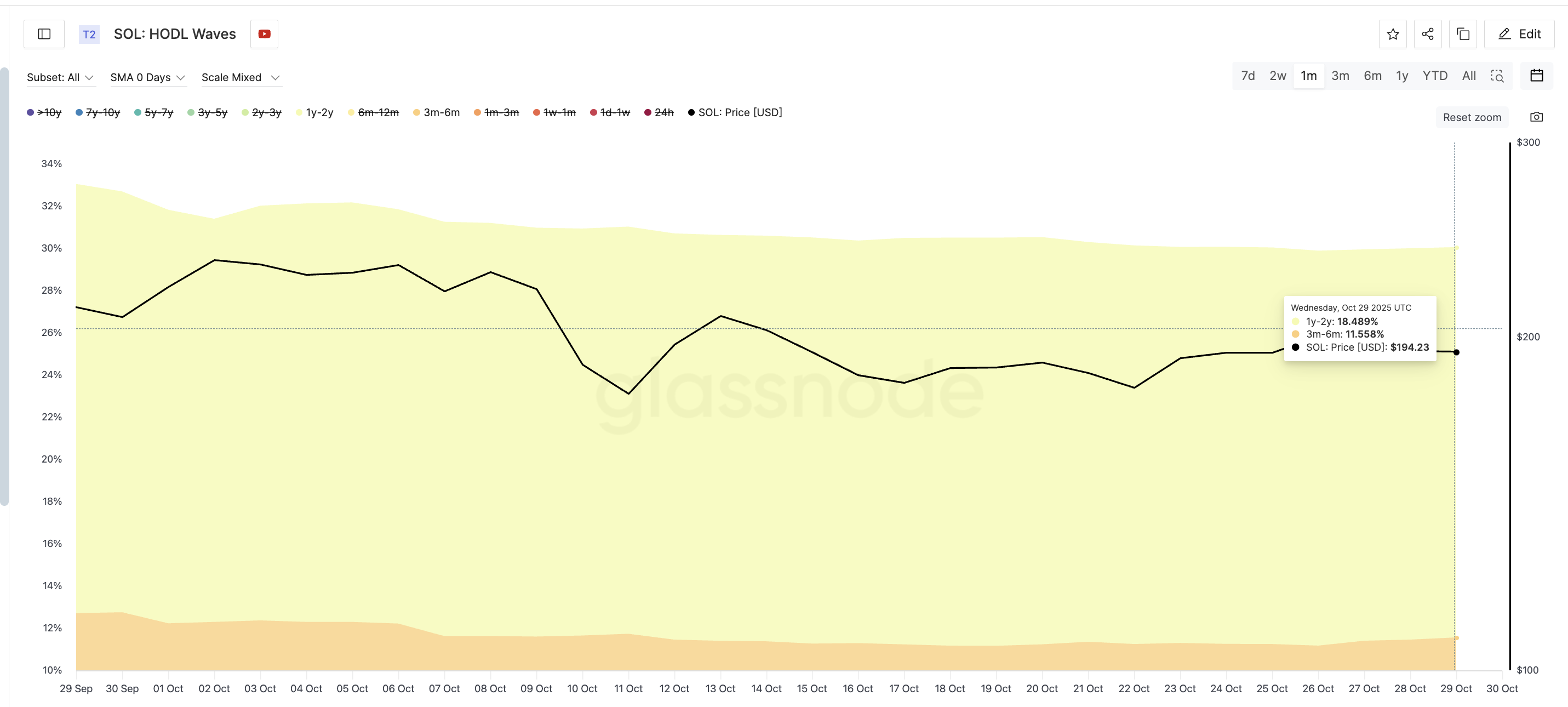
Недавнее исследование, проведённое Anthropic, изучило, насколько хорошо Claude 3.5 Haiku обрабатывает переносы строк при написании текста заданной ширины – задача, требующая отслеживания своего прогресса. Удивительно, но исследователи обнаружили, что модель развивает внутренние паттерны, похожие на то, как люди понимают и ориентируются в пространстве, что указывает на форму пространственного восприятия.
Андреас Волпини поделился полезной идеей в Twitter об этом исследовании, сравнивая его с разбивкой информации на более мелкие части для ИИ. В более общем смысле, его мысль иллюстрирует, как и писатели, и системы ИИ справляются с организацией – обоим необходимо создавать четкие связи между различными частями текста, чтобы сделать его понятным.
Эта статья не посвящена чтению текста; вместо этого в ней исследуется, как создавать текст и решать, где начинать новые строки, чтобы он соответствовал определенной ширине. Мы сделали это, чтобы лучше понять, как большие языковые модели управляют такими вещами, как положение текста, выбор слов и переносы строк во время написания.
Исследователи разработали тест, в котором модель ИИ, Claude 3.5 Haiku, должна была писать текст, соответствующий определенной длине строки. Это помогло им понять, как модель выбирает слова, чтобы оставаться в пределах этих ограничений, и решает, где начать новую строку. По сути, модели нужно было отслеживать, сколько места осталось на каждой строке по мере написания.
Этот эксперимент показывает, что языковые модели могут изучать базовую структуру текста, просто распознавая закономерности, без необходимости специального программирования или руководства.
The Linebreaking Challenge
Эта задача ставит перед моделью задачу определить, поместится ли следующее слово на текущей строке или потребуется новая строка. Для успешного выполнения этой задачи модели необходимо понимать концепцию ширины строки – ограниченного пространства, доступного на каждой строке, аналогичного физической странице. Это требует от модели отслеживания количества написанных символов, расчета оставшегося пространства и затем принятия решения, поместится ли следующее слово. Это сложная задача, требующая рассуждений, памяти и планирования. Исследователи использовали специальные диаграммы, называемые графами атрибуции, чтобы понять, как модель обрабатывает эти вычисления, обнаружив, что она использует отдельные внутренние механизмы для отслеживания количества символов, предстоящего слова и того, когда необходим перенос строки.
Непрерывный подсчёт
Исследователи обнаружили, что Claude 3.5 Haiku не считает символы по одному. Вместо этого, он воспринимает их как непрерывную, изогнутую форму, позволяя плавно следовать за положением текста при чтении, а не обрабатывая каждый символ по отдельности.
Интересно, что исследователи обнаружили, что ИИ-модель разработала конкретный компонент, называемый ‘attention head’ (головка внимания), предназначенный для определения конца каждой строки. Attention heads — это части ИИ, которые фокусируются на самом важном в тексте. Эта конкретная головка была специализирована на простом обнаружении, где заканчивается строка.
Ключевым аспектом того, как мы отслеживаем количество символов, является то, что конкретный элемент, ‘граничная голова’, тонко сдвигает данные. Это позволяет связать каждое количество с немного более высоким, предполагая, что они находятся рядом друг с другом. По сути, существует способ сдвинуть кривую количества символов вдоль самой себя. Такой вид движения невозможен в типичных, сильно изогнутых представлениях линий или окружностей, как в нашей первоначальной модели. Однако мы наблюдаем это как в структуре, которую мы обнаружили в данных Haiku, так и, как мы продемонстрируем, в построении Фурье, которое мы используем.
Как работает Boundary Sensing
Исследователи обнаружили, что Claude 3.5 Haiku может предсказывать, когда приближается к концу фрагмента текста, анализируя два внутренних индикатора.
- Сколько персонажей он уже сгенерировал, и
- Как долго предположительно должна быть очередь.
Механизм внимания определяет наиболее важные части текста. Определенные части этого механизма специально разработаны для прогнозирования, когда строка приближается к своей максимальной длине. Они работают, тонко регулируя способ отслеживания моделью количества символов и ширины строки. Когда эти два значения приближаются, модель приоритизирует добавление переноса строки.
Модель определяет, когда она приближается к концу строки, проверяя количество обработанных символов и общую ширину строки. Она делает это, используя определенные части своей внутренней обработки – называемые attention heads – которые предназначены для распознавания закономерностей в этих подсчетах. Эти части по сути ‘выравнивают’ текущий подсчет символов с шириной строки, давая сильный сигнал, когда разница между ними находится в определенном диапазоне. Комбинируя информацию из нескольких таких частей, каждая из которых смотрит на немного разные смещения, модель может точно предсказать, сколько символов осталось до конца строки.
Финальная Стадия
К этому моменту модель знает, насколько близко она находится к концу строки и сколько букв будет в следующем слове. Последний шаг — просто применить эти знания.
Последняя часть определения того, где разбивать строки, включает в себя проверку, поместится ли предсказанное следующее слово перед окончанием строки. Если оно не поместится, строку необходимо разбить.
Исследователи обнаружили, что модель имеет внутренние механизмы, которые определяют, когда новое слово сделает строку слишком длинной. Эти механизмы действуют как границы, увеличивая вероятность переноса строки. И наоборот, другие внутренние функции активируются, когда слово *действительно* помещается, что делает перенос строки менее вероятным. По сути, модель предсказывает переносы строк, основываясь на том, насколько близко она находится к достижению лимита строки.
Эти две противоборствующие силы – одна поощряющая перенос строки, а другая предотвращающая его – работают вместе, чтобы определить конечный результат.
Модели могут иметь визуальные иллюзии?
Затем исследование приобрело интересный оборот, когда ученые протестировали, можно ли обмануть модель с помощью визуальных иллюзий, как и людей. Они начали с изучения иллюзий, где линии равной длины кажутся разными из-за обманчивых перспектив, из-за чего одна кажется короче другой.
Скриншот визуальной иллюзии

Чтобы понять, как ИИ-модель отслеживает информацию, исследователи добавили специальные искусственные символы. Эти символы запутались во внутренней системе модели для понимания порядка, создавая ошибки, очень похожие на то, как визуальные иллюзии обманывают наши глаза. Чувство модели относительно того, где начинаются и заканчиваются строки и разделы, стало искажённым, демонстрируя, что она полагается на контекст и полученную информацию для понимания структуры. По сути, даже если эти ИИ-модели не «видят» так, как люди, они могут испытывать внутреннюю путаницу, аналогичную тому, как наш мозг неправильно интерпретирует визуальную информацию.
Наше исследование показывает, что это изменение влияет на следующее предсказанное моделью слово, в частности, мешая её способности предсказывать новые строки. Как мы и ожидали, определенные части модели отвлекаются. При использовании исходного запроса эти части были сосредоточены на переходе с одной строки на другую. Однако, с измененным запросом, они также начинают сосредотачиваться на символах ‘@@’.
Исследователи хотели узнать, оказывают ли конкретные символы, которые они использовали, уникальное воздействие, или любые случайные символы могут вызвать проблемы для модели. Они протестировали 180 различных последовательностей символов и обнаружили, что большинство из них не мешают способности модели предсказывать, где должны быть переносы строк. Они обнаружили, что только ограниченное количество символов – те, которые обычно встречаются в коде – способны запутать модель и нарушить её внутренний процесс подсчёта.
LLMs Имеют визуально-подобное восприятие текста.
Это исследование демонстрирует, как характеристики текста преобразуются в организованные, похожие на карты структуры внутри языковой модели. Важно отметить, что оно предполагает, что эти модели не просто обрабатывают слова как символы — они фактически строят внутренние представления, подобные тому, как мы воспринимаем мир. Самым убедительным я считаю то, что исследователи последовательно проводят связь между тем, что происходит внутри модели, и тем, как люди воспринимают. Их аналогии с человеческим восприятием неоднократно оказываются актуальными для внутреннего устройства модели.
Они пишут:
Мы часто говорим, что первые части языковых моделей преобразуют текст в понятные фрагменты, но точнее будет думать об этом как о *восприятии* входных данных моделью. Подобно тому, как начальные слои моделей зрения обрабатывают базовую визуальную информацию, первые части языковой модели сосредоточены на восприятии и понимании самого текста.
Шаблоны, которые мы наблюдаем в этих алгоритмах, удивительно похожи на то, как мозг обрабатывает информацию. В частности, то, как эти шаблоны расширяются, чтобы обрабатывать всё больше и больше данных, перекликается с тем, как наш мозг представляет числа – расширяясь, чтобы охватить большие количества. Способ организации этих шаблонов также напоминает общие принципы работы мозга. Хотя сравнения не точны, мы считаем, что более тесное сотрудничество между исследователями, изучающими искусственный интеллект и нейронауку, может привести к ценным новым открытиям.
Последствия для SEO?
Артур К. Кларк однажды сказал, что высокоразвитые технологии кажутся магией. Однако я считаю, что как только мы понимаем *как* работает технология, она становится менее загадочной. Не все знания должны быть практическими, но понимание того, как большие языковые модели (LLMs) обрабатывают информацию, ценно, потому что это устраняет ‘магию’ и делает её более доступной. Улучшит ли это исследование ваши навыки SEO? Да, предоставив нам более глубокое понимание того, как языковые модели структурируют и интерпретируют контент, делая его менее ‘чёрным ящиком’ и более понятным.
Прочитайте об исследовании здесь:
Когда Модели Манипулируют Многообразиями: Геометрия Задачи Подсчета
Смотрите также
- Анализ динамики цен на криптовалюту NEXO: прогнозы NEXO
- Какой самый низкий курс доллара к швейцарскому франку?
- Какой самый низкий курс доллара к венгерскому форинту?
- Какой самый низкий курс евро к венгерскому форинту?
- Анализ динамики цен на криптовалюту TAO: прогнозы TAO
- Какой самый низкий курс евро к юаню?
- Анализ динамики цен на криптовалюту RENDER: прогнозы RENDER
- Акции UNAC. Объединенная авиастроительная корпорация: прогноз акций.
- Анализ динамики цен на криптовалюту ALGO: прогнозы ALGO
- 25 Альтернативных Поисковых Систем, Которые Вы Можете Использовать Вместо Google
2025-10-30 13:41