Интересно, почему ваш рейтинг может падать?
Только что обнаружили, что ваш сайт на WooCommerce загружается медленно?
Медленная работа сайта на WooCommerce вредит не только из-за потери потенциальных продаж. Она также негативно влияет на видимость в поисковых системах, функциональность админ-панели и доверие клиентов к вашему бизнесу.
Независимо от того, являетесь ли вы одиноким разработчиком, самостоятельно настраивающим свою технологическую инфраструктуру, или крупным агентством, контролирующим множество интернет-магазинов клиентов, важно понимать, как работает WooCommerce под нагрузкой — эти знания сейчас считаются такими же базовыми, как знание алфавита.
В настоящее время многие веб-сайты на WordPress демонстрируют высокую степень одновременной активности, что указывает на то, что несколько событий происходят одновременно.
- Магазины проводят распродажи в режиме реального времени.
- Платформы управления обучением отслеживают прогресс пользователей.
- Сайты по подписке предоставляют высоко персонализированный контент.
Все действия, выполняемые пользователем, такие как вход в систему, изменение корзины покупок или начало оформления заказа, зависят от информации, передаваемой сервером в режиме реального времени. Эти данные нельзя сохранять для последующего использования (кешировать).
Инструменты, такие как Varnish или Сети доставки контента (CDN), полезны для обслуживания публичных веб-страниц, таких как главная страница или списки продуктов, поскольку они могут кэшировать и быстро доставлять эти страницы множеству пользователей. Однако, как только пользователь входит в свою учетную запись или взаимодействует со своей сессией, кэширование становится бесполезным, поскольку каждый запрос необходимо обрабатывать в режиме реального времени. Это означает, что каждый запрос должен обрабатываться индивидуально и немедленно.
Эта статья объясняет причины данного явления и предлагает рекомендации по оптимальной конфигурации сервера, которая обеспечивает бесперебойную, быструю работу интернет-магазинов и их готовность к расширению.
Почему магазины WooCommerce замедляются?
Со временем, особенно при увеличении трафика веб-сайта и повышении вовлеченности посетителей, проблемы с производительностью электронной коммерции могут стать очевидными. Вот некоторые из частых причин, приводящих к замедлению работы сайтов в условиях высокой нагрузки:
1. Недостаточные серверные ресурсы или устаревшая хостинговая инфраструктура.
2. Неэффективные плагины или плохо написанные темы.
3. Большие изображения и другие медиафайлы, не оптимизированные для быстрой загрузки.
4. Чрезмерное количество запросов к базе данных, часто из-за сложных настроек.
5. Недостаточные стратегии кэширования для динамического контента.
PHP: испытывает трудности при высокой пользовательской активности
Проще говоря, WooCommerce эффективно работает, используя язык программирования PHP для управления динамическими задачами, такими как обновление корзины покупок, применение купонов и сопровождение процесса оформления заказа. По сравнению с традиционными настройками, которые полагаются на Apache для управления PHP, эти старые системы, как правило, работают медленнее и менее эффективно.
В современных конфигурациях используется PHP-FPM, что повышает эффективность выполнения и позволяет обрабатывать большее количество одновременных пользователей без задержек.
2. Полная база данных: Она становится узким местом.
Когда такие события, как создание заказов, действия в корзине покупок и взаимодействие с пользователями, происходят часто, это приводит к записи большого объема данных в базу данных. В периоды высокой нагрузки, например во время распродаж, запуска новых продуктов или курсов, базе данных может быть сложно справиться с возросшей рабочей нагрузкой.
Системы, способные эффективно выполнять запросы с использованием превосходных методов индексации, как правило, более легко справляются с пиковыми нагрузками.
3. Проблемы с кэшированием: Кэширование объектов отсутствует или настроено некорректно.
Из-за отсутствия адекватного кэширования объектов, WooCommerce склонен многократно обращаться к базе данных за идентичной информацией, такой как детали продукта, изображения, содержимое корзины и данные пользовательской сессии.
Использование решений со встроенной функциональностью Redis позволяет переместить данные в память, тем самым снижая нагрузку на сервер и повышая производительность веб-сайта за счет увеличения скорости его работы.
4. Ограничения параллельности влияют на производительность во время пиковых нагрузок.
Как эксперт по SEO, я могу с уверенностью утверждать, что множество доступных сегодня хостинг-стеков, включая те, что основаны на Apache, стабильно обеспечивают высокую производительность для различных веб-сайтов WordPress и WooCommerce. Эти платформы хорошо справляются с обычной веб-трафиком, обеспечивая надежность и поддерживая бесчисленное количество процветающих интернет-магазинов.
С увеличением трафика, когда все больше людей одновременно получают доступ к веб-сайту и взаимодействуют с ним, нагрузка на сервер неуклонно возрастает. На этом этапе дизайн или архитектура становятся все более важными.
Приложения, созданные с использованием NGINX в их стеке, который использует событийный подход, демонстрируют превосходную способность эффективно справляться с повышенной конкуренцией. Эта эффективность особенно заметна во время неожиданных всплесков веб-трафика.
Вместо замены существующих методов, эта стратегия повышает максимальные возможности для магазинов, которые становятся более гибкими и нуждаются в неизменной оперативности под растущим давлением.
5. Ваша административная панель WordPress замедляется в периоды распродаж.
В периоды пиковой нагрузки, такие как праздничные распродажи или поступление новых товаров, команды управления магазинами могут столкнуться с задержками из-за возросшего трафика. Как следствие, панель управления WordPress может загружаться дольше, что приведет к замедлению процессов публикации продуктов, управления заказами и редактирования страниц.
Как спроектировать масштабируемую настройку WordPress для динамических нагрузок?
Современные магазины, работающие на WooCommerce, ориентированы не только на постоянный приток трафика. Пользователи всё чаще взаимодействуют, выполняя вход в систему, изменяя свои корзины покупок и активно управляя профилями подписок, создавая динамичное взаимодействие в реальном времени с серверной частью этих магазинов.
Как опытный веб-мастер, я на собственном опыте убедился, что стандартная настройка WordPress, в основном ориентированная на статический контент, часто испытывает трудности при высоких нагрузках.
Вот как типичная настройка сравнивается с настройкой, созданной для производительности и масштабируемости:
| Компонент | Базовая настройка | Масштабируемая настройка |
| Веб-сервер | Апачи | NGINX |
| Обработчик PHP | mod_php или CGI | PHP-FPM |
| Кэширование объектов | Отсутствует или временные ошибки базы данных | Redis с Object Cache Pro |
| Запланированные задачи | WP-Cron | Системная cron-задача |
| Кэширование | Кэширование CDN или всей страницы | Многоуровневое кэширование, включая кэш объектов |
| Обработка .htaccess | Встроенный с Apache | Ручное переопределение правил в конфигурации NGINX |
| Обработка параллельного доступа | Ограниченный | Сервер, управляемый событиями и экономно использующий память. |
Как вручную настроить производительный и масштабируемый стек WooCommerce
Нет достаточной пропускной способности? Попробуйте простой способ.
При создании сервера самостоятельно или настройке существующего, крайне важно правильно оптимизировать ключевые элементы:
1. Выбор серверного программного обеспечения (например, Apache, Nginx или Microsoft IIS).
2. Настройка операционной системы (например, Linux против Windows).
3. Выбор подходящих аппаратных компонентов (процессор, память, хранилище и сетевое оборудование).
4. Правильная настройка серверных параметров для оптимальной производительности (например, балансировка нагрузки, кэширование и меры безопасности).
5. Обеспечение надлежащей масштабируемости для обработки возросшего трафика или спроса.
6. Непрерывный мониторинг состояния сервера и анализ журналов для устранения неполадок и улучшения.
1) Используйте NGINX для повышения производительности статических файлов
NGINX, часто используемый, служит эффективным, высокопроизводительным веб-сервером, особенно хорошо справляющимся с обслуживанием статических файлов и эффективным управлением многочисленными одновременными запросами. Идеально подходит для интернет-магазинов, ожидающих большой трафик, или тех, кто стремится оптимизировать свою систему для быстрой работы.
Вместо использования файлов .htaccess, как в Apache, NGINX обрабатывает правила перенаправления иначе. В отличие от Apache, вы обнаружите, что правила для постоянных ссылок, перенаправлений и обработки завершающих слешей должны быть добавлены непосредственно в конфигурацию блока сервера в NGINX. Для WordPress конкретно, эти конфигурации четко документированы во время установки, что означает, что их нужно настроить только один раз при первоначальной установке программного обеспечения.
Использование этого метода обеспечивает больший контроль на уровне сервера, что выгодно для команд, стремящихся настроить собственную конфигурацию или приоритизировать масштабируемость.
2) Включите PHP-FPM для более быстрой обработки запросов
Как опытный веб-мастер, хотел бы подчеркнуть преимущества использования PHP-FPM. Этот инструмент кардинально меняет ситуацию, поскольку отделяет обработку PHP от веб-сервера, предоставляя нам больше контроля над использованием памяти и процессора. Настраивая важные значения, такие как pm.max_children и pm.max_requests, в соответствии с размером вашего сервера, вы можете эффективно предотвратить перегрузки в периоды высокой активности. Это обеспечивает оптимальную производительность и более плавный пользовательский опыт даже при высокой нагрузке на сайт.
3) Установите Redis с Object Cache Pro
Redis облегчает хранение часто используемых данных, таких как товары в корзине, информация для входа пользователей и сведения о продуктах, во временной памяти для более быстрого доступа в рамках WooCommerce.
Совместите это с инструментом Object Cache Pro, чтобы уменьшить размер кэшированных элементов, снизить нагрузку на базу данных и повысить скорость вашего сайта при высокой посещаемости.
4) Замените WP-Cron на задание Cron системного уровня
По умолчанию, WordPress автоматически проверяет запланированные задачи каждый раз, когда к вашему веб-сайту осуществляется доступ. Это включает в себя такие обязанности, как отправка электронных писем, управление запасами и синхронизация данных. Пока у вас есть постоянные посетители, эта система работает эффективно. Однако, если трафик уменьшается, могут возникнуть задержки в выполнении задач.
Вот более понятное объяснение:
Чтобы ваши задачи в WordPress выполнялись плавно и по расписанию, не полагаясь на посещения сайта, вы можете выполнить следующие действия:
1. Сначала отключите WP-Cron, добавив эту строку в ваш файл wp-config.php: define(‘DISABLE_WP_CRON’, true);
2. Затем настройте реальную задачу cron непосредственно на уровне сервера, чтобы запускать скрипт wp-cron.php каждую минуту. Это обеспечит выполнение ваших задач вовремя, не дожидаясь посетителей, которые их запустят.
Следуя этим инструкциям, вы получите более эффективную и надежную систему планирования для вашего сайта WordPress!
5) Добавьте правила перезаписи вручную для NGINX
Вместо использования файлов .htaccess для определения правил URL, поскольку NGINX их не поддерживает, вам потребуется указать ваши шаблоны URL непосредственно в блоке сервера.
Это включает в себя такие элементы, как постоянные ссылки, перенаправления и управление статическими файлами. Настройка обычно выполняется только один раз, и большинство необходимых правил можно найти в надежной документации WordPress. После включения этих правил все работает аналогично тому, как это было бы на Apache.
Несколько компромиссов, которые следует учитывать
Такая настройка обеспечивает реальное увеличение скорости. Но следует помнить о некоторых технических изменениях.
- NGINX не читает файлы .htaccess. Все перенаправления и редиректы необходимо добавлять вручную.
- WordPress Multisite может потребовать дополнительных настроек, особенно если вы используете режим с подкаталогами.
- Настройки безопасности, такие как блокировка IP-адресов или ограничение скорости запросов, должны обрабатываться на уровне сервера, а не через плагины.
Для большинства разработчиков работа над этими проблемами не должна представлять значительных трудностей. Однако, если вы используете современные платформы разработки, многие из этих проблем, вероятно, будут решены автоматически.
Чтобы обеспечить бесперебойную работу WooCommerce без необходимости сложной настройки, необходимо иметь системную архитектуру, соответствующую принципам работы современных, динамичных интернет-магазинов.
Затем давайте изучим поведение такой связки в условиях высокой нагрузки, используя тесты для иллюстрации различий в производительности, когда сервер был разработан специально для динамических веб-сайтов.
Что происходит, когда вы переходите на оптимизированный набор технологий?
Некоторые проблемы с производительностью системы не обязательно вызваны кодом или плагинами. По мере расширения бизнеса и увеличения пользовательской активности становится важным учитывать характер нагрузки, особенно при управлении сеансами в реальном времени для авторизованных пользователей.
Чтобы понять, как различные настройки реагируют на этот конкретный тип действий, Koddr.io провел автономное тестирование, сравнив две часто используемые производственные конфигурации в качестве точки отсчета.
- Гибридная конфигурация с использованием Apache и NGINX.
- Стек, построенный на основе NGINX с использованием PHP-FPM, Redis и объектного кэширования.
Как эксперт по SEO, я обеспечил тщательную оптимизацию обеих конфигураций, включив в них точно настроенные компоненты, такие как PHP-FPM и Redis. Моей целью был всесторонний анализ для оценки их производительности в реалистичных, реальных условиях, предлагая ценные сведения для будущих оптимизаций.
Процесс тестирования был сосредоточен главным образом на действиях внутри WooCommerce и LearnDash, которые не зависят от кэширования, с целью выявления случаев, когда авторизованные пользователи вызывают динамические реакции сервера.
В подобных ситуациях оптимизированная система продемонстрировала лучшую производительность и надежность при высокой пользовательской активности. Это подчеркивает важность наличия структуры, спроектированной для обработки переменного, интенсивного трафика, основанного на конкретном приложении.
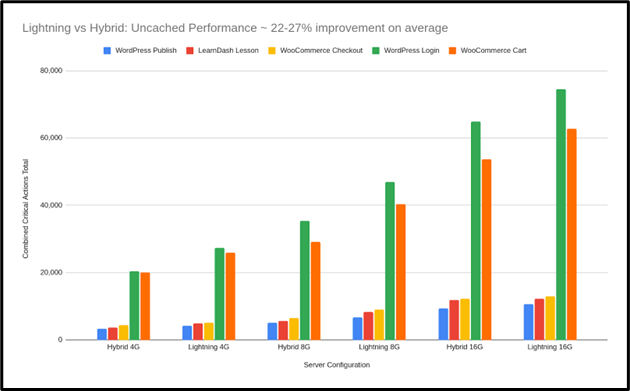
WooCommerce работает быстрее под нагрузкой
Один тест имитировал одновременную оплату 80 пользователями. Разница была очевидна:
| Сценарий | Гибридный стек | Оптимизированный стек | Прибыль |
| Оформление заказа WooCommerce | 3 035 действий | 4 809 действий | +58% |
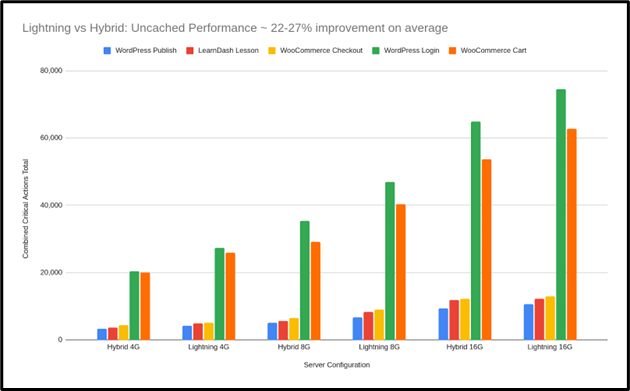
Платформы управления обучением получают еще больше преимуществ.
В процессе просмотра курсов для LearnDash, задачи, требующей значительных ресурсов, не имеющей кэширования и содержащей много текста, оптимизированная система обработала на 85% больше запросов по сравнению с предыдущим состоянием.
| Сценарий | Гибридная сборка | Оптимизированный стек | Прибыль |
| Просмотр списка курсов LearnDash | 13 459 действий | 25 031 действие | +85% |
Оптимизированные стеки превосходно справляются с обработкой настраиваемого или переменного контента. Поскольку такие запросы нельзя сохранить для последующего использования (в кеше), первоначальная скорость и эффективность сервера играют жизненно важную роль.
Скорость работы серверной части также улучшена.
Улучшенный стек не только ускорил операции для пользователей, но и повысил отзывчивость административной панели WordPress, сделав её более эффективной и удобной в использовании.
- Время входа в WordPress улучшено до 31%.
- Операции публикации выполнялись на **20% быстрее**, даже при высокой нагрузке.
Это означает, что ваша команда может одновременно работать с разными продуктами, мгновенно обновлять веб-страницы и быстро реагировать на продажи, и все это без каких-либо задержек или перебоев.
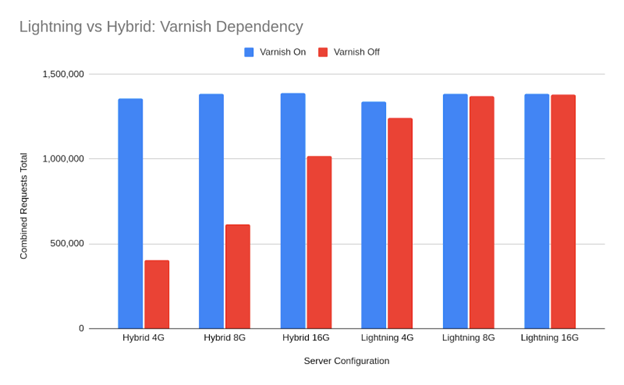
Он справляется с большим объемом работы, не полагаясь на кэширование.
После отключения Varnish в Koddr, объединенный стек продемонстрировал впечатляющее снижение эффективности на 71%, подчеркивая его мастерство в управлении трафиком кэшированных данных. Напротив, оптимизированная конфигурация показала снижение всего на 7%, указывая на ее способность сохранять быстродействие во время некэшированных сеансов авторизованных пользователей.
С точки зрения функциональности, обе конфигурации имеют свои преимущества; однако для розничных заведений, которые сильно зависят от немедленного взаимодействия с пользователем, минимизация зависимости от временного хранилища (кэша) может существенно повлиять на производительность.
| Тип стека | С использованием кэширования | Без кэширования | падение |
| Гибридный стек | 654 000 действий | 184 000 действий | -7 процентов |
| Оптимизированный стек | 619 000 действий | 572 000 действий | -7 процентов |
Почему это важно?
Динамические веб-страницы, такие как те, что встречаются в магазинах WooCommerce, представляют собой больше сложностей для оптимизации по сравнению со статическими страницами из-за их интерактивного характера. Действия в реальном времени, такие как обновления корзины, входы в систему и оформление заказов, требуют немедленной обработки, что делает кэширование менее эффективным после входа пользователя в систему, поскольку эти элементы не предварительно отрисованы.
Результаты Koddr.io показывают, как оптимизированный серверный стек:
- Снижает пиковые нагрузки на процессор во время всплесков трафика.
- Обеспечивает отзывчивость серверной части для вашей команды.
- Обеспечивает более стабильную скорость для авторизованных пользователей.
- Позволяет масштабироваться без сложных обходных путей для оптимизации производительности.
Это относится к типу обновлений, специально разработанных для эффективной обработки динамических задач, таких как Cloudways Lightning, который предназначен для эффективного управления задачами WooCommerce.
Основные веб-показатели не касаются только фронтенда.
Для достижения оптимальной производительности вам следует настроить каждое изображение, сжать каждую часть кода и даже перейти на более быструю тему оформления. Однако, даже с этими улучшениями, ваш рейтинг основных веб-показателей может оставаться неудовлетворительным, если ваш сервер не отвечает оперативно.
Вот что происходит, когда авторизованные пользователи взаимодействуют с сайтами WooCommerce или LMS.
Когда покупатель нажимает кнопку «Добавить в корзину», требуется обработка в режиме реального времени, поскольку кэширование в этом сценарии использовать нельзя. Следовательно, время до первого байта (TTFB) может стать существенной проблемой, поскольку сервер должен обработать запрос немедленно.
Медленный отклик сервера приводит к тому, что Google требуется больше времени для начала загрузки веб-страницы, что напрямую влияет на ваши показатели «Крупнейшая отрисованная область контента» (LCP) и «Взаимодействие до следующей отрисовки» (INP), поскольку оба они подвержены влиянию этой задержки в отображении страницы.
Улучшение пользовательского интерфейса, безусловно, может принести некоторые улучшения, но если серверная часть работает медленно, ваши результаты не сильно улучшатся — особенно когда речь идет об опыте пользователей, прошедших авторизацию. Проще говоря, хотя повышение эффективности передней части веб-сайта или приложения полезно, если серверная часть работает медленно, прирост производительности, достигнутый на клиентской стороне, не приведет к заметным улучшениям скорости или результатов.
Реальная оптимизация начинается с сервера.
Как агентства отказываются от ручной работы
Как опытный веб-мастер с большим опытом работы, я всегда имею под рукой тщательно разработанный контрольный список, когда дело доходит до оптимизации производительности моих сайтов на WooCommerce. Вот ключевые шаги, которые никогда меня не подводят:
1. Используйте NGINX: Замените сервер Apache по умолчанию на NGINX, так как он обеспечивает превосходную скорость и стабильность при обработке больших объемов трафика.
2. Внедрите Redis: Redis – это мощный сервер структур данных, который может значительно повысить производительность вашего сайта за счет кэширования часто запрашиваемых данных, тем самым снижая нагрузку на базу данных.
3. Отключите WP-Cron: Встроенная система Cron в WordPress недостаточно эффективна для сайтов с высокой посещаемостью. Разумно заменить ее более надежным решением, таким как WP-Cron Control или задание cron, настроенное на сервере.
4. Обеспечьте безопасность с помощью межсетевого экрана веб-приложений (WAF): Защитите свой сайт от вредоносных атак, внедрив WAF, такой как Wordfence, Sucuri или Cloudflare. Это гарантирует, что ваш сайт останется гибким и устойчивым к потенциальным угрозам.
5. Протестируйте под нагрузкой: Чтобы убедиться, что ваш сайт может справиться с внезапными скачками трафика, проведите стресс-тесты с помощью таких инструментов, как JMeter или Load Impact. Это поможет вам выявить узкие места и области для улучшения до того, как они станут критическими.
6. Продолжайте тонкую настройку: Оптимизация производительности – это непрерывный процесс. Регулярно отслеживайте скорость своего сайта и принимайте необходимые меры, чтобы он работал более плавно, быстрее и эффективнее с течением времени.
Однако не у каждой команды есть ресурсы для поддержания всего этого.
Таким образом, все больше организаций внедряют предустановленные системы, которые включают в себя эти улучшения в качестве стандартных функций. Cloudways Lightning, управляемая платформа, построенная на базе NGINX + PHP-FPM и адаптированная для обработки динамических задач, служит подходящим примером этой практики.
Важность скорости неоспорима, но не менее важно обеспечить стабильность серверной части в периоды высокой нагрузки. Это означает, что время входа в систему администратора остается быстрым и отзывчивым, обновления продуктов происходят плавно без зависаний или замираний, и заказы продолжают обрабатываться бесперебойно. Короче говоря, производительность системы должна быть надежной под давлением, в дополнение к скорости.
Джо Лакнер, основатель Celsius LLC, поделился тем, что изменилось для них:
Перенос наших задач WordPress на новейшую инфраструктуру Cloudways стал значительным улучшением. Административная консоль теперь более отзывчива, а скорость загрузки страниц увеличилась примерно на 20%. В очередной раз Cloudways продемонстрировала свое лидерство в отрасли благодаря исключительной надежности и экономичности в этом ценовом диапазоне.
Агентства ищут решение, которое позволит им развиваться, не тратя постоянно время на управление инфраструктурой при увеличении трафика.
Итоговый вывод
Производительность WooCommerce теперь касается не только скорости загрузки главной страницы.
На вашем веб-сайте действия, происходящие в режиме реального времени, включают как пользователей, так и вашу команду. Когда пользователь входит в систему или переходит к этапу оформления заказа, кэширование становится неактуальным. Каждое действие обрабатывается немедленно сервером напрямую.
Если инфраструктура не оптимизирована, скорость работы сайта снижается, продажи падают, а работа над серверной частью замедляется.
Создание прочной основы имеет решающее значение. Структура, рассчитанная на обработку высоких уровней одновременной активности и некешируемого трафика, обеспечивает плавную работу во всех областях. Это относится к обновлению корзин покупок, внесению изменений и публикации новых продуктов.
Для команд, ищущих более простой путь к оптимизированной производительности в масштабе без необходимости ручной настройки серверов, такие решения, как Cloudways Lightning, предлагают более быстрый и понятный вариант.
Используйте промокод «SUMMER305» и получите скидку 30% на 5 месяцев + 15 бесплатных переездов. Зарегистрируйтесь сейчас!
Указание авторства изображений
Изображения в публикации: Изображения от Cloudways. Используются с разрешения.
Смотрите также
- Акции NMTP. НМТП: прогноз акций.
- Полное руководство по вариантам таргетинга рекламы PPC
- Yelp подает в суд на Google из-за доминирования в локальном поиске
- Какой самый низкий курс евро к шекелю?
- Дифференциация: выделяйтесь, получайте клики
- 42 Статистика и факты Facebook на 2024 год
- Ошибка поиска Google: снова не индексируется и не отображается новый контент
- TCPL для рекламы местных услуг Google (целевая цена за потенциального клиента)
- Советы по проведению платных кампаний в СМИ в строго регулируемых отраслях
- Google представляет собственное решение для обработки данных для пользователей аналитики
2025-08-29 08:43