

Как опытный профессионал в области SEO, имеющий за плечами годы борьбы с цифровыми джунглями, я искренне поддерживаю использование инструментов аудита веб-сайтов для оптимизации ваших усилий по оптимизации. Такие инструменты, как WebSite Auditor, Screaming Frog, Lumar, Oncrawl или SE Ranking, были моими верными спутниками в навигации по лабиринту мира SEO.
Идея краулингового бюджета относится к важнейшему принципу SEO, особенно для обширных сайтов, содержащих миллионы страниц, или даже для небольших сайтов с тысячами, которые обновляются ежедневно. Все дело в управлении скоростью, с которой роботы поисковых систем могут эффективно исследовать и индексировать эти страницы.
Примером веб-сайта с миллионами страниц может служить eBay.com, а веб-сайтами с десятками тысяч страниц, которые часто обновляются, могут быть веб-сайты с обзорами пользователей и рейтингами, подобные Gamespot.com.
Из-за многочисленных обязанностей и проблем, с которыми сталкивается эксперт по SEO, сканирование сайта обычно задерживается или ему присваивается более низкий приоритет.
Но краулинговый бюджет можно и нужно оптимизировать.
В этой статье вы узнаете:
- Как улучшить свой краулинговый бюджет.
- Изучите изменения в краулинговом бюджете как концепции за последние пару лет.
Как специалист по SEO, я хотел бы обратить ваше внимание на проблему, которая может повлиять на ваш сайт, если на нем относительно небольшое количество страниц, но они не индексируются. Рекомендуется углубиться в общие причины проблем с индексацией, так как маловероятно, что в этом случае виноват краулинговый бюджет.
Что такое краулинговый бюджет?
Как специалист по цифровому маркетингу, я бы описал свое понимание «бюджета сканирования» следующим образом: он представляет собой объем страниц на веб-сайте, которые сканеры поисковых систем (например, пауки и боты) решают исследовать в течение определенного периода. Другими словами, речь идет о том, насколько глубоко эти сканеры углубляются в наш сайт, гарантируя, что они не пропустят важный контент, а также не перегрузят его ненужными страницами.
При настройке краулингового бюджета необходимо учитывать несколько ключевых факторов. Например, важно найти тонкий баланс: с одной стороны, Googlebot должен стремиться не перегружать ваш сервер слишком большим количеством запросов, а с другой стороны, Google хочет тщательно изучить домен вашего веб-сайта.
Повышение оптимизации бюджета сканирования означает реализацию стратегий, которые повышают скорость и частоту доступа роботов поисковых систем к страницам вашего веб-сайта, тем самым повышая их общую эффективность.
Почему важна оптимизация бюджета сканирования?
Сканирование — первый шаг к появлению в поиске. Без сканирования новые страницы и обновления страниц не будут добавляться в индексы поисковых систем.
Частое посещение сканерами ваших веб-страниц означает более быстрое добавление обновлений и нового контента в индекс поисковой системы. Это приводит к сокращению времени на то, чтобы ваши стратегии оптимизации стали эффективными и повлияли на рейтинг вашего сайта.
Индекс Google охватывает бесчисленные миллиарды веб-страниц и ежедневно расширяется. По мере увеличения количества веб-сайтов поисковые системы стремятся сократить расходы на вычисления и хранение, замедляя скорость сканирования URL-адресов и индексируя меньшее количество веб-страниц.
Кроме того, растет ощущение необходимости снизить выбросы углекислого газа ради сохранения климата, и Google стремится разработать долгосрочный план, который повысит устойчивость и сократит выбросы углекислого газа.
Итак, давайте обсудим, как вы можете оптимизировать свой краулинговый бюджет в современном мире.
1. Запретить сканирование URL-адресов действий в robots.txt
Это может вас шокировать, но Google подтвердил, что блокировка URL-адресов не повлияет на скорость сканирования вашего сайта. Другими словами, Google продолжит сканировать ваш сайт в обычном темпе. Однако вы можете задаться вопросом, почему мы обсуждаем эту тему. Причина в том, что понимание того, как работает бюджет сканирования Google, может помочь оптимизировать ваш сайт для лучшей индексации и повышения производительности поисковых систем.
Если вы исключаете из сканирования несущественные URL-адреса, вы, по сути, даете Google указание чаще сканировать ценные разделы вашего веб-сайта.
Например, если на вашем веб-сайте есть функция внутреннего поиска с такими параметрами запроса, как /?q=google, Google будет сканировать эти URL-адреса, если на них откуда-то есть ссылки.
На веб-сайте электронной коммерции URL-адрес может выглядеть следующим образом: /filtered-products?color=red&size=small. Проще говоря, это означает, что когда вы фильтруете товары по цвету (например, красный) и размеру (например, маленький), веб-сайт генерирует уникальный URL-адрес для отображения этих конкретных товаров.
Эти параметры, обнаруженные в строках запроса, могут генерировать огромное количество различных вариантов URL-адресов, любой из которых Google может попытаться изучить.
Предоставленные URL-адреса в основном не содержат отдельного контента; вместо этого они просеивают уже имеющиеся у вас данные. Хотя это улучшает взаимодействие с пользователем, это менее полезно для сканирующего бота Google (Googlebot).
Разрешая Google доступ к этим URL-адресам, вы неоправданно расходуете свой бюджет сканирования, что может повлиять на общую возможность сканирования вашего сайта. Вместо этого, установив правила robots.txt для запрета этих URL-адресов, Google сосредоточит свои усилия на сканировании более полезных страниц вашего веб-сайта.
Вот как заблокировать внутренний поиск, фасеты или любые URL-адреса, содержащие строки запроса, через robots.txt:
Disallow: *?*s=*
Disallow: *?*color=*
Disallow: *?*size=*
Каждое правило запрещает URL-адреса с определенным параметром запроса, независимо от каких-либо дополнительных параметров, которые они могут иметь.
- * (звездочка) соответствует любой последовательности символов (включая отсутствие).
- ? (Знак вопроса): указывает начало строки запроса.
- =*: Соответствует знаку = и всем последующим символам.
Использование этого метода предотвращает повторение, гарантируя, что URL-адреса, содержащие такие разные параметры запроса, не будут индексироваться ботами поисковых систем.
Имейте в виду, что этот метод предотвращает любые URL-адреса с указанными символами, независимо от их положения. Это потенциально может непреднамеренно заблокировать URL-адреса. Например, параметры запроса, состоящие из одного символа, могут привести к блокировке всех URL-адресов, содержащих этот символ, даже если он находится в другом месте URL-адреса. Если вы хотите ограничить URL-адреса, содержащие определенный одиночный символ, вместо этого рекомендуется использовать комбинацию правил: таким образом вы можете более точно определить, какие URL-адреса следует запретить.
Disallow: *?s=*
Disallow: *&s=*Критическое изменение заключается в том, что между символами «?» и «s» нет звездочки «*». Этот метод позволяет запретить определенные точные параметры «s» в URL-адресах, но вам придется добавлять каждый вариант индивидуально.
Включите эти рекомендации в свои отдельные сценарии, включающие URL-адреса, которые не предлагают эксклюзивный контент. Для иллюстрации: если у вас есть кнопки списка желаний, связанные с URL-адресами типа «?add_to_wishlist=1», обязательно заблокируйте такие URL-адреса с помощью этого метода:
Disallow: /*?*add_to_wishlist=*Это простой и естественный первый и самый важный шаг, рекомендованный Google.
Предотвратив индексацию этих конкретных параметров, Google удалось уменьшить количество страниц с чрезмерно очищаемыми строками запросов. Это произошло потому, что Google сталкивался с многочисленными URL-адресами с различными значениями параметров, которые были бессмысленными, что приводило к неработающим или нерелевантным страницам.
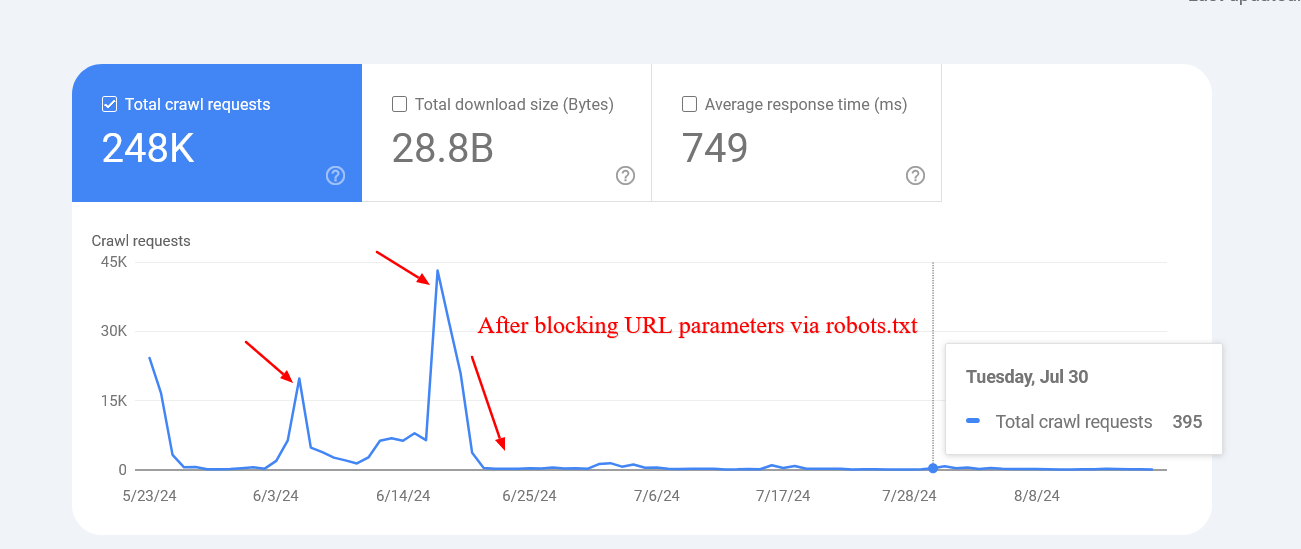
Иногда поисковые системы все еще могут сканировать и перечислять URL-адреса, которые предположительно запрещены. Хотя это может показаться необычным, обычно это не повод для беспокойства. Это часто происходит, когда другие сайты ссылаются на эти конкретные URL-адреса.
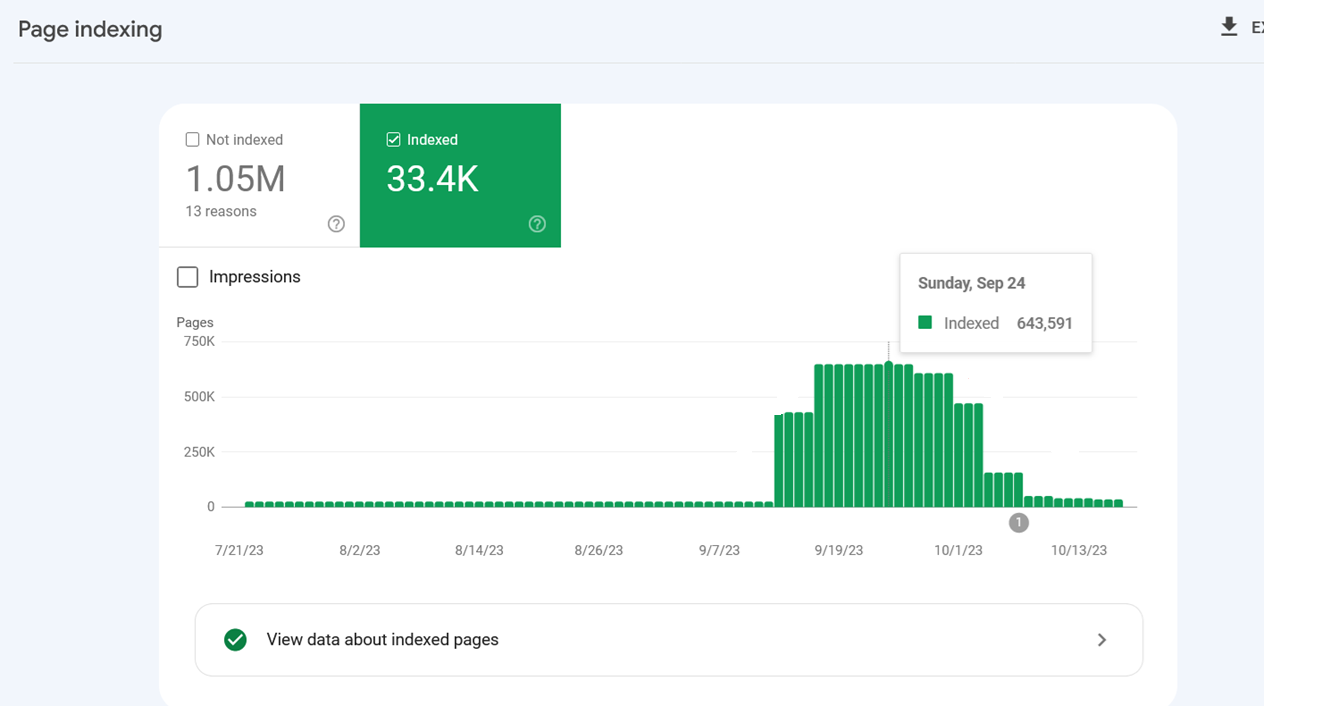
Google подтвердил, что в этих случаях активность сканирования со временем снизится.
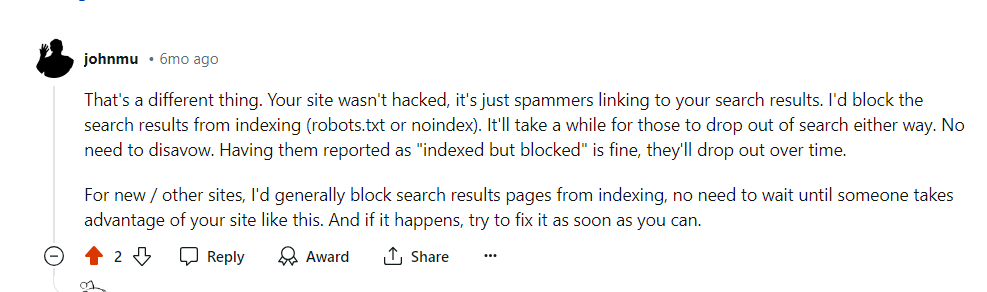
Избегайте применения «мета-тегов noindex» в целях блокировки, поскольку роботу Googlebot необходимо сделать запрос на проверку тега, что может неоправданно расходовать ваш краулинговый бюджет, поскольку требует выполнения запросов, даже если контент не предназначен для индексации.
1.2. Запретить URL-адреса неважных ресурсов в файле Robots.txt
Как специалист по цифровому маркетингу, я бы посоветовал вам рассмотреть возможность запрета файлов JavaScript, которые не влияют на дизайн или функциональность сайта. Эти дополнительные сценарии могут представлять потенциальную угрозу безопасности и непреднамеренно повлиять на производительность вашего сайта.
Если ваши файлы JavaScript выполняют задачу отображения изображений во всплывающем окне при клике пользователя, рассмотрите возможность их блокировки в файле robots.txt, чтобы поисковые системы, такие как Google, не тратили ресурсы на ненужное сканирование.
Вот пример правила запрета файла JavaScript:
Запретить: /assets/js/popup.js
Например, конечные точки REST API используются для обработки отправки форм. Предположим, у вас есть форма с URL-адресом действия «/api/form-submissions». Это пример того, как данные из отправленных форм могут быть отправлены на сервер с использованием этой структуры.
Вполне возможно, что эти URL-адреса могут быть проиндексированы Google. Поскольку они не имеют никакого отношения к аспекту отображения, было бы разумно запретить к ним доступ.
Запретить: /rest-api/form-submissions/
Поскольку многие безголовые CMS полагаются на REST API для динамической доставки контента, крайне важно обеспечить доступность этих конечных точек API.
Короче говоря, посмотрите на все, что не связано с рендерингом, и заблокируйте их.
2. Следите за цепочками перенаправления
Как опытный веб-мастер, я не могу не подчеркнуть важность понимания и устранения цепочек перенаправления. Видите ли, когда один URL-адрес указывает на другой URL-адрес, который затем снова перенаправляется (и так далее), вы получаете цепочку перенаправлений. Если этот процесс продолжится в течение некоторого времени, сканеры поисковых систем могут решить сократить свои потери и сразу перейти к конечному пункту назначения, потенциально пропуская по пути важный контент. Это может негативно повлиять на эффективность SEO вашего сайта. Всегда лучше оптимизировать перенаправление URL-адресов для более удобной работы в Интернете.
Как опытный веб-мастер, я хотел бы поделиться обычным явлением в мире URL-адресов: иногда один URL-адрес (URL 1) ведет к другому (URL 2), который затем ведет к третьему (URL 3), и так вперед. Эту серию редиректов часто называют цепочкой. Однако важно отметить, что эти цепочки также могут образовывать бесконечные циклы, когда один URL-адрес перенаправляется обратно на другой, создавая циклический шаблон.
Избегать этого — разумный подход к здоровью веб-сайта.
В идеале вы могли бы избежать наличия хотя бы одной цепочки перенаправлений на всем вашем домене.
Однако выполнение такой задачи на огромном сайте может оказаться сложной задачей из-за вероятности возникновения как 301, так и 302 редиректов. К сожалению, вы не можете исправить перенаправления, возникающие из входящих обратных ссылок, поскольку у вас нет контроля над иностранными веб-сайтами.
Хотя случайное отклонение не вызовет особых проблем, расширенные пути и круговые узоры могут привести к проблемам.
Чтобы исследовать и решить проблемы с цепочками перенаправлений, вы можете рассмотреть возможность использования популярных инструментов SEO, таких как Screaming Frog, Lumar или Oncrawl. Эти инструменты помогут вам легче идентифицировать и найти цепи.
Оптимальный подход для исправления цепочки (ссылки) — исключить все URL-адреса, соединяющие начальную страницу с последней. Например, если ваша цепочка охватывает семь страниц, лучше всего перенаправить самый первый URL-адрес прямо на седьмую страницу.
Удобный метод минимизации цепочек перенаправлений — обновление внутренних ссылок в вашей системе управления контентом (CMS), которые в данный момент перенаправляются, с указанием их конечных пунктов назначения.
В зависимости от используемой вами системы управления контентом (CMS) могут применяться различные подходы; например, вы можете использовать определенный плагин при работе с WordPress. Если вы используете отдельную CMS, вам может потребоваться индивидуальное решение или проконсультироваться со своей командой разработчиков, чтобы помочь вам.
3. Используйте рендеринг на стороне сервера (HTML), когда это возможно.
В настоящее время, когда дело доходит до операций Google, их сканер использует самую последнюю версию Chrome, гарантируя, что он может легко воспринимать контент, созданный с помощью JavaScript, без каких-либо проблем.
Для Google крайне важно свести к минимуму затраты, связанные с вычислениями, стремясь по возможности находить наиболее эффективные решения.
Зачем выбирать JavaScript для генерации контента на стороне клиента, тем самым потенциально увеличивая вычислительную нагрузку для Google при сканировании ваших веб-страниц?
По этой причине, когда это возможно, вам следует придерживаться HTML.
Таким образом, вы не ухудшите свои шансы при использовании любого сканера.
4. Улучшите скорость страницы
Гугл говорит:
Возможность Google исследовать ваш веб-сайт ограничена такими факторами, как пропускная способность, время и количество доступных экземпляров робота Googlebot. Обеспечивая более быструю реакцию вашего сервера, вы можете помочь нам более эффективно получать доступ к большему количеству страниц вашего сайта.
Использование рендеринга на стороне сервера действительно полезно для повышения скорости страницы, однако крайне важно оптимизировать основные показатели Web Vital, особенно время ответа сервера, чтобы обеспечить бесперебойную работу пользователей.
5. Позаботьтесь о своих внутренних ссылках
Когда Google проверяет веб-страницу, он сканирует URL-адреса, отображаемые на этой странице. Важно отметить, что каждый отдельный URL-адрес рассматривается сканером как уникальная страница.
Чтобы обеспечить единообразие на вашем веб-сайте, направьте все внутренние ссылки, особенно в навигации, на вариант URL-адреса вашего сайта «www». Аналогичным образом убедитесь, что неканонические версии (без «www») также ссылаются на версию «www», чтобы избежать дублирования и потенциальных проблем с SEO.
Частой ошибкой, которую следует избегать, является забывание включить в URL закрывающую косую черту. Убедитесь, что все используемые вами внутренние ссылки также содержат косую черту, если ваши URL-адреса заканчиваются ею.
Если веб-сайт без необходимости перенаправляется с «https://www.example.com/sample-page» на «https://www.example.com/sample-page/», это вызовет два отдельных сканирования для каждого URL-адреса, что приведет к к увеличению рабочей нагрузки и неэффективности процесса сканирования веб-страниц.
Крайне важно убедиться, что на страницах с внутренними ссылками нет разрывов, поскольку они могут потреблять ваш бюджет сканирования и создавать мягкие страницы 404 (не найдено). Проще говоря, важно убедиться, что все ссылки на вашем веб-сайте ведут на работающие страницы, чтобы не тратить впустую выделенное для сканирования веб-страницы или не отображать страницы с ошибками, когда связанная страница не может быть найдена.
И если этого было недостаточно, они еще и навредили вашему пользовательскому опыту!
В данном случае я опять же за использование инструмента для аудита сайта.
Эти инструменты — Website Auditor, Screaming Frog, Lumar, Oncrawl и SE Ranking — являются отличными вариантами для проведения тщательного анализа веб-сайта.
6. Обновите карту сайта
Опять же, позаботиться о вашей XML-карте сайта — это действительно беспроигрышный вариант.
Ботам будет намного лучше и легче понять, куда ведут внутренние ссылки.
Используйте только те URL-адреса, которые являются каноническими для вашей карты сайта.
Также убедитесь, что он соответствует последней загруженной версии robots.txt и загружается быстро.
7. Внедрите код состояния 304.
Когда робот Googlebot обращается к URL-адресу, он включает заголовок «If-Modified-Since» с датой предыдущего посещения этого конкретного URL-адреса, предоставляя дополнительную информацию о том, когда он в последний раз проверял эту конкретную ссылку.
Если информация на вашей веб-странице остается неизменной с даты, указанной в «If-Modified-Since», вы можете передать сообщение о состоянии «304 Not Modified», не отправляя никакого тела ответа. Этот сигнал указывает поисковым системам, что содержимое страницы не было обновлено, что позволяет роботу Googlebot использовать ранее сохраненную версию файла при следующем посещении.
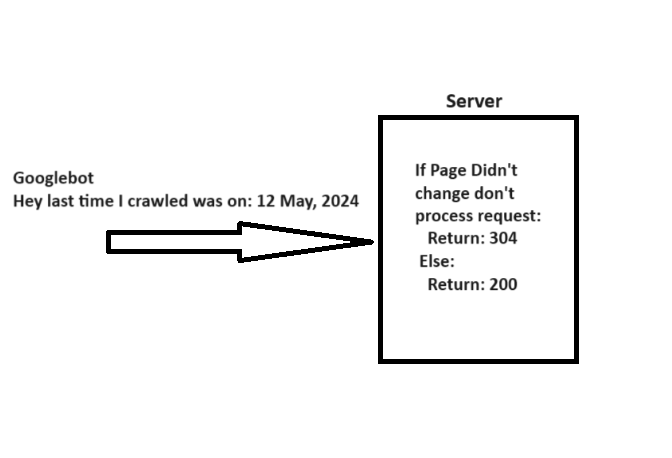
Однако при реализации кода состояния 304 есть предостережение, на которое указал Гэри Иллис.
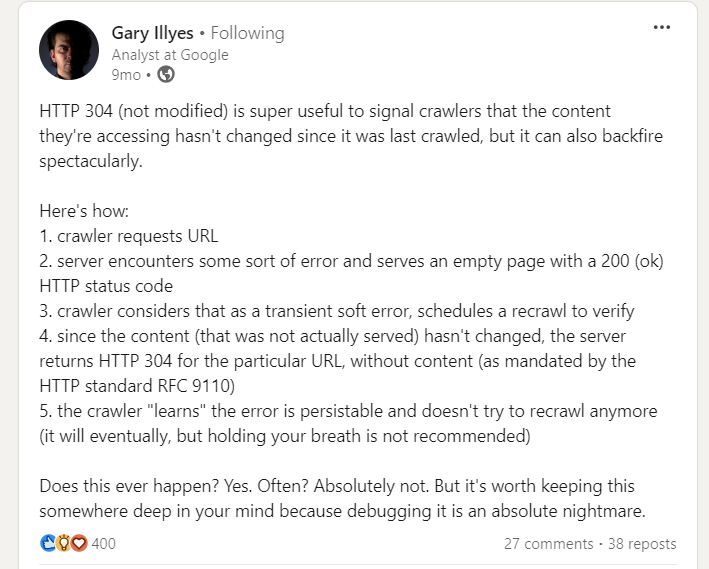
соблюдайте осторожность. Пустые страницы, возвращаемые серверами со статусом 200 во время ошибок сервера, могут помешать сканерам выполнить повторное сканирование, что со временем приведет к постоянным проблемам с индексацией.
8. Теги Hreflang жизненно важны
Чтобы проанализировать различные языковые версии ваших веб-страниц, сканеры используют теги hreflang. Очень важно четко информировать Google о различных локализованных версиях ваших страниц.
Сначала поместите следующий HTML-код в заголовок вашей веб-страницы:
При указании URL-адреса рекомендуется использовать тег «
9. Мониторинг и обслуживание
Следите за журналами своего сервера и отчетом о статистике сканирования в консоли поиска Google, чтобы обнаружить любые необычные действия при сканировании и выявить потенциальные проблемы.
Если вы наблюдаете регулярное увеличение количества сканирований страниц 404, в большинстве случаев это может быть связано с проблемой, известной как бесконечное пространство для сканирования (тема, которую мы уже рассматривали ранее), или это может сигнализировать о других потенциальных проблемах, с которыми может столкнуться ваш веб-сайт.
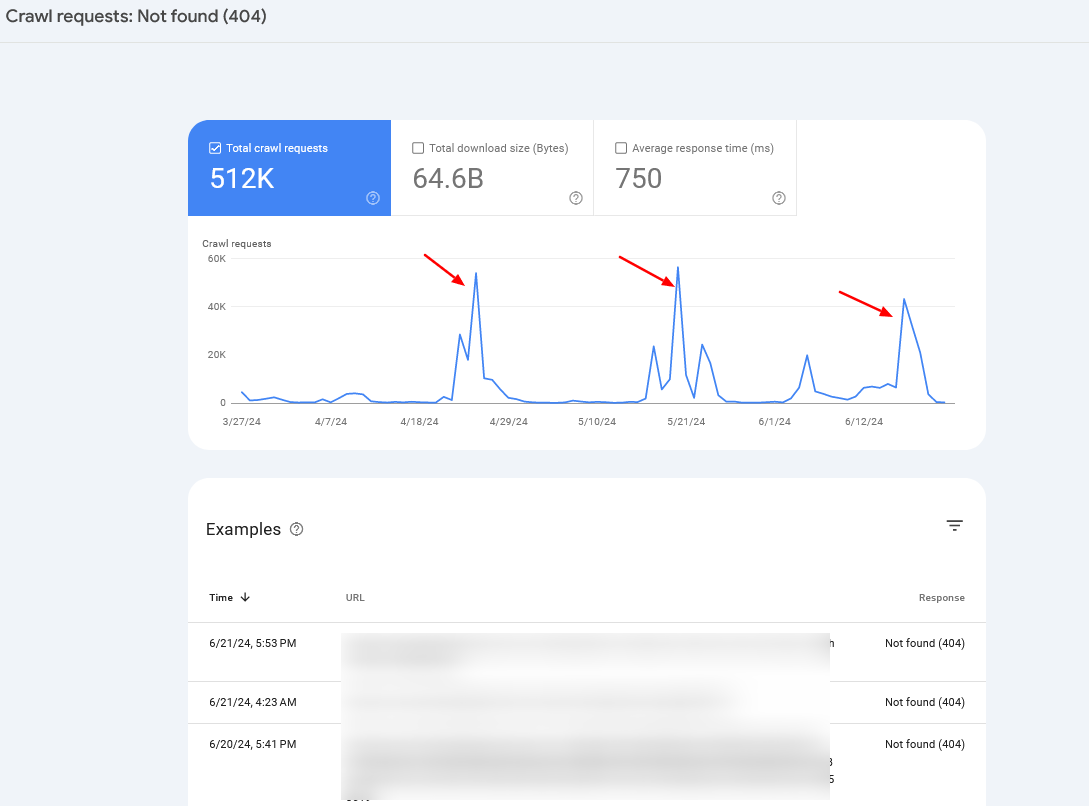
Иногда может быть полезно объединить данные журнала сервера со статистикой Search Console, чтобы точно определить основную проблему.
Краткое содержание
Действительно, если вы размышляли над актуальностью оптимизации краулингового бюджета для вашего сайта, ответ, несомненно, будет утвердительным.
Концепция краулингового бюджета всегда должна быть ключевым фактором для каждого специалиста по SEO, как это было в прошлом и, вероятно, останется таковым в будущем.
Вполне вероятно, что эти предложения помогут вам увеличить бюджет сканирования и повысить эффективность SEO. Однако имейте в виду, что тот факт, что страницы сканируются, не означает, что они автоматически будут проиндексированы.
Смотрите также
- Результаты поиска Google более персонализированы?
- Обзоры искусственного интеллекта Google избегают политического контента, показывают новые данные
- Налоговое Обложение Криптовалюты в Кении: Рецепт Цифрового Катастрофы или Всего Лишь Налогообложения?
- Анализ динамики цен на криптовалюту BTC: прогнозы биткоина
- Анализ динамики цен на криптовалюту ETH: прогнозы эфириума
- Акции PHOR. ФосАгро: прогноз акций.
- Прогноз нефти
- Коварные крипто-законопроекты — переживут ли ваши монеты?
- Акции DATA. Группа Аренадата: прогноз акций.
- ИИ-пауки, по сообщениям, истощают ресурсы сайта и искажают аналитику.
2024-09-19 14:10





