

Владельцы бизнеса и специалисты по маркетингу оказываются в привилегированном положении, так как имеют множество социальных медиаплатформ для расширения своего цифрового присутствия.
На платформах вроде BlueSky, TikTok, LinkedIn и даже Patreon сфера маркетинга в социальных сетях стала более яркой, чем когда-либо – хотя можно сказать, что она также стала все более требовательной к временным ресурсам.
Но это и не обязательно. К счастью, вам не нужно быть везде одновременно.
Места, где вы решаете появляться онлайн, должны оптимально совпадать с теми местами, где ваши основные клиенты обычно проводят время. Внимательно выбирайте эти платформы.
Кроме того, подходящий инструмент планирования может упростить ваши усилия по маркетингу в социальных сетях без необходимости использования дорогостоящего или сложного программного обеспечения.
Этот урок предоставляет вам удобный бесплатный шаблон планирования социальных сетей, а также практические советы по его настройке в соответствии с вашими специфическими потребностями.
Это так же просто или настраиваемо, как вам нужно. Без лишних свистелок и перделок.

Шаблон планировщика социальных сетей для Google Sheets (бесплатный)
Создание плана для вашего контента в социальных сетях не должно быть сложным и не требует дорогостоящего программного обеспечения.
Использование нашего бесплатного шаблона планировщика упрощает процесс организации, планирования и управления вашими постами в социальных сетях.
Этот шаблон предназначен как для частных лиц, предпринимателей, так и для специалистов по маркетингу. Он помогает поддерживать регулярный график контента, обеспечивать порядок и содействовать разработке более эффективных стратегий для управления социальными сетями.
С помощью этого шаблона Google Sheets вы можете:
- Планируйте свой контент-календарь заранее, смотрите что вы опубликовали и знайте, что будет следующим.
- Запланируйте посты для нескольких аккаунтов социальных сетей из одного календаря.
- Отслеживайте прогресс своего контента и используйте информацию, чтобы определить свою будущую стратегию.
- Сотрудничайте с другими, предоставляя доступ своей команде.
Обратите внимание: нажмите «Файл > Создать копию», чтобы отредактировать ваш шаблон. Вам не нужно запрашивать доступ к редактированию.
Создайте копию шаблона планировщика социальных сетей для Google Sheets
Как планировать свой контент в социальных сетях
Используя шаблон Google Таблиц, вы можете легко просматривать свой расписание заранее и удобно хранить все ресурсы социальных сетей в одном месте.
Вот как планировать свой контент в социальных сетях на этот год.
Шаг 1: Создайте копию шаблона «Планирование в социальных сетях»
После получения доступа к шаблону перейдите в раздел «Файл» и выберите «Создать копию». Это действие создаст новую версию шаблона, которую вы можете свободно изменять.
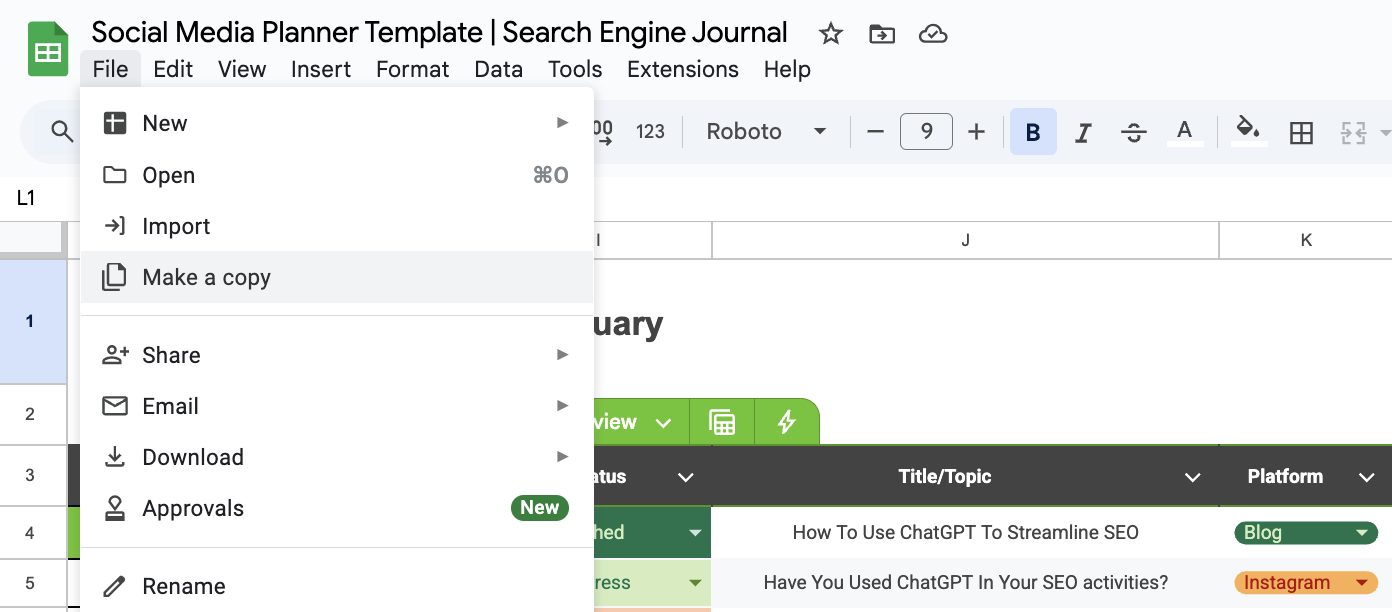
После этого, пожалуйста, присвойте вашему документу ясное и содержательное название, например, «[Название вашей компании»] — Стратегия социальных медиа на период Q1-Q4 2025,» а затем сохраните его безопасно в Google Диске.
Шаг 2: Определите текущий квартал/месяц
Чтобы эффективно планировать вашу активность в социальных сетях, убедитесь, что определили конкретный квартал и / или месяц, когда планируете начать свои усилия согласно текущему времени чтения этого материала.
Нижняя часть шаблона включает вкладки от «Q1: Январь» до «Q4: Декабрь» за 2025 год.
Откройте вкладку месяца, в котором хотите начать планировать свой контент:
Для удобства понимания мы начали с обозначения начального вопроса как «Q1: Январь», а затем заполнили несколько примерных тем.
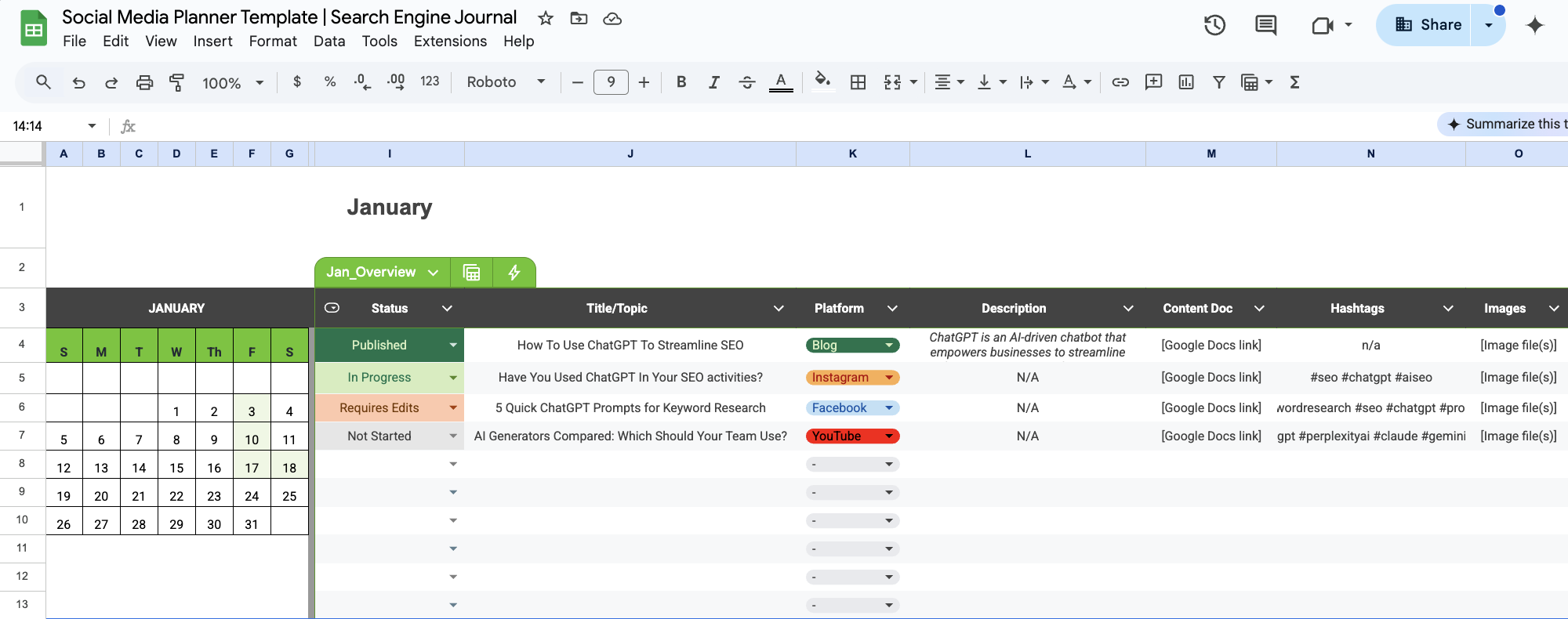
В левых колонках вы найдете календари на каждый месяц года 2025 года. Они созданы для вашего удобства и помогут определить правильные дни недели и месяцы, чтобы облегчить ваше планирование.
Конечно, вы можете обновить это до 2026 года, 2027 года и так далее.
Шаг 3: Выберите Ваши Платформы Социальных Сетей («Платформа»)
В столбце K вы найдете список различных социальных сетей, где можно поделиться вашим контентом.
Не стесняйтесь выбирать один из предложенных вариантов (Блог, Инстаграм, LinkedIn, Facebook, Twitter/X, ТикТок, YouTube) или просто нажмите на иконку карандаша для ввода вашей предпочтительной платформы.
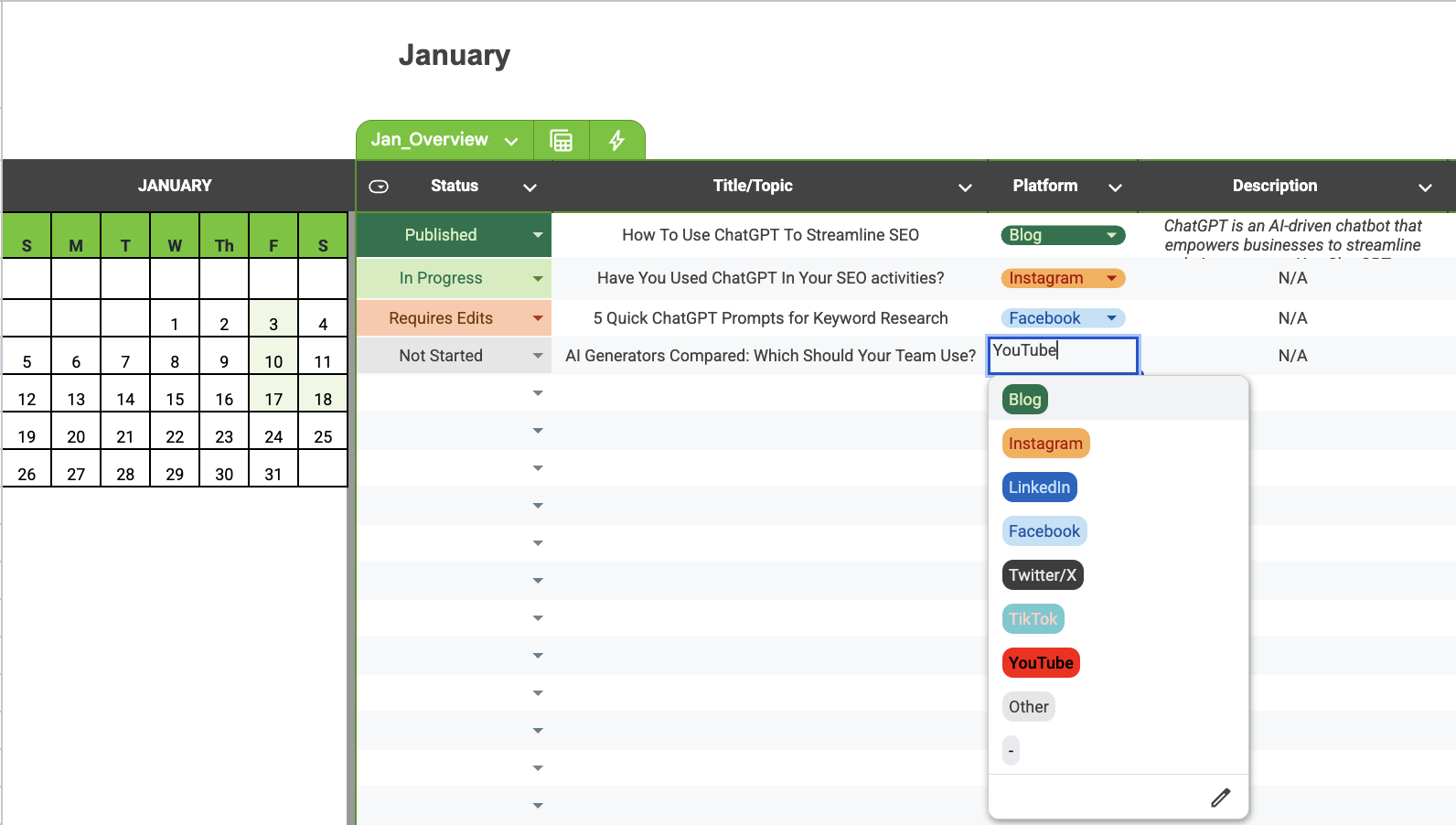
Как опытный веб-мастер хочу отметить, что выпадающее меню здесь служит полезной цели: оно позволяет вам быстро выбирать место для публикации вашего контента. Будь то Facebook, Instagram, Twitter или любая другая платформа по вашему выбору, использование этого инструмента поможет вам поддерживать организованный поток материалов между различными платформами.
Шаг 4: Планируйте свои темы
Сейчас самое время заполнить идеи по темам.
Наше руководство предлагает несколько стратегий выбора увлекательных тем для социальных сетей, помогая вам создавать подлинный и привлекательный контент.
Как опытный SEO-специалист, я всегда стремлюсь оптимизировать свою стратегию контента для достижения максимального эффекта. После начальной фазы исследования вот как я создаю привлекательные посты в социальных сетях: 1. Определите трендовые темы в вашей нише и создавайте посты, которые предлагают ценные инсайты или мнения. 2. Подберите актуальные новости отрасли и предоставьте свой уникальный взгляд на них в краткой и интригующей форме. 3. Делитесь закулисными моментами, например, достижениями команды или предстоящими проектами, чтобы сделать ваш бренд более человечным и укрепить связи с подписчиками. 4. Взаимодействуйте со своей аудиторией путем задавания продуманных вопросов, ответов на комментарии и поощрения диалога в ваших постах. 5. Экспериментируйте с различными форматами постов, такими как изображения, видео, опросы и карусели, чтобы поддерживать свежесть и визуальную привлекательность контента.
- Проведите исследование конкурентов: Посмотрите, что делают ваши конкуренты в социальных сетях и используйте это как источник вдохновения для будущих публикаций.
- Следите за трендами отрасли: Будьте в курсе новостей и трендов индустрии и используйте эту информацию для создания релевантных и своевременных постов для вашей аудитории.
- Используйте контент, созданный пользователями: Поощряйте своих подписчиков делиться своими впечатлениями и используйте эти материалы как вдохновение для ваших постов.
- Посмотрите на хэштеги: исследуйте и используйте релевантные хэштеги, чтобы увеличить видимость ваших постов и достичь более широкой аудитории. Это также может быть способом найти идеи для контента.
- Планируйте регулярные акции: делитесь своими предложениями и скидками, чтобы стимулировать вовлеченность и увеличивать продажи.
Разработав идеи, вы можете начать заполнять свой план социального медиа.
Просто заполните колонки от J до R своим «Заголовком/Темой», «Описанием» и т.п.
Шаг 5: Добавьте Примечания по Содержанию и Публикации
Начните с того, чтобы добавить к модели существенные детали, такие как ваши пояснения, ссылки на файлы контента, соответствующие хэштеги, временные метки публикации и мониторинговые ссылки (если применимо).
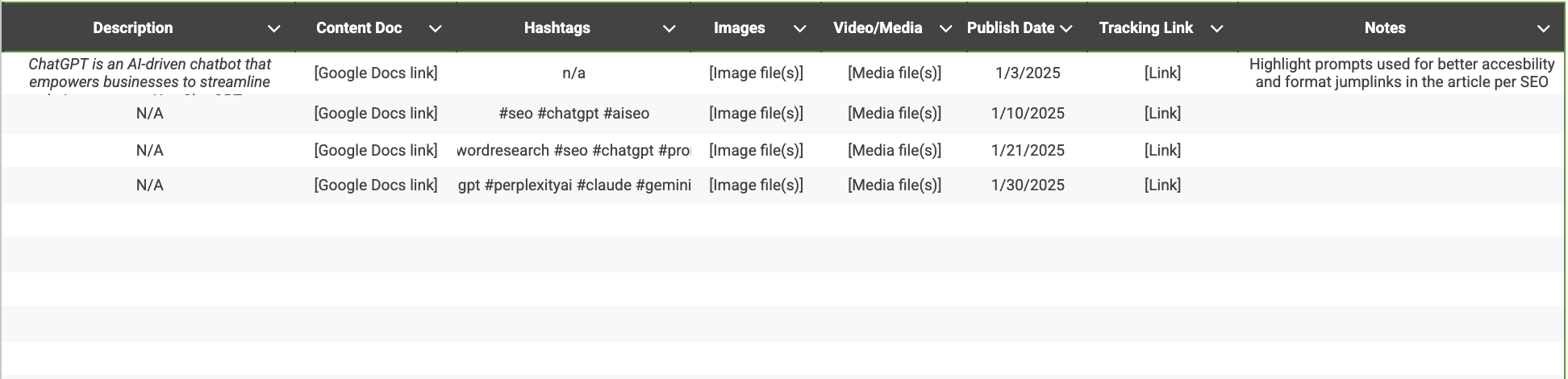
Можете добавить строки, столбцы или поля в соответствии с вашими потребностями.
В разделах «Изображения» и «Видео/Медиа», пожалуйста, указывайте ссылки на ресурсы, которые вы планируете использовать для контента в социальных сетях. Это можно сделать путем предоставления ссылки на папку с изображениями на Google Диске или любой другой выбранной вами системе управления цифровыми активами (DA).
Шаг 6: Добавьте Даты Публикации
После этого давайте заполним шаблон необходимыми деталями, такими как дата публикации и платформа для каждого запланированного поста.
Не забудьте обновить столбец «Статус» (I), когда будете работать над планом ваших социальных сетей.
Кроме того, вы можете использовать этот шаблон для отслеживания эффективности вашего контента путем включения таких показателей как ‘лайки’, ‘комментарии’ и ‘репосты’.
Шаг 7: Поделитесь с вашей командой
В условиях совместной работы убедитесь, что передали шаблон документа своим коллегам по команде и предоставили им права на редактирование для плавного сотрудничества.
Совместная работа обеспечивает единый и регулярный вид в социальных сетях.
В разделе ‘Примечания’ можете добавлять любую дополнительную информацию о предстоящих материалах, такую как детали, черновики, сроки и прочее. Эта область предназначена для совместной работы с вашей командой в вашем собственном темпе.
Шаг 8: Планируйте заранее и повторяйте.
Ранняя организация ваших публикаций в социальных сетях обеспечивает ряд преимуществ, значительно увеличивая вашу видимость в интернете.
Тщательное планирование контента позволяет вам регулярно делиться интересными статьями, которые захватывают внимание читателей, тем самым увеличивая взаимодействие и достижение желаемых результатов.
Имея хорошо структурированную стратегию контента под рукой, вы сможете создавать высококачественный материал, который идеально соответствует вашим общим маркетинговым целям, тем самым избегая потенциальных ошибок из-за поспешного и стихийного размещения публикаций.
Рекомендуется использовать планировщик социальных сетей для подготовки контента примерно на три месяца вперед. Таким образом можно избежать спешки в последний момент при создании текстов, сборе ресурсов и установлении времени публикации.
Планирование и публикация контента в социальных сетях как профессионал
Управление социальным медиа маркетингом не должно казаться сложным делом. Следуя эффективной стратегии, вы можете упорядочить и упростить свой план создания и распространения контента в социальных сетях.
За несколько часов каждый квартал вы можете эффективно запланировать свой контент заранее, избавляя себя от необходимости делать поспешные предположения при обновлении социальных сетей.
Как опытный специалист по SEO, я не могу переоценить важность использования шаблона планирования контента для стратегического и эффективного выбора тем. Этот инструмент позволяет мне принимать проактивный подход, поддерживая организованность моей работы и гарантируя соблюдение сроков. Со временем этот процесс планирования становится интуитивной привычкой вместо утомительной задачи.
С помощью планирования социальных сетей маркетологи получают:
- Система без лишних слов для отслеживания тем контента и планирования.
- Эффективность времени и ускоренная публикация.
- Последовательность в своевременном и актуальном размещении публикаций.
- Улучшенная видимость производительности и результатов.
Заходите и используйте бесплатный шаблон планирования социальных сетей, настройте его под свои нужды, тем самым оптимизируя задачи маркетинга в социальных сетях.
Смотрите также
- Акции EUTR. ЕвроТранс: прогноз акций.
- Акции FESH. ДВМП: прогноз акций.
- Акции CARM. КарМани: прогноз акций.
- Обновление алгоритма поиска Google для борьбы с явными дипфейками
- Google на YouTube «каннибализация» веб-контента
- Всплеск количества удаленных обзоров Google 17 сентября
- 12 основных шагов в создании успешной стратегии SEO
- Выпущен WordPress 6.7 – вот почему он победитель
- Почему согласованность со службой поддержки клиентов имеет решающее значение для PPC
- Правительство США перевело 8 миллионов долларов в биткоинах – это означает, что криптовалюты становятся всё более значимыми?
2025-06-13 16:40



