Я недавно вернулся из поездок в Сан-Диего и Торонто, где мне посчастливилось выступить на Ahrefs Evolve и SEO IRL – оба мероприятия были отличными! Было здорово встретить так много подписчиков Growth Memo там. Спасибо всем, кто посетил!

Недавно я проводил трехчасовую дискуссионную группу с лидерами из Redfin, Angi, Clickup, Glean и Ourplace, находясь в Сан-Диего. Я обязательно сообщу вам, если планирую проводить подобные мероприятия в будущем.
Мы недавно опубликовали крупное исследование о том, как люди используют AI Mode, и результаты были поразительными.
- Как режим ИИ влияет на показатели кликабельности и SEO-трафик?
- Используют ли люди вообще Режим ИИ?
- Точны ли ответы в режиме AI?
- Чем похожи AI Overviews и AI Mode? Чем они отличаются?
- Могут ли бренды по-прежнему извлекать выгоду из получения видимости в режиме AI, даже если кликов мало (или их нет совсем)?
Этот отчет суммирует все ключевые исследования по AI Mode за 2025 год. Это всесторонний обзор, поэтому хорошей идеей будет сохранить его – вас, вероятно, скоро попросят об этой информации коллеги или заинтересованные стороны, если этого еще не произошло.
(Если я упустил какие-либо крупные исследования или тесты, напишите мне в личные сообщения.)
1. Как режим ИИ влияет на кликабельность и SEO-трафик?
Вот что мы знаем наверняка: AI Mode значительно снижает количество внешних кликов.
Мои исследования, включая исследования, тесты и новые данные, последовательно подтверждают этот вывод.
Мы живём в этой реальности прямо сейчас – и не можем себе позволить её игнорировать.
Как SEO-эксперт, я наблюдаю тревожную тенденцию: многие веб-сайты достигают плато по органическому трафику, и некоторые даже испытывают снижение, *несмотря* на последовательную работу над своим SEO. Честно говоря, я ожидаю, что ситуация ухудшится, когда Google полностью развернет свой поисковый опыт на базе искусственного интеллекта. Нам нужно адаптировать наши стратегии сейчас, чтобы не потерять позиции.
Трафик действительно циркулирует в определенных случаях.
В отчёте за прошлую неделю об исследовании удобства использования AI Mode я обнаружил, что когда пользователи спрашивали о покупках, они почти всегда нажимали на результаты. Однако, когда они спрашивали о других вещах – задачах, не связанных с совершением покупки – они почти никогда не нажимали.
Исследования Propellic показали, что пользователи оставались вовлечены в работу с AI-ассистентом около 104 секунд при планировании своих поездок. Однако, как только они определились с планом, они быстро перешли на сайты бронирования, потратив около 38 секунд, прежде чем уйти, чтобы завершить бронирование.
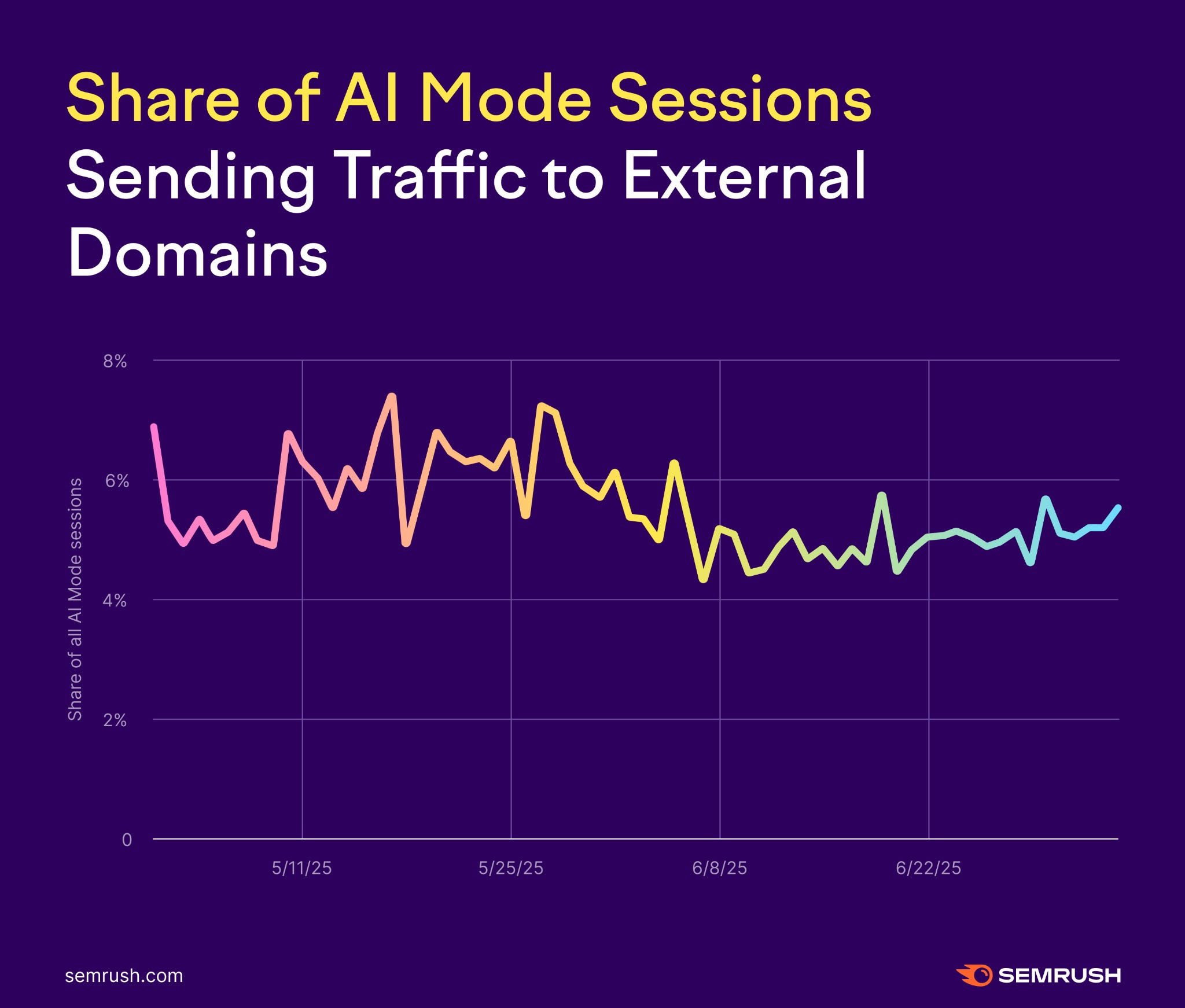
Режим AI не только ускоряет поиск с меньшим количеством кликов, но и значительно сокращает время поисковых сессий. Данные Semrush показывают, что сессии с использованием режима AI обычно включают всего два или три поиска, по сравнению с примерно пятью в традиционном поиске [3]. Это означает, что потенциально меньше возможностей для привлечения трафика и повышения видимости.
Подразумение:
- Ожидайте значительно более низкий показатель кликабельности (CTR) в режиме AI по сравнению с классическими синими ссылками в поисковой выдаче (SERP).
- Вместо трафика думайте в терминах узнаваемости бренда и влияния пользователей в AI Mode.
- Для оценки эффективности переключите своё внимание с CTR на упоминания бренда, время пребывания на странице и конверсию на финальном, самом целевом этапе.
2. Используют ли исследователи режим ИИ?
Исследования в нашей отрасли в этом году показывают, что пользователи, по крайней мере на данный момент, медленно принимают AI Mode.
Google, похоже, полна решимости приучить пользователей к использованию поиска на основе искусственного интеллекта, добавляя такие функции, как AI Mode в Chrome и непосредственно на страницах результатов поиска. Эта стратегия в конечном итоге может сократить время, которое люди тратят на просмотр традиционных результатов поиска или клики по рекламе, но Google продолжает двигаться вперед. Как я подробно описал в Growth Intelligence Brief #8,
Итак, будьте готовы. Похоже, все пути ведут к AI Mode, нравится это пользователям или нет.
Недавнее исследование iPullRank, изучающее поведение пользователей с функциями искусственного интеллекта, показало, что AI Mode использовался небольшим процентом участников – от 2% до 5% – при выполнении пяти различных задач. В отличие от этого, гораздо большая группа – от 30% до 47% – активно использовала AI Overviews.
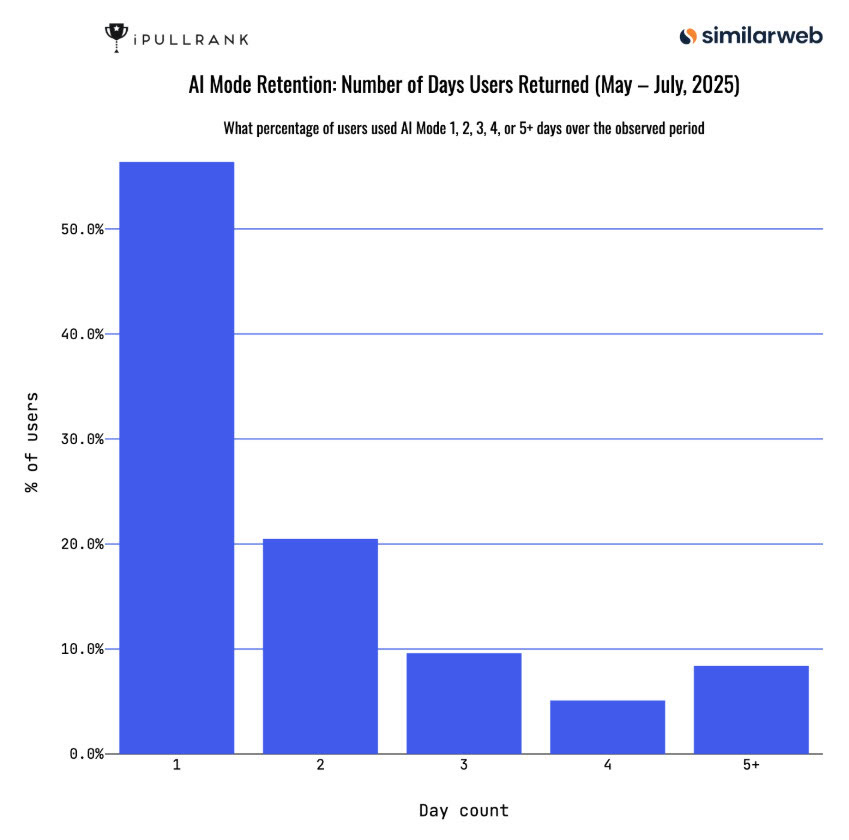
Непосредственно перед публикацией своих исследований, iPullRank проанализировал данные из Similarweb и обнаружил, что более половины пользователей попробовали функцию AI Mode, но затем сразу же покинули сайт [4].
В ходе исследования iPullRank AI Mode пользователи, которые пробовали сгенерированные ИИ ответы, часто просто читали их, не переходя по каким-либо ссылкам или изучая информацию дальше.
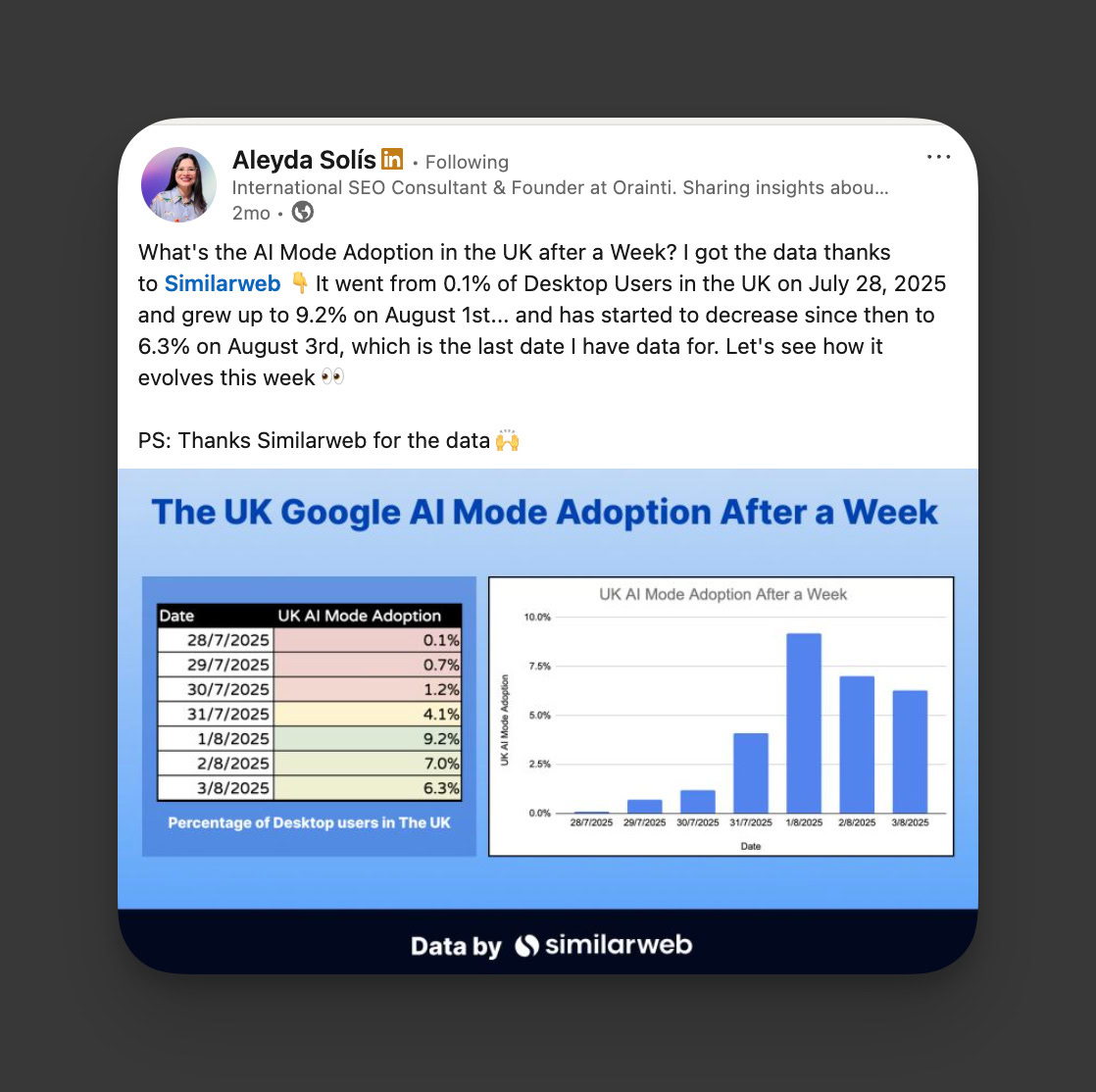
Также, Алейда Солис отметила в августе, что интерес к AI Mode в Великобритании снизился после первоначального всплеска любопытства после его выпуска.
Понятно, что Google не спешит выпускать AI Mode для всех – технология пока не удовлетворяет явную потребность на рынке.
Предположение:
- Есть большая вероятность, что AI Mode эволюционирует до более широкого развертывания. Основываясь на наших и исследованиях других, больше встроенных ссылок и, возможно, прямая интеграция с магазинами могут быть в плане развития.
- По мере развития AI Mode нам потребуется больше исследований, чтобы понять его влияние на маркетинг. Однако я не думаю, что мы увидим будущее, в котором AI Mode внезапно начнет отправлять значительные объемы трафика.
- Вероятно, у нас есть некоторое время, прежде чем Google усилит внедрение AI Mode в результаты поиска. Нам следует использовать это время для настройки телеметрии, чтобы измерить и оптимизировать наше присутствие в AI Mode.
3. Насколько точны ответы режима ИИ?
Точность режима ИИ варьируется в зависимости от типа запроса. Может ли это быть причиной медленного внедрения пользователями?
Несмотря на то, что всё ещё есть вероятность получения неверной или вымышленной информации, последние исследования показывают, что люди в целом доверяют результатам, которые они получают в определенных областях.
Люди, протестировавшие AI-функции Propellic, дали очень положительные оценки ответам, в среднем 4.3 из 5 по шкале доверия. Тестировщики особенно отметили, насколько легко и быстро AI представлял информацию о таких вещах, как мероприятия и отели.
Исследование удобства использования, проведенное Nielsen Norman Group (NNG), показало, что люди ценят использование AI-чатботов для сложных поисков. Исследование продемонстрировало, что генеративный AI помог сэкономить время, быстро обобщая информацию для этих задач.
Несмотря на использование новой системы, участники исследования NNG всё ещё проверяли информацию с помощью традиционных поисковых систем, что говорит о том, что они не были полностью убеждены в результатах.
Другие исследования подчеркивают неточности и пробелы в AI Mode:
Люди, участвовавшие в тестах iPullRank и искавшие местные новости или медицинские клиники, обнаружили, что результаты, основанные на искусственном интеллекте, были недостаточно точными или подробными. В итоге они использовали обычные веб-сайты или карты вместо этого.
Ahrefs провёл небольшой тест, в котором Патрик Стокс опубликовал статьи, написанные ИИ, на темы технического SEO. Эти статьи намеренно включали неверную информацию, чтобы проверить, смогут ли они ранжироваться в результатах поиска Google. К сожалению, ни одна из трёх тестовых страниц не заняла позиции по своим целевым ключевым словам, что говорит о том, что контент, сгенерированный ИИ, может не соответствовать стандартам Google в отношении опыта, знаний, авторитетности и надёжности (EEAT).
Импликация:
- Пользователи в целом доверяют AI Mode и ответам AI на других платформах. Ответы могут быть очень надёжными для некоторых поисковых запросов с высокой покупательской заинтересованностью и информационных запросов, но они могут содержать неточности или нежелательную локализацию.
- Пользователи и маркетологи должны рассматривать ответы ИИ как отправные точки, перепроверяя критически важную информацию и учитывая авторитет бренда и проверку фактов.
- Существует риск для бренда, присущий LLM, таким как AI Mode. Злоумышленники могут использовать все еще развивающуюся и простую функциональность LLM для распространения лжи о брендах в сети и создания негативного отношения к бренду. Это то, что вам следует отслеживать с помощью трекеров AI visibility.
4. Чем похожи обзоры с помощью ИИ и режим ИИ? Чем они отличаются?
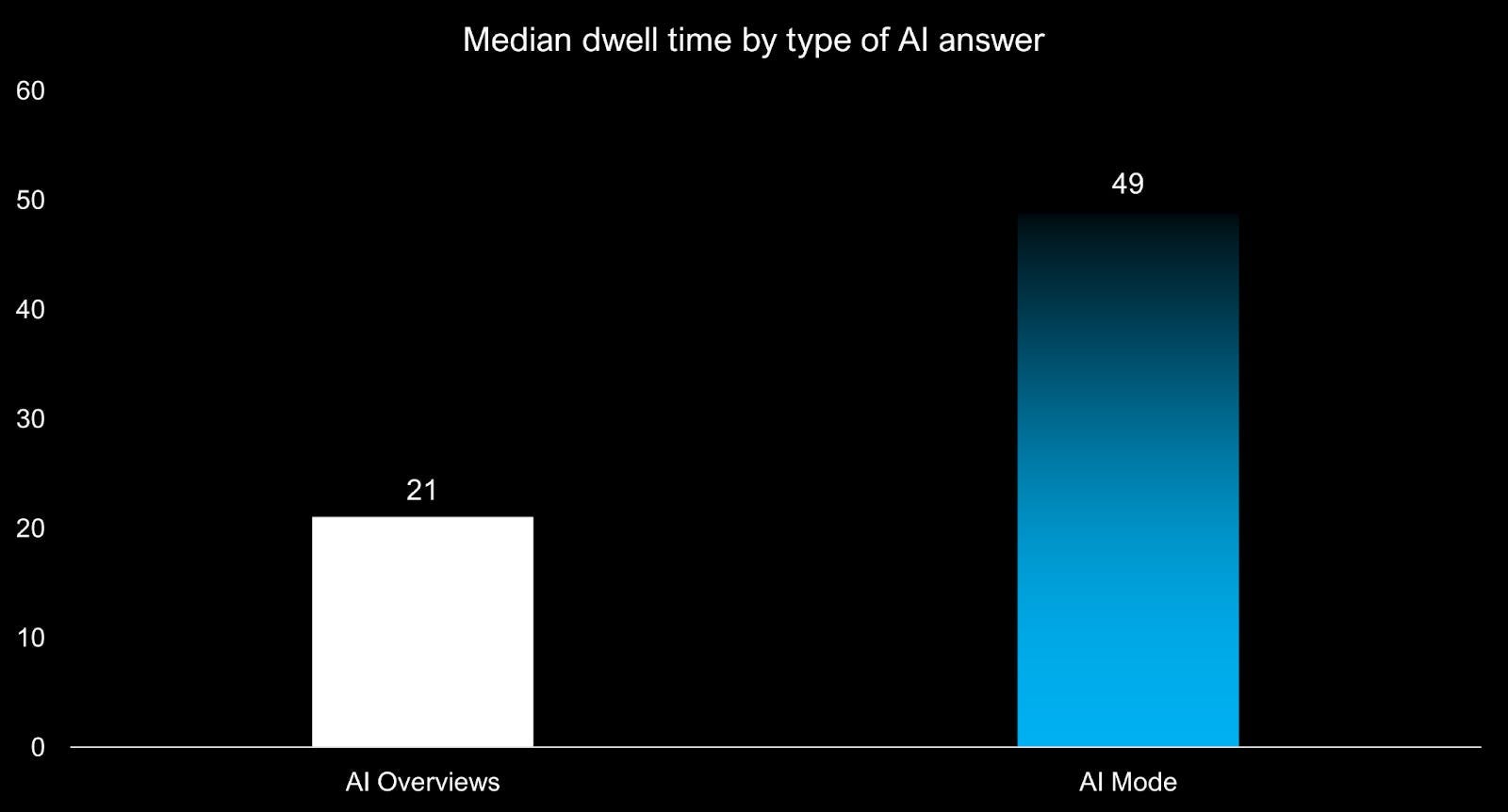
Наши исследования показывают, что люди используют AI Overviews для быстрого поиска фактов, в то время как AI Mode привлекает их внимание гораздо дольше. В среднем, пользователи тратят в два раза больше времени на взаимодействие с AI Mode по сравнению с AI Overviews.
Недавнее исследование, проведенное iPullRank, показало, что люди часто не уверены в разнице между AI Mode и AI Overviews, и, как правило, не нажимали на опцию, чтобы узнать больше об AI Mode.
Игнорируя общую сложность, с которой сталкиваются пользователи, исследование AI Mode 2025 и мой обзор 19 связанных исследований имеют две ключевые находки:
- Влияние бренда: Видимость как в AIO, так и в AI Mode зависит от сильных сигналов авторитетности, таких как узнаваемость бренда, качественный ссылочный профиль и качественный контент.
- Ограниченный трафик: Оба опыта приводят к уменьшению количества кликов. Исследования AIO показали снижение CTR, в то время как сеансы в режиме AI подавляюще имеют нулевое количество кликов.
Различия?
- Длина и стиль контента: Исследование сравнения Semrush показывает, что AI Mode генерирует более длинные ответы (~300 слов), аналогично ChatGPT, и использует больше уникальных доменов (~7 на ответ), чем AI Overviews (~3).
- Взаимодействие с пользователем: Режим ИИ доступен через отдельный режим (или панель – по крайней мере, на данный момент) и предлагает общение в стиле чата, предварительный просмотр продуктов, локальные пакеты и бизнес-профили. AIOs появляются встроенными в классический поиск и вопросы «Люди также спрашивают» и редко включают интерактивные функции (по состоянию на дату написания этого текста – мы видим появление большего количества интерактивных функций, которые переносят пользователей в Режим ИИ).
- Частота срабатывания: AIО не срабатывают постоянно, хотя Google увеличил их внедрение в поисковые запросы за последний год. AI Mode может быть вызван пользователем или автоматически заполнен для более длинных, беседных запросов.
Подразумеваемое:
- Для оптимизации рассматривайте их как два отдельных канала с перекрывающимися, но различными сигналами. Вам необходимо отслеживать и контролировать оба!
- На данный момент, AI Overviews предоставляют отправную точку для AI Mode. В результате, существует вероятность того, что запросы, показывающие AI Overviews, потеряют еще больше кликов со временем, поскольку пользователи переходят в AI Mode. Чем больше потерь трафика вы видите по каждому запросу, тем больше внимания следует уделить AI Mode.
5. Могут ли бренды все еще извлечь выгоду из видимости в режиме AI, даже если кликов мало?
Абсолютно – сам факт просмотра результатов, созданных искусственным интеллектом, влияет на мнение людей, даже если они не переходят по ссылкам. Мы знаем это, потому что исследования последовательно показывают, что пользователи читают ответы, сгенерированные ИИ, изучают предоставленные источники и формируют собственные выводы непосредственно в результатах поиска Google.
Я часто слышу от своих клиентов: «Если Google начнет отображать результаты, сгенерированные искусственным интеллектом, и трафик на наш сайт уменьшится, как мы можем определить, эффективны ли наши маркетинговые усилия?»
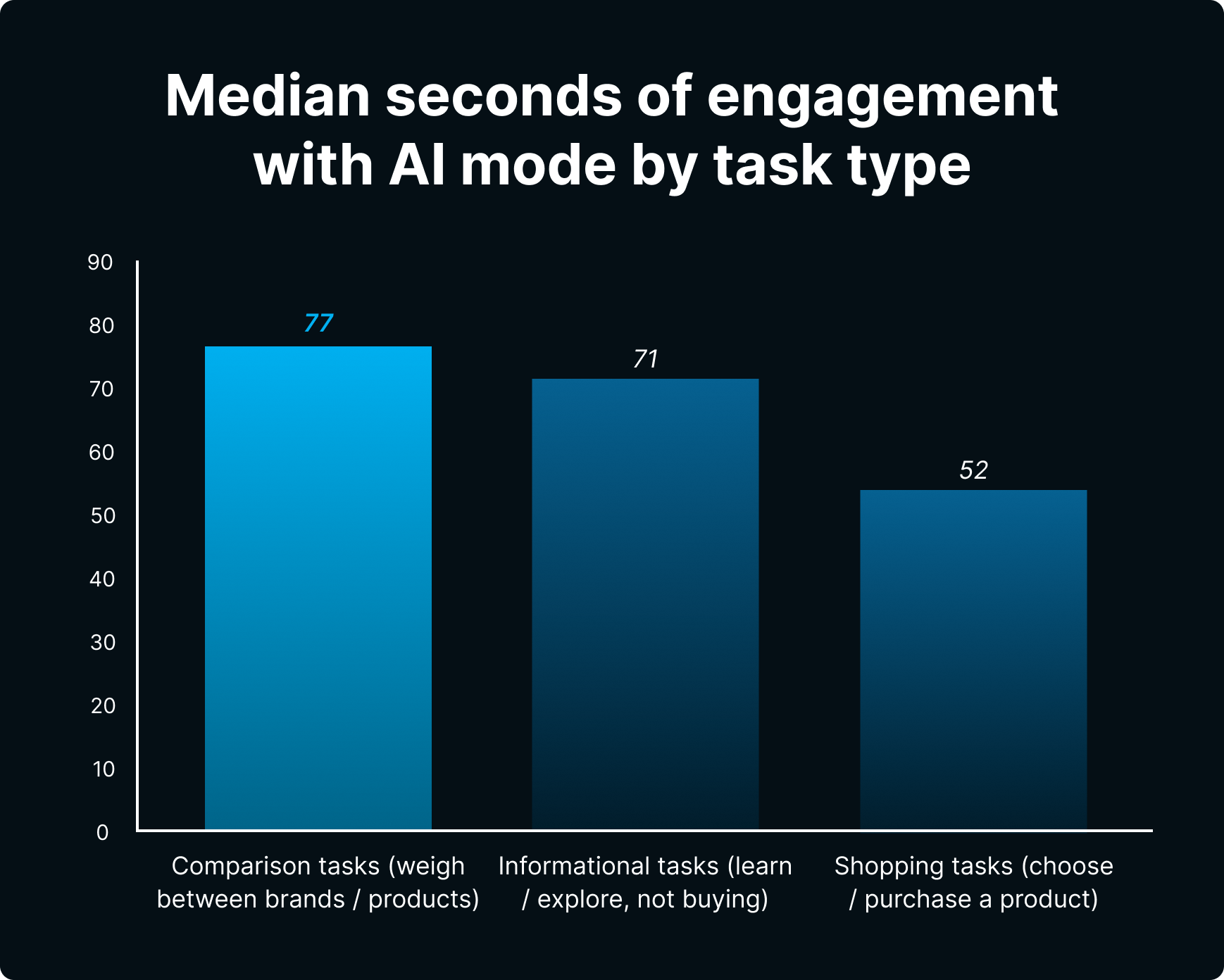
Недавнее исследование нашего AI Mode показало, что люди обычно тратили от 52 до 77 секунд на просмотр ответов AI для каждой задачи и часто заканчивали свои исследования прямо там. Для сравнения, данные от Propellic’s travel research указывают на то, что пользователи тратят около 104 секунд на планирование с помощью AI Mode, прежде чем перейти на другой веб-сайт для бронирования своей поездки.
Когда люди говорят о брендах в рамках наших AI-powered experiences, и эти бренды имеют высокие рейтинги доверия (около 4.3 из 5), это говорит о том, что эти бренды воспринимаются как заслуживающие доверия и влиятельные.
Люди бросали взгляды на ссылки внутри текста, сноски и превью продуктов, но не часто переходили по ним с текущей страницы, если только они активно не пытались что-то купить.
Мы также обнаружили, что знакомство с брендом существенно влияет на принятие решений.
Как SEO-эксперт, я постоянно вижу, что люди склонны придерживаться хорошо известных брендов, даже если существуют альтернативы. Это означает, что просто *появляться* в результатах поиска – даже если кто-то не нажимает на вашу ссылку сразу – невероятно ценно. Это поддерживает ваш бренд в памяти, и часто приводит к прямым посещениям в будущем, когда они *действительно* будут готовы нажать. Всё дело в создании узнаваемости бренда!
Рассматривайте AI Mode как способ построения вашего бренда. Сосредоточьтесь на том, чтобы быть заметным в контенте, который читает ваша аудитория, а не только на том, чтобы заставить их кликнуть на что-то.
Подразумение:
- Отслеживание и атрибуция решений, принятых в AI Mode, в настоящее время невозможны, но мы знаем из исследований, что это важно. Если/когда AI Mode станет основным поисковым опытом, это значительно изменит наше представление о Поиске.
- Лучшее, что мы можем сделать, — это отслеживать видимость AI Mode (как часто, когда и с каким настроением упоминается наш бренд?) и самооцениваемую атрибуцию.
- Реклама в режиме ИИ предоставит дополнительный уровень видимости, который, как мы надеемся, позволит нам количественно оценить и расставить приоритеты в работе по оптимизации.
Итоговые мысли: Критика существующих исследований режима ИИ (включая мои собственные)
Прежде чем я обсужу, чего еще не хватает в текущих исследованиях, касающихся попадания в функции с поддержкой искусственного интеллекта в 2025 году – и какую работу предстоит проделать для поиска надежных методов достижения этого – я хочу четко заявить следующее:
Я не хочу критиковать какие-либо исследования или людей, которые их провели. Все мы извлекаем выгоду из тяжелой работы и дорогостоящих исследований, которыми делятся эти команды.
Я постоянно впечатлен преданностью моих коллег в области growth marketing их готовностью открыто делиться своими знаниями и опытом. Вдохновляет быть частью этого сообщества.
Действительно кажется, что многие из нас делают эту работу вместе.
Но правда в том, что LLM являются чёрным ящиком на данный момент. И нам предстоит узнать ещё очень многое.
Хотя доступные исследования предлагают ценные сведения, они также имеют ограничения.
Вот краткий обзор. Я делюсь этим, чтобы побудить всех работать вместе и найти способы разблокировать эти ценные ресурсы.
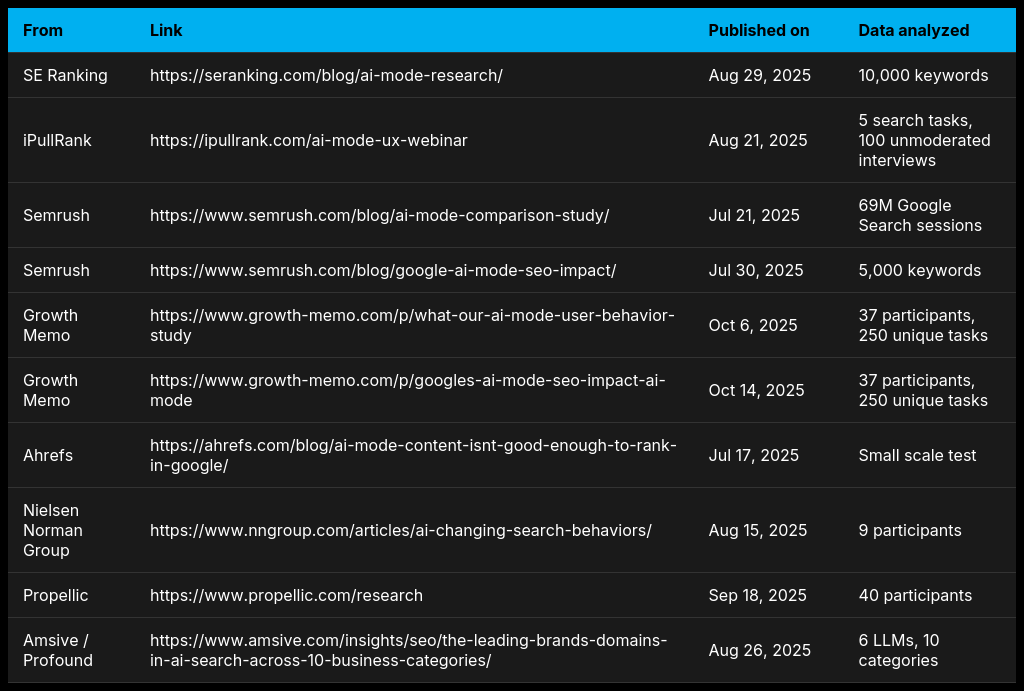
SE Ranking – Режим исследования на основе ИИ
Это исследование проанализировало более 10 000 поисковых запросов в США, изучая, как часто они повторялись в трех различных источниках данных, чтобы понять колебания в результатах поиска. Оно также исследовало типы веб-сайтов, появляющихся в результатах, и то, насколько они соответствуют типичным органическим результатам поиска, предлагая простые способы измерения этих изменений.
Но в исследовании отсутствуют качественные данные пользователей и не оценивается, как часто появляется Режим ИИ.
iPullRank – Исследование UX в режиме AI
Наше исследование включало наблюдение за 100 реальными пользователями, выполняющими различные задачи и делящимися своими мыслями вслух. Мы получили ценные качественные отзывы, особенно о замешательстве пользователей относительно различий между AI Mode и AI Overviews.
Режим ИИ использовался участниками этого исследования нечасто (всего 2-5%), что ограничивает силу некоторых наших выводов. Мы собрали полезные данные о том, как люди ищут в Google с использованием этих новых функций, но у нас нет чёткого представления о том, *как* люди на самом деле используют режим ИИ.
2 исследования Semrush: Режим ИИ против традиционного поиска и других LLM + Раннее внедрение режима ИИ
Данные из обоих исследований убедительны. Однако, для исследования сравнения AI Mode, я хотел бы увидеть исследования, учитывающие более широкий спектр поисковых намерений, помимо традиционных четырех категорий.
Мой недавний последующий анализ майского UX-исследования по поиску на базе ИИ – под названием ‘Trust Still Lives in Blue Links’ – показал, как пользователи все чаще проверяют результаты, сгенерированные ИИ, путем подтверждения информации через традиционные веб-ссылки.
Важно, чтобы все лучше понимали, что люди *действительно* ищут, когда осуществляют поиск в интернете. Более подробные данные и исследования, которые анализируют намерения поиска, были бы очень полезны.
Было бы здорово объединить данные о кликах пользователей с прямыми отзывами, проанализированными по категориям и во времени, чтобы получить более глубокое понимание для наших AI Mode функций.
Рост Мемо – Поведение Пользователей & Влияние на SEO (Части 1 & 2)
Я бы ничего не изменил в исследованиях, которые мы опубликовали о AI Mode за последние несколько недель.
Просто шучу.
Это исследование было сосредоточено исключительно на результатах, полученных в режиме AI, поэтому эти выводы могут быть неприменимы к другим функциям или задачам. Также важно помнить, что участники знали, что являются частью исследовательского исследования, что могло повлиять на их поведение. Хотя мы протестировали широкий спектр задач, чтобы охватить многие различные потребности, мы не смогли изучить каждую из них подробно. Мы призываем будущие исследования углубиться в конкретные области, такие как локальный поиск или онлайн-шопинг.
Я также хочу повторить этот тип исследования в различных отраслях, с большим количеством поисковых задач, категоризированных в соответствии с тем, чего пытаются достичь пользователи, и используя различные большие языковые модели.
Ahrefs – AI Mode Content Experiment
Это очень ограниченный тест, поэтому результаты могут быть неприменимы для всех. Однако это все еще полезный способ увидеть, как работает Google.
Мне было бы интересно протестировать больше тем, включая базовые показатели, написанные людьми.
Nielsen Norman Group – Искусственный интеллект и поведение при поиске
Это исследование рассматривало общие взаимодействия с большими языковыми моделями, а не только те, что находятся в режиме AI или конкретно с продуктами Google. Оно также основывалось на относительно небольшой группе, состоящей всего из десяти участников.
Было бы полезно тщательно протестировать каждый метод поиска на основе искусственного интеллекта, такой как AI Mode, используя больше данных, чтобы увидеть, как они сравниваются как с точки зрения доверия пользователей, так и скорости предоставления результатов.
Propellic – Искусственный интеллект и его влияние на бронирование путешествий
Этот анализ был сосредоточен конкретно на туристической индустрии, но полученные результаты предлагают ценные уроки для бизнеса в любой отрасли.
Людей попросили попробовать использовать функцию искусственного интеллекта, но это может не отражать их обычное поведение – особенно если они обычно не стали бы использовать её самостоятельно.
Amsive/Profound – Ведущие бренды и домены в AI Search.
Это исследование фокусируется на том, как большие языковые модели цитируют свои источники, и не рассматривает, как люди используют или относятся к этим цитированиям или результатам работы модели.
По мере того, как мы продолжаем расширять AI Mode по всему миру, я очень надеюсь, что мы сделаем приоритетным сбор данных из более широкого спектра стран и языков. Для меня также крайне важно тщательно проверить точность контента и, самое главное, убедиться, что наши пользователи довольны результатами.
Исследования удобства использования в нашей области значительно выиграли бы от включения большего числа участников из самых разных слоев общества, но это требует значительных инвестиций.
Смотрите также
2025-10-21 16:44