраперы с искусственным интеллектом
Многие издательства выражают обеспокоенность по поводу того, что их материалы без согласия используются для разработки моделей искусственного интеллекта — практики, которую они стараются избегать.
#ai chatbots
User-agent: GPTBot
User-agent: ChatGPT-User
User-agent: Claude-Web
User-agent: ClaudeBot
User-agent: anthropic-ai
User-agent: cohere-ai
User-agent: Bytespider
User-agent: Google-Extended
User-Agent: PerplexityBot
User-agent: Applebot-Extended
User-agent: Diffbot
User-agent: PerplexityBot
Disallow: /#scrapers
User-agent: Scrapy
User-agent: magpie-crawler
User-agent: CCBot
User-Agent: omgili
User-Agent: omgilibot
User-agent: Node/simplecrawler
Disallow: /В этой настройке отдельно упоминается каждый пользовательский агент, а инструкция «Запретить: /» означает, что роботам следует избегать доступа к какой-либо части веб-сайта.
Кроме того, эта функция не только запрещает искусственному интеллекту изучать ваш контент, но также снижает нагрузку на ваш сервер, ограничивая сбор чрезмерных данных.
Чтобы выяснить, какие боты могут нуждаться в блокировке из-за перегрузки вашего сервера, рекомендуется проверить файлы журналов вашего сервера на наличие сканеров, вызывающих чрезмерный трафик. Имейте в виду, что, хотя файл robots.txt помогает направлять ботов, он не предотвращает несанкционированный доступ.
8. Укажите URL-адреса файлов Sitemap.
Указывая URL-адрес карты сайта в файле robots.txt, вы позволяете поисковым системам легко перемещаться по всем важным страницам вашего веб-сайта. Это достигается за счет включения определенной строки, ведущей к местоположению вашей карты сайта, и вы даже можете указать несколько карт сайта, каждую в отдельной строке.
Sitemap: https://www.example.com/sitemap/articles.xml
Sitemap: https://www.example.com/sitemap/news.xml
Sitemap: https://www.example.com/sitemap/video.xmlВместо правил «Разрешить» или «Запретить», которые могут указывать только относительный путь, директива Sitemap требует полный абсолютный URL-адрес для определения местоположения карты сайта.
Во избежание ошибок убедитесь, что URL-адреса файлов Sitemap доступны поисковым системам и имеют правильный синтаксис.
9. Когда использовать задержку сканирования
Проще говоря, инструкция задержки сканирования в файле robots.txt устанавливает время в секундах, в течение которого веб-сканер должен сделать паузу перед переходом к следующей странице. Хотя бот Google не подтверждает эту команду, другие веб-сканеры могут ей подчиняться.
Это помогает предотвратить перегрузку сервера, контролируя частоту сканирования вашего сайта ботами.
Чтобы ClaudeBot не перегружал ваш сервер во время обучения ИИ, выполняя слишком много запросов одновременно, рассмотрите возможность установки задержки сканирования, чтобы регулировать временной интервал между каждым запросом.
User-agent: ClaudeBot
Crawl-delay: 60Инструкции предписывают ClaudeBot делать паузу на 60 секунд после каждого запроса, который он делает во время просмотра сайта.
Конечно, могут быть боты с искусственным интеллектом, которые не соблюдают директивы о задержке сканирования. В этом случае вам может потребоваться использовать веб-брандмауэр, чтобы ограничить их скорость.
Устранение неполадок в файле Robots.txt
Создав собственный файл robots.txt, я воспользуюсь этими полезными инструментами для устранения любых потенциальных синтаксических ошибок и гарантирую, что я случайно не заблокировал критически важную веб-страницу от сканирования поисковыми системами.
1. Валидатор Robots.txt консоли поиска Google
Выполните следующие простые шаги: перейдите в меню «Настройки» и найдите «robots.txt». Там вы обнаружите встроенный верификатор robots.txt. Вот обучающее видео, показывающее, как получить и проверить файл robots.txt.
2. Парсер Google Robots.txt
Этот парсер является официальным парсером robots.txt от Google, который используется в Search Console.
Чтобы настроить и эффективно использовать его на своем персональном компьютере, необходимы некоторые передовые ноу-хау. Однако я настоятельно советую уделить время и внимательно следовать инструкциям на этой странице, поскольку это позволяет вам проверить внесенные вами изменения в файл robots.txt перед их загрузкой на свой сервер в соответствии с официальным парсером Google. Таким образом, вы сможете обеспечить совместимость и избежать потенциальных проблем.
Централизованное управление файлом Robots.txt
Для каждого домена и соответствующих ему субдоменов необходимо создать отдельные файлы robots.txt, поскольку робот Googlebot не признает файл robots.txt корневого домена для субдомена.
Управление несколькими поддоменами на одном веб-сайте может привести к сложностям, поскольку требует индивидуального обслуживания множества файлов robots.txt.
Вы также можете организовать так, чтобы файл robots.txt размещался на поддомене следующим образом:
Вместо этого вы можете рассмотреть возможность настройки таким образом, чтобы вы могли выполнять операцию взаимно, при этом основной домен размещает ее напрямую, а также перенаправляет трафик из поддоменов в корневой домен.
Перенаправленные файлы будут обрабатываться поисковыми системами так, как если бы они находились на уровне основного домена, что дает возможность централизованно управлять рекомендациями robots.txt не только для основного домена, но и для его поддоменов.
Вместо того, чтобы требовать уникальный файл robots.txt для каждого поддомена, этот метод упрощает обновления и обслуживание, делая их более эффективными.
Заключение
Обязательно всегда проверяйте свои изменения, чтобы избежать непредвиденных проблем при сканировании.
Приятного ползания!
Смотрите также
- Налоговое Обложение Криптовалюты в Кении: Рецепт Цифрового Катастрофы или Всего Лишь Налогообложения?
- Google тихо заканчивает поддержку структурированных данных эпохи COVID
- Обзоры искусственного интеллекта Google избегают политического контента, показывают новые данные
- Результаты поиска Google более персонализированы?
- Золото прогноз
- Прогноз нефти
- Анализ динамики цен на криптовалюту ETH: прогнозы эфириума
- Семья Трампа приобрела огромное количество оборудования для майнинга Биткойна?! Безумие с ASIC!
- Акции DATA. Группа Аренадата: прогноз акций.
- Почему ваш SEO не работает, и это не вина команды
2024-10-18 14:09