Как опытный эксперт по SEO, я бы сказал, что одним из главных преимуществ WordPress является его универсальность. С помощью WordPress вы можете легко управлять различными цифровыми проектами – от интернет-магазинов и систем бронирования до крупных многосайтовых установок WordPress – все из одной установки WordPress.
Это одновременно база данных и использует мощный язык программирования PHP, что делает внедрение многочисленных обновлений на веб-сайте простым и эффективным.
В этой статье я собираюсь представить три различных способа массового обновления WordPress.
Прежде чем начать, обратите внимание: такие проблемы, как несоответствие полей данных или несовместимость между плагинами, могут привести к неожиданным результатам. Поэтому не забудьте создать резервную копию своей работы перед началом масштабных обновлений.
Кроме того, полезно провести небольшую пробную выгрузку при обновлении контента. Примерно десять публикаций могут послужить отправной точкой для этого теста, прежде чем внедрять изменения на всем веб-сайте.
Как массово обновить контент на веб-сайте WordPress
Простые изменения существующего контента
Чтобы быстро изменить сразу несколько элементов контента, например, авторов, статусы или категории, рекомендуется использовать встроенную функцию массового редактирования в WordPress.
На странице редактирования публикаций/страниц вы можете отметить отдельные публикации и страницы и выбрать «Редактировать».
После этого вы сможете быстро и легко настроить категории, теги, статусы и другие детали для каждой записи. Когда будете готовы, просто нажмите кнопку ‘Обновить’.
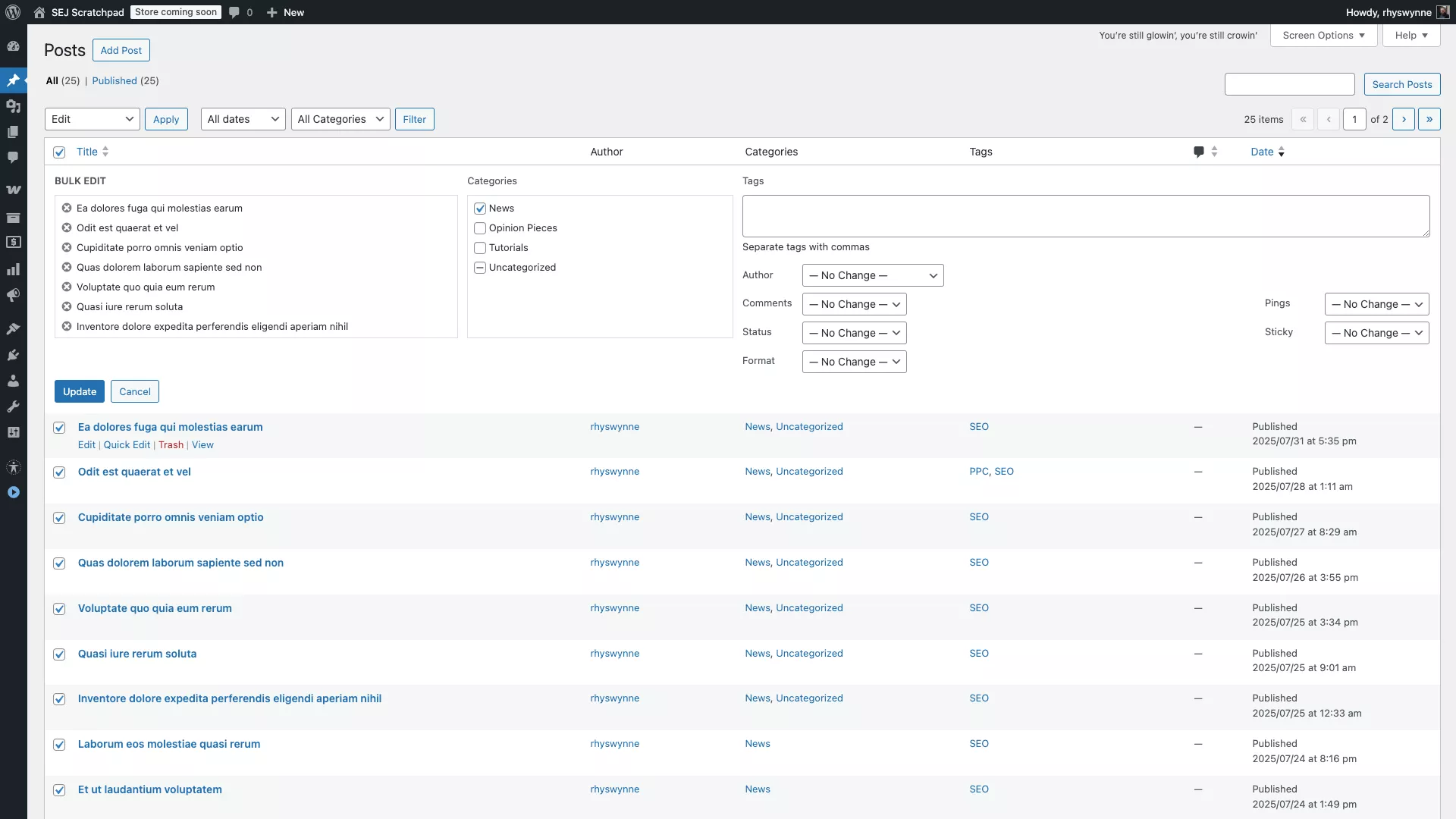
Имейте в виду: это изменение затронет все категории; однако будут добавлены и дополнительные теги. Этот способ изменения контента вполне стандартен, и, вероятно, вы уже знакомы с этой практикой!
Импорт и экспорт контента
Допустим, вы хотите массово добавить контент в WordPress на веб-сайте WordPress.
Как специалист по цифровому маркетингу, когда мне нужно добавить подборку статей блога или каталог продуктов на платформу вроде WooCommerce, я часто использую метод, основанный на источнике данных. Если это набор публикаций в блоге, их можно легко импортировать. Аналогично, если продукты перечислены в таблице, она также может служить источником импорта. Ключ заключается в определении источника данных перед началом процесса.
При переносе контента с одного блога WordPress на другой, наиболее эффективным методом является использование встроенного инструмента импорта WordPress на вашей новой платформе.
При переносе контента с одного сайта WordPress на другой, рекомендуется использовать встроенный инструмент импорта WordPress. Эта утилита разработана для работы с .xml файлами, экспортированными в формате WXR, и имеет опциональную функцию для загрузки и включения прикрепленных файлов в процессе импорта.
При работе с WooCommerce настоятельно рекомендуется использовать встроенный импортер продуктов WooCommerce для бесшовного импорта товаров.
Система достаточно надежна и способна импортировать стандартные CSV, XML файлы или электронные таблицы. Также есть возможность связать поля с теми, что в WooCommerce, хотя это потребует немного больше усилий с вашей стороны.
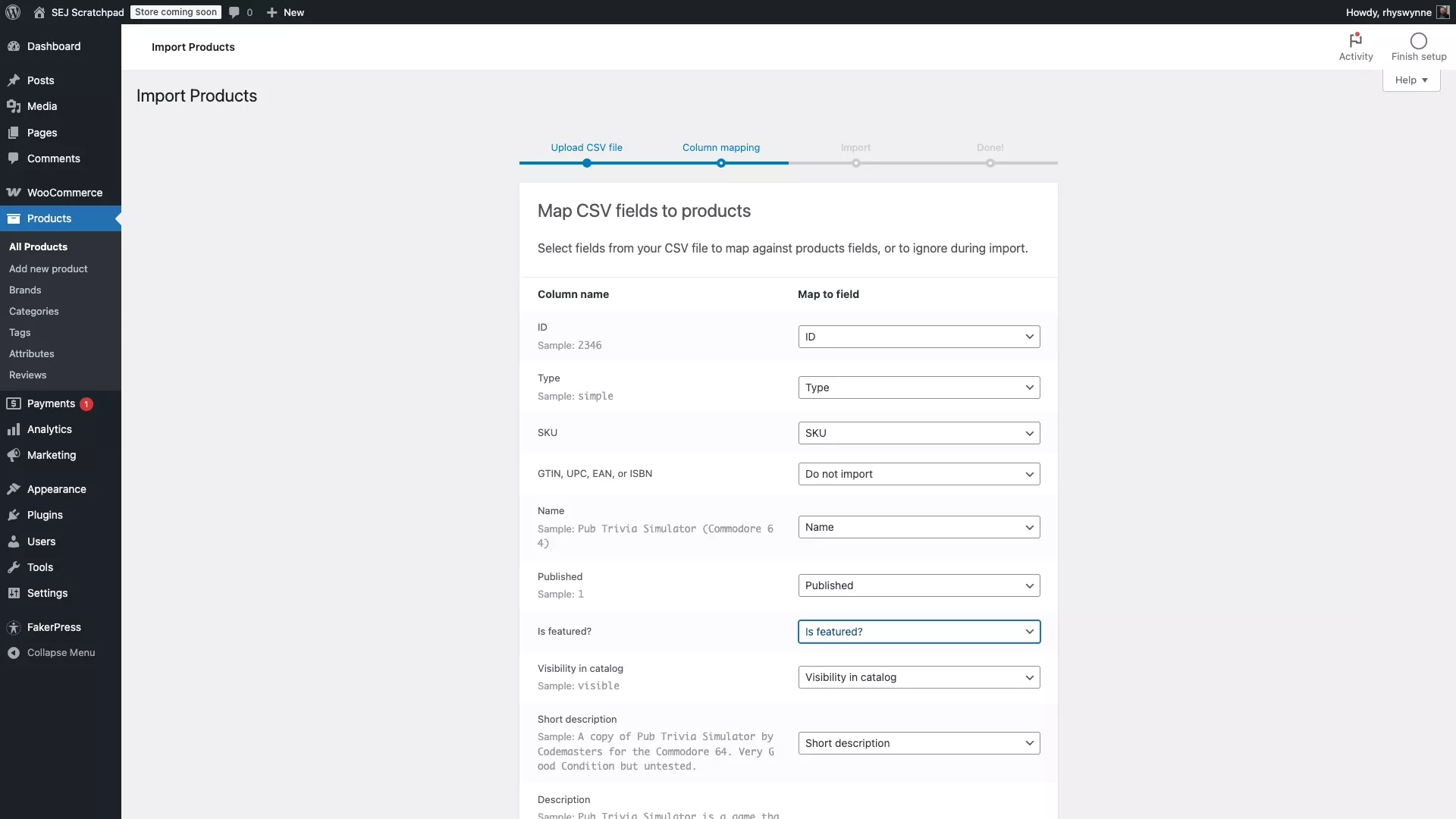
Для импорта или экспорта продуктов WooCommerce используйте встроенный инструмент импорта/экспорта продуктов CSV. Убедитесь, что данные в ваших столбцах соответствуют соответствующим полям продукта в процессе этого действия.
Этот плагин предлагает как бесплатные, так и премиум-функции. Премиум-версия обеспечивает бесшовную интеграцию с Advanced Custom Fields (ACF), Yoast и WooCommerce. Обсуждение преимуществ WP All Import заслуживает отдельной публикации в блоге. Тем не менее, позвольте мне привести типичный пример его использования.
Если вы хотите пересмотреть заголовки всех ваших публикаций в блоге, используя единый формат, вы можете воспользоваться дополнительным плагином под названием WP All Export, чтобы извлечь все данные ваших публикаций для редактирования.
Как специалист по SEO, я бы перефразировал это предложение следующим образом: ‘Я буду непосредственно изменять определенные значения в Excel или Google Sheets, а затем использовать WP All Import для беспрепятственной загрузки этих отредактированных записей в блоге’.
Как обрабатывать массовые обновления плагинов на веб-сайте WordPress
Действительно, поддержка блогов на WordPress часто включает в себя рутинную задачу, а именно обеспечение регулярного обновления всех установленных плагинов.
Поддержание актуальности плагинов – важная задача для обеспечения безопасности вашего сайта и его эффективной работы. К счастью, для тех, кто управляет только одним сайтом, выполнение массового обновления довольно просто.
Как опытный веб-мастер, я всегда рекомендую входить на мой сайт WordPress, используя мои административные учетные данные. Оказавшись внутри, найдите раздел ‘Обновления’ на вашей панели управления. Нажав на
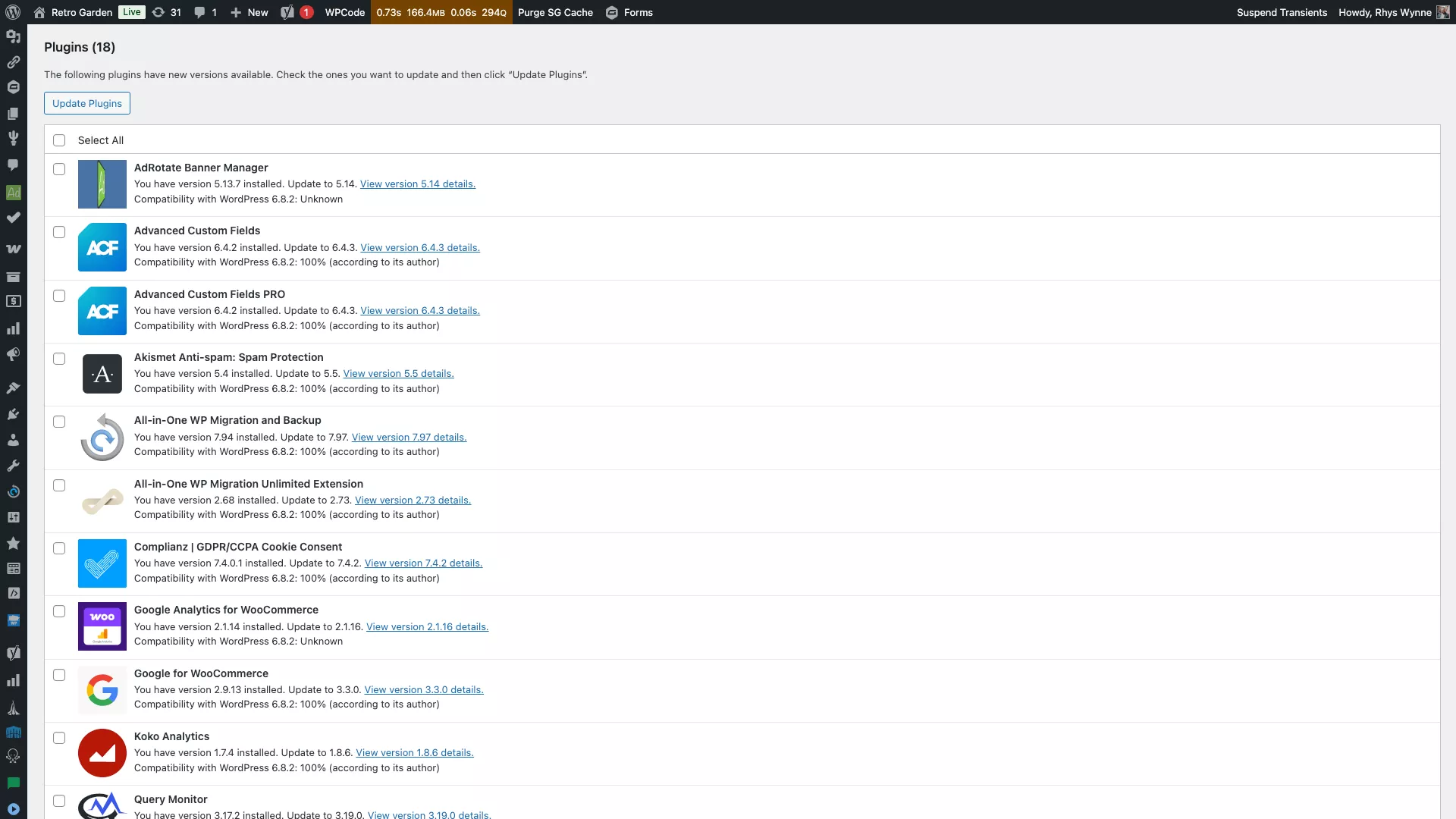
Продолжая прокручивать страницу вниз, вы найдёте список плагинов, которым требуются обновления, в самом низу. Подобно функции массового редактирования, рядом с каждым элементом будет находиться флажок для удобного выбора.
Чтобы убедиться, что все желаемые плагины обновлены, пожалуйста, поставьте галочку напротив каждого плагина, который вы хотите обновить. Другими словами, убедитесь, что вы выбрали все подходящие флажки для ваших предпочтительных дополнений.
Нажмите «Обновить плагины», и все плагины будут обновлены!
Ваш сайт вряд ли окупится с большим количеством резервных копий. Однако, в крайне маловероятном случае, если сайт сломается после обновления множества плагинов, есть способы восстановления, которые можно прочитать в статье «Как разрешить конфликт плагинов». Перейдите в файлы журнала и отключите плагин через FTP.
В качестве альтернативы, вот еще несколько методов для успешного выполнения массовых обновлений:
- Обновляйте небольшими порциями (например, разделяйте по функциональности или по буквам). Обновите, перезагрузите ключевые страницы, затем переходите к следующему этапу.
- Сделайте резервную копию и протестируйте на промежуточной среде перед переносом в продуктивную.
- Если вы используете панель управления, например ManageWP, запустите безопасное обновление (она создает точку восстановления, применяет обновления, визуально сравнивает страницы и откатывает изменения, если что-то выглядит неправильно).
- Интерфейс командной строки WordPress (WP-CLI) позволяет просматривать или обновлять плагины по отдельности:
- Просмотр:
wp plugin update yoast-seo --dry-run - Обновить один:
wp plugin update yoast-seo - Обновить все (используйте с осторожностью):
wp plugin update --all
- Просмотр:
3. Как обрабатывать массовые обновления плагинов на нескольких сайтах WordPress
Управление одним сайтом на WordPress относительно просто, когда речь идет об обновлении плагинов. Но когда у вас несколько сайтов, обновление плагинов на каждом по отдельности со временем становится довольно утомительным.
К счастью, я уже освещал эту тему в предыдущей статье под названием «Как управлять несколькими веб-сайтами на WordPress».
Как опытный специалист по поисковой оптимизации, я взял на себя инициативу составить список удобных сервисов панели управления для обслуживания WordPress в статье. Эти сервисы позволяют мне управлять и обновлять множество веб-сайтов на WordPress со единой, оптимизированной платформы.
Каждая платформа предоставляет премиум-сервисы с разными ценами и функциями, но также предлагает бесплатные обновления для плагинов и тем.
Используя ManageWP, подключение ваших веб-сайтов отобразит панель управления, показывающую количество необходимых обновлений плагинов по нескольким сайтам. Чтобы применить обновления ко всем плагинам на всех сайтах одновременно, просто нажмите «Обновить все». Если вы предпочитаете, вы также можете выбрать определенные плагины, установив флажки напротив них, а затем нажмите «Обновить» для индивидуальных обновлений.
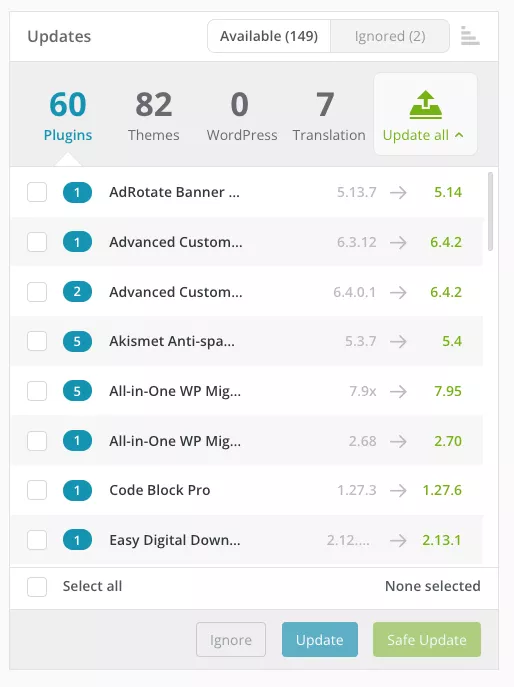
В ManageWP у вас есть возможность сортировать обновления по веб-сайтам и их уровню важности. Для более безопасного подхода предусмотрена премиум-функция, которая позволяет использовать процесс «безопасного» обновления. Этот процесс позволяет применить обновление, проверить веб-сайт и отменить изменения, если что-то пойдет не так во время обновления.
WordPress предлагает несколько способов для выполнения массовых обновлений. Кроме того, вы можете использовать инструменты командной строки, такие как WP CLI, которые можно использовать для создания и выполнения скриптов на ваших сайтах. Однако, более подробное обсуждение этой темы лучше подходит для отдельной статьи.
Чтобы массово обновить все плагины в WP CLI, можно использовать следующую команду:
wp plugin update --allМетод: Здесь мы будем обновлять каждый плагин по отдельности для одного сайта; кроме того, вы можете разработать скрипт, способный выполнять процесс обновления на нескольких веб-сайтах.
Использование интерфейса командной строки WordPress (WP CLI) предлагает оптимизированный и эффективный подход к управлению многочисленными веб-сайтами, что делает его идеальным инструментом для цифровых агентств.
Подведение итогов: масовые обновления для бесперебойной работы сайта WordPress
Управление несколькими обновлениями одновременно становится простым с помощью WordPress. Независимо от того, настраиваете ли вы свой контент, добавляете новые продукты или поддерживаете свои плагины, WordPress оптимизирует этот процесс для вас.
В большинстве случаев вы можете найти подходящее решение среди предоставленных инструментов и дополнительных плагинов. Чтобы обеспечить успех и избежать потенциальных проблем, лучше вносить изменения небольшими шагами и всегда иметь резервную копию под рукой.
Уделив немного времени подготовке, вы можете значительно сократить необходимость в утомительном ручном труде и обеспечить безупречную работу и оптимальную эффективность вашего веб-сайта (сайтов).
Смотрите также
- Акции NMTP. НМТП: прогноз акций.
- Полное руководство по вариантам таргетинга рекламы PPC
- Инструменты Bing для веб-мастеров показывают данные для Bing и Yahoo; Не ChatGPT
- 42 Статистика и факты Facebook на 2024 год
- Ошибка поиска Google: снова не индексируется и не отображается новый контент
- TCPL для рекламы местных услуг Google (целевая цена за потенциального клиента)
- Акции EUTR. ЕвроТранс: прогноз акций.
- Волатильность рейтинга Google в поиске резко возросла после решения Министерства юстиции США о монополии
- Какой самый низкий курс евро к шекелю?
- Акции привилегированные LNZLP. Лензолото: прогноз акций привилегированных.
2025-09-12 16:10