После очень нестабильного января для Google Search, я надеялся, что ситуация стабилизируется, но результаты все еще сильно колеблются и постоянно меняются.
Мы наблюдаем рост нестабильности на рынке, начиная с 2 февраля, и она стала более выраженной в последнее время. Я редко вижу такой уровень колебаний в инструментах отслеживания, если только Google официально не обновил свои основные алгоритмы.
Просто чтобы дать вам краткое обновление, я отслеживал несколько возможных изменений в том, как Google ранжирует результаты поиска. Они начались примерно 6 января и продолжились обновлениями 12, 15, 21, 26/27 и 29 января. До этого Google выпустил крупное обновление 11 декабря 2025 года, которое длилось до 29 декабря 2025 года. Мы наблюдали два значительных периода изменений в рамках этого обновления – примерно 13 и 20 декабря.
Google пока официально не подтвердил эти изменения, но есть некоторые признаки того, что они нацелены на низкокачественные, саморекламные списки статей. Гленн Гейб предполагает, что обновления зашли еще дальше, повлияв на то, как Google обрабатывает обзоры – аналогично их старой системе обзора продуктов.
Теперь мы видим еще больше активности.
SEO-болтовня
В сети было много обсуждений – в разделах комментариев этого сайта, а также на форумах, таких как WebmasterWorld и Black Hat World. Хотя большая часть из них посвящена снижению трафика, некоторые люди также сообщают о положительных результатах.
Резкое падение трафика сегодня, и я действительно не знаю почему. Самый плохой дневной трафик за последние 5 лет, и это даже не связано с основным обновлением.
Я заметил только увеличение продаж за последние два дня. Ничего из этого не поступало из Google, хотя. Все мои продажи поступают из Bing.
Трафик Google плоский и мёртв по всем направлениям.
У меня был огромный рост трафика во время обновления ядра в декабре и огромное падение трафика за последние пару недель. Кажется, он медленно восстанавливается, но мой доход составляет около 50%… Это старый веб-сайт, рынок США, которому более 15 лет. Раньше мы публиковали тонны оригинального контента. Изначально это было печатное издание, но теперь мы полагаемся на AI. Я сам журналист, поэтому я не просто копирую и вставляю, а редактирую и слежу за тем, чтобы добавить человеческий отпечаток… Тем не менее, рост и падение трафика без какой-либо логической закономерности действительно заставляет меня чувствовать, что мне нужно найти новый источник дохода… стрессовые времена. Не знаю, что делать больше 🙁
Похоже, Google наконец-то решил обнулить наш органический трафик.
Наблюдаю значительные изменения в ключевых словах по всем моим сайтам.. некоторые ключевые слова показывают большой рост, но трафик остается прежним.. возможно, это движение перед обновлением? Ощущается, что что-то надвигается.
Уже несколько дней полный беспорядок. Крупные перестановки.
Вижу одно и то же уже последние два года…. устойчивый градиент едва заметного наклона в отрицательном направлении.
Трафик резко упал и удерживается на минимальном уровне, согласно аналитике в режиме реального времени. Google Discover привлекает нецелевых посетителей из стран, где не говорят на моём языке. Они снова что-то делают с результатами поиска и Discover.
Да, на всех моих сайтах наблюдается массовый рост ключевых слов, однако трафик остаётся на прежнем уровне. Необычно, что все мои сайты затронуты одновременно, ещё более необычно, что по всем из них наблюдается положительная динамика. Возможно, они нашли способ устранить мусор?
Да, RPM резко упал на всех сайтах в портфеле моей компании. Трафик остаётся на уровне вчерашнего дня, то есть слабый, но я думаю, что качество трафика находится на самом дне, поэтому RPM на 50-60% ниже уровня вчерашнего дня
Еще один хороший день по трафику на всех сайтах, особенно на моем глобальном сайте, однако заметно, что Запад не так активен, как раньше, Евразия — вот где сейчас все самое интересное. Mr MSFT посетил несколько раз сегодня утром, на самом деле, кроме MSFT, Amazon посетил один сайт с новым диапазоном IP-адресов… Заблокировано
Я тоже это видел. 3 дня очень хорошего трафика. Но вчера вечером: БАМ. Большое падение.
Ранжирование Google в последнее время было довольно нестабильным. Вы заметили аналогичные изменения за последний месяц?
Я вижу схожие колебания, особенно в конкурентных нишах. Позиции, похоже, чаще меняются даже без серьезных изменений в SEO, что больше похоже на перекалибровку Google сигналов качества и намерений, а не на санкции. Сайты с сильным тематическим авторитетом и доверием к бренду, похоже, стабилизируются быстрее.
Я заметил ту же закономерность в нескольких проектах. Рейтинги резко падают, а затем частично восстанавливаются без каких-либо серьезных изменений, что говорит о тестировании алгоритма, а не о чем-то специфичном для сайта.
Да, Google демонстрирует заметные колебания в рейтингах в последнее время, особенно в конкурентных нишах, таких как партнерский маркетинг и высококонкурентные ключевые слова. Необычно, когда позиции меняются день ото дня даже без изменений на странице, и многие SEO-специалисты сообщают о подобной волатильности без какого-либо официального подтверждения обновления.
Да, я тоже огромный провал.
Привет! Это выпуск наших ‘Заметок об обновлениях обзоров’ от 4 февраля. Звучит не так же, как ‘Заметки об основных обновлениях’, но работает! Мы полагаем, что это было обновление обзоров, хотя Google перестала официально их объявлять некоторое время назад, потому что система сейчас…
— Glenn Gabe (@glenngabe) February 4, 2026
Инструменты отслеживания Google
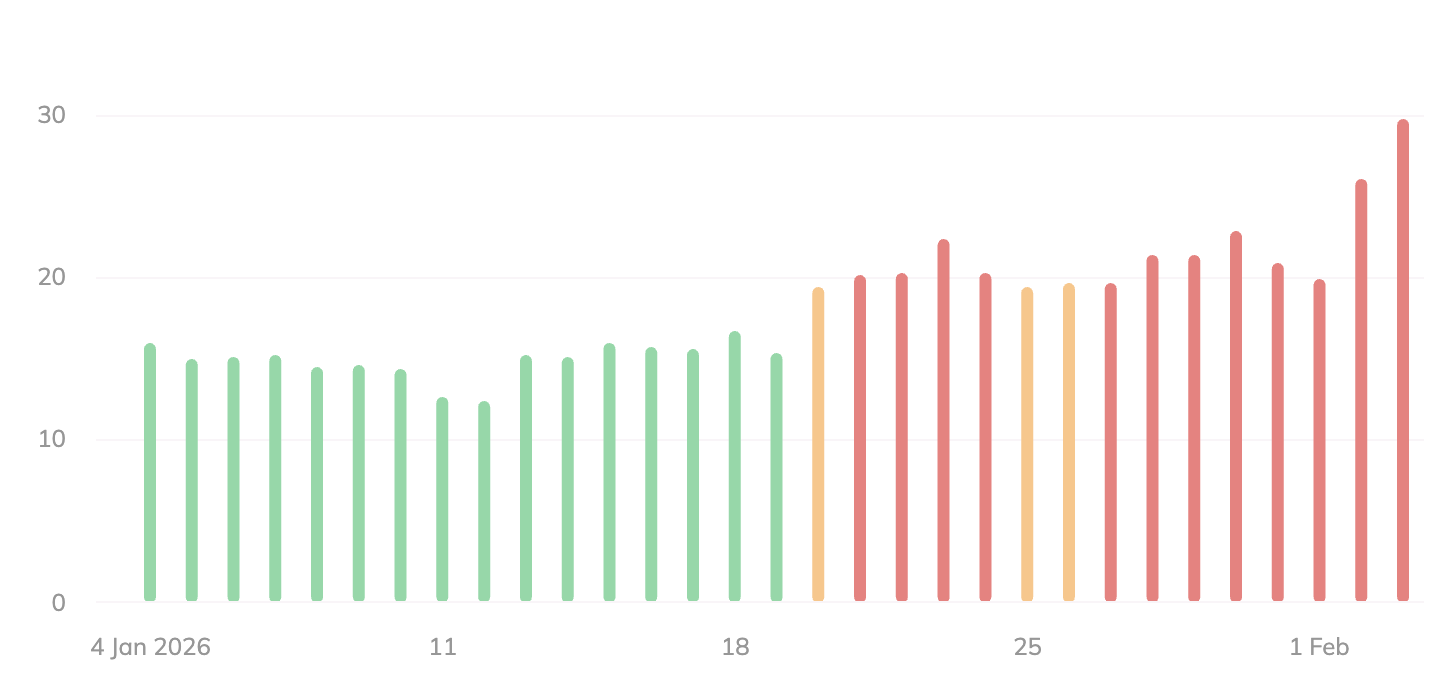
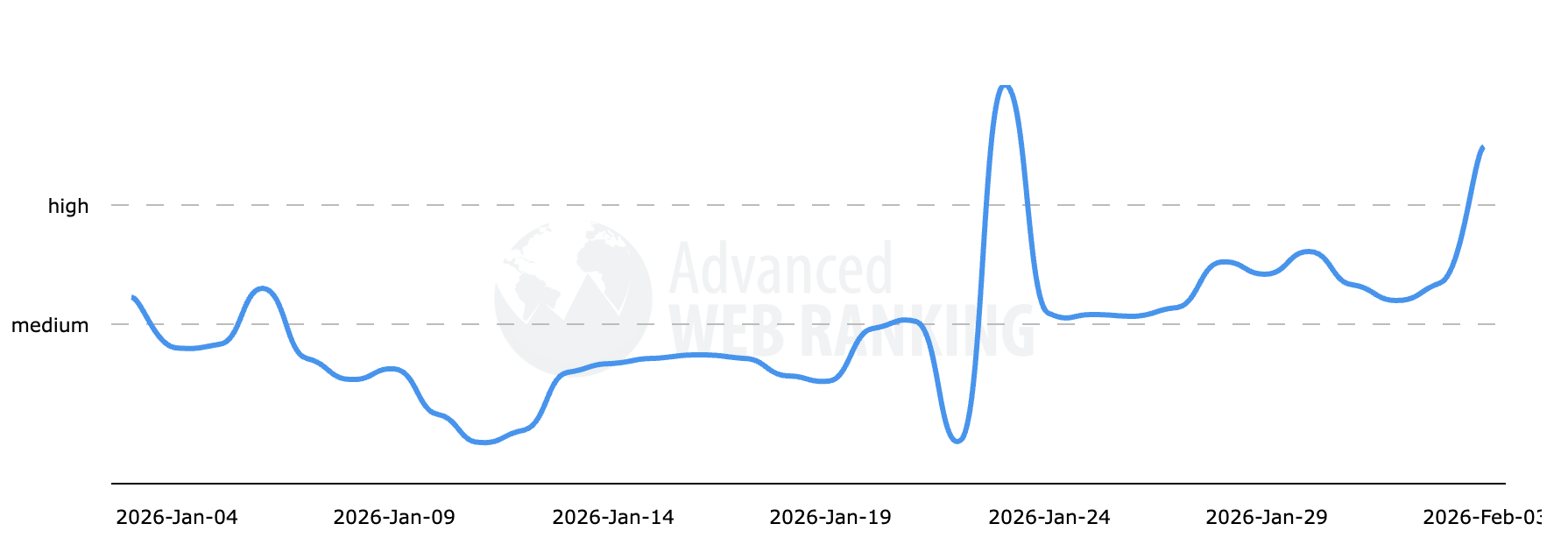
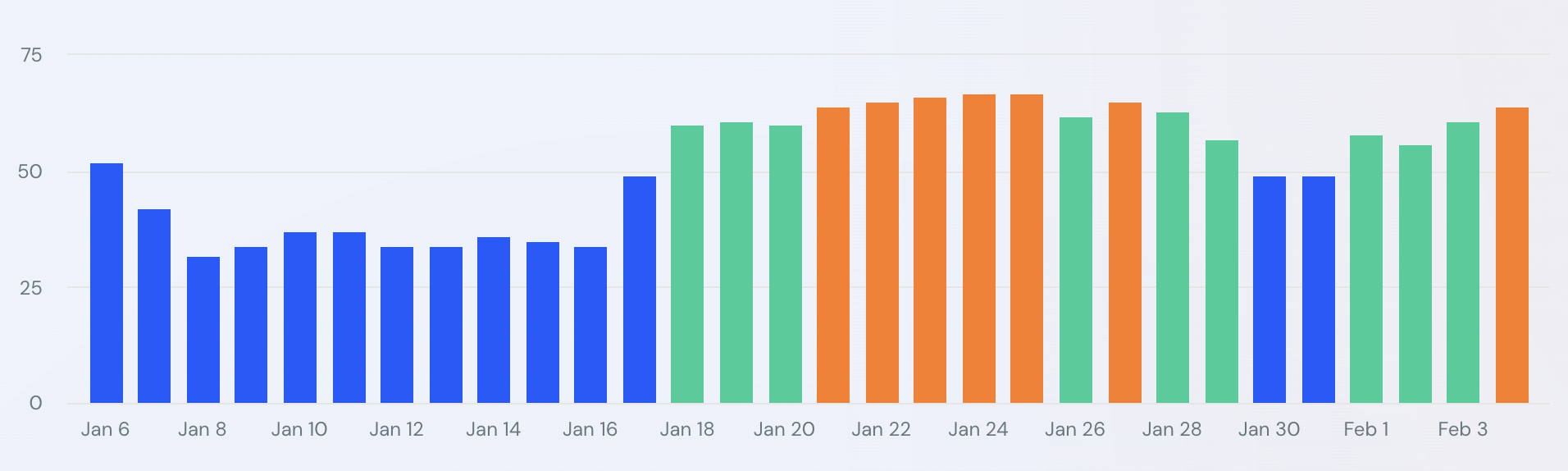
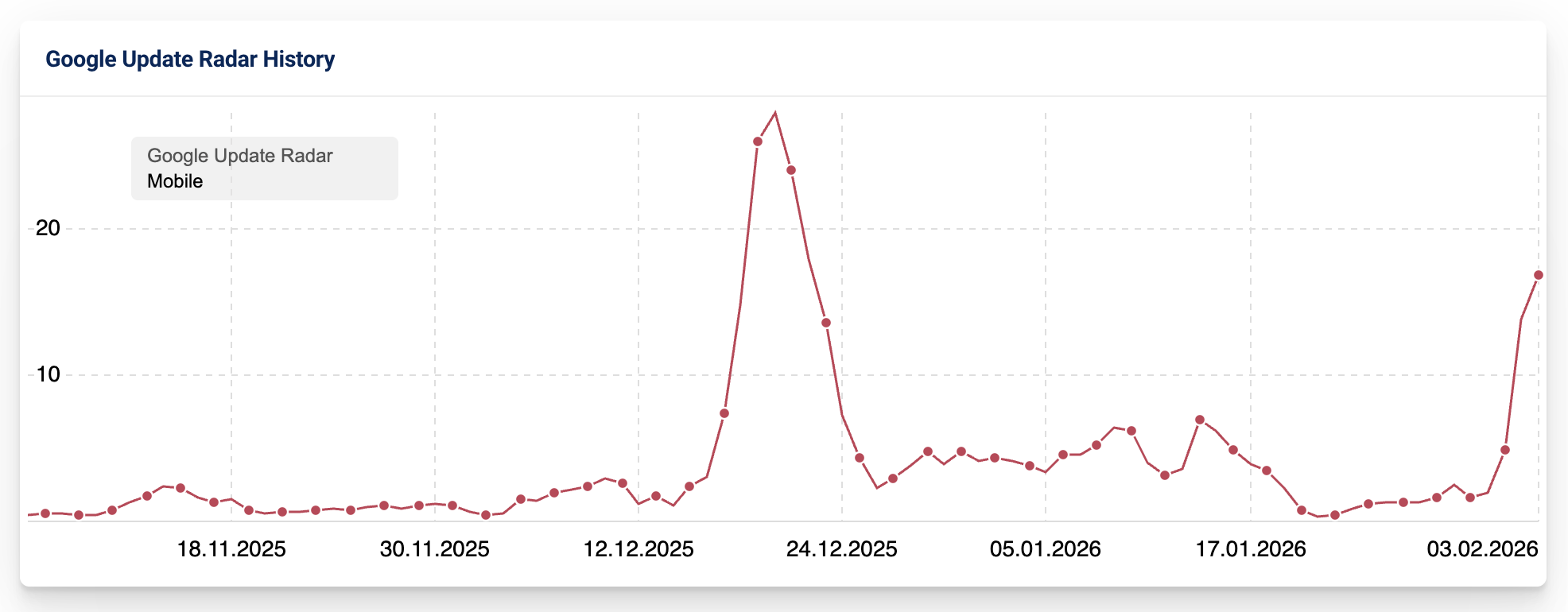
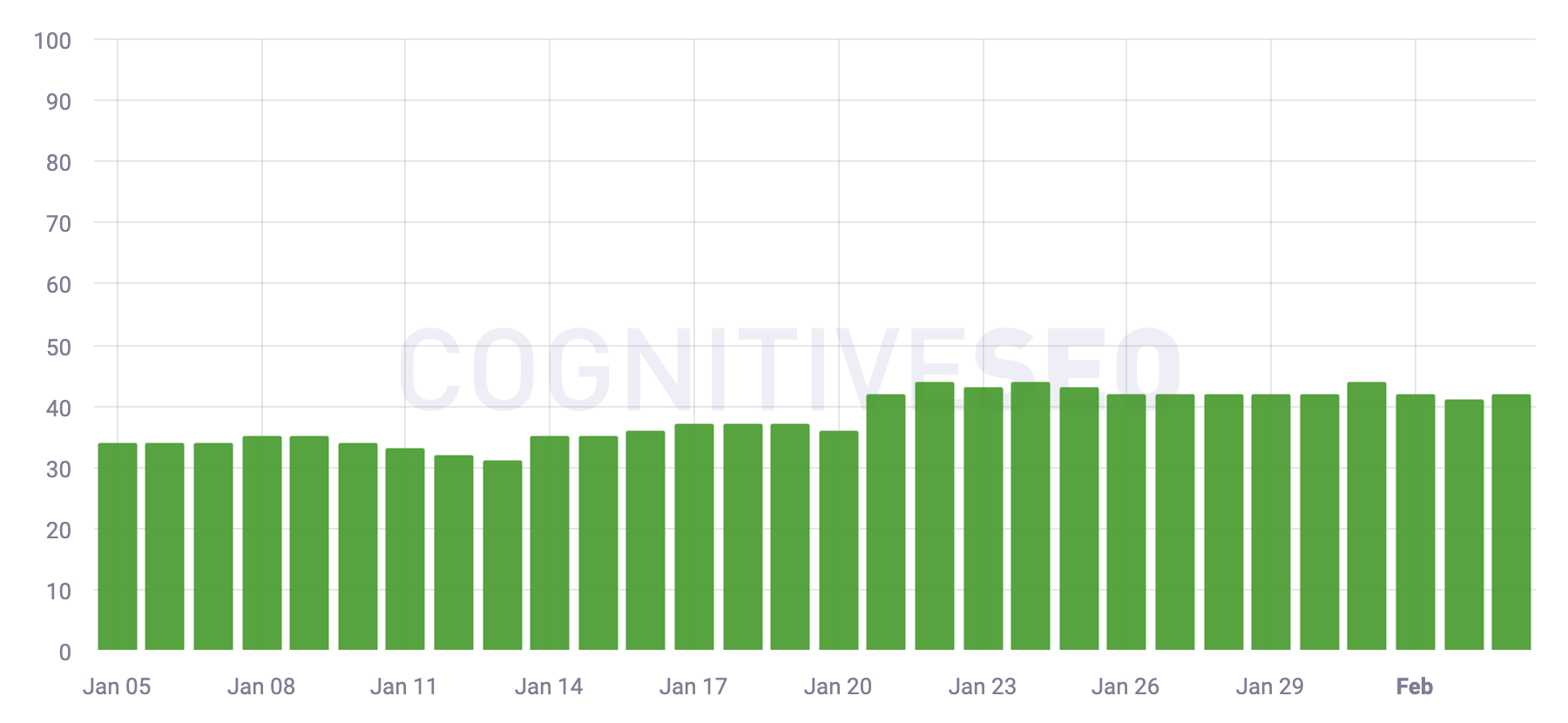
Посмотрите, насколько разогреваются большинство этих отслеживающих инструментов.
Semrush:
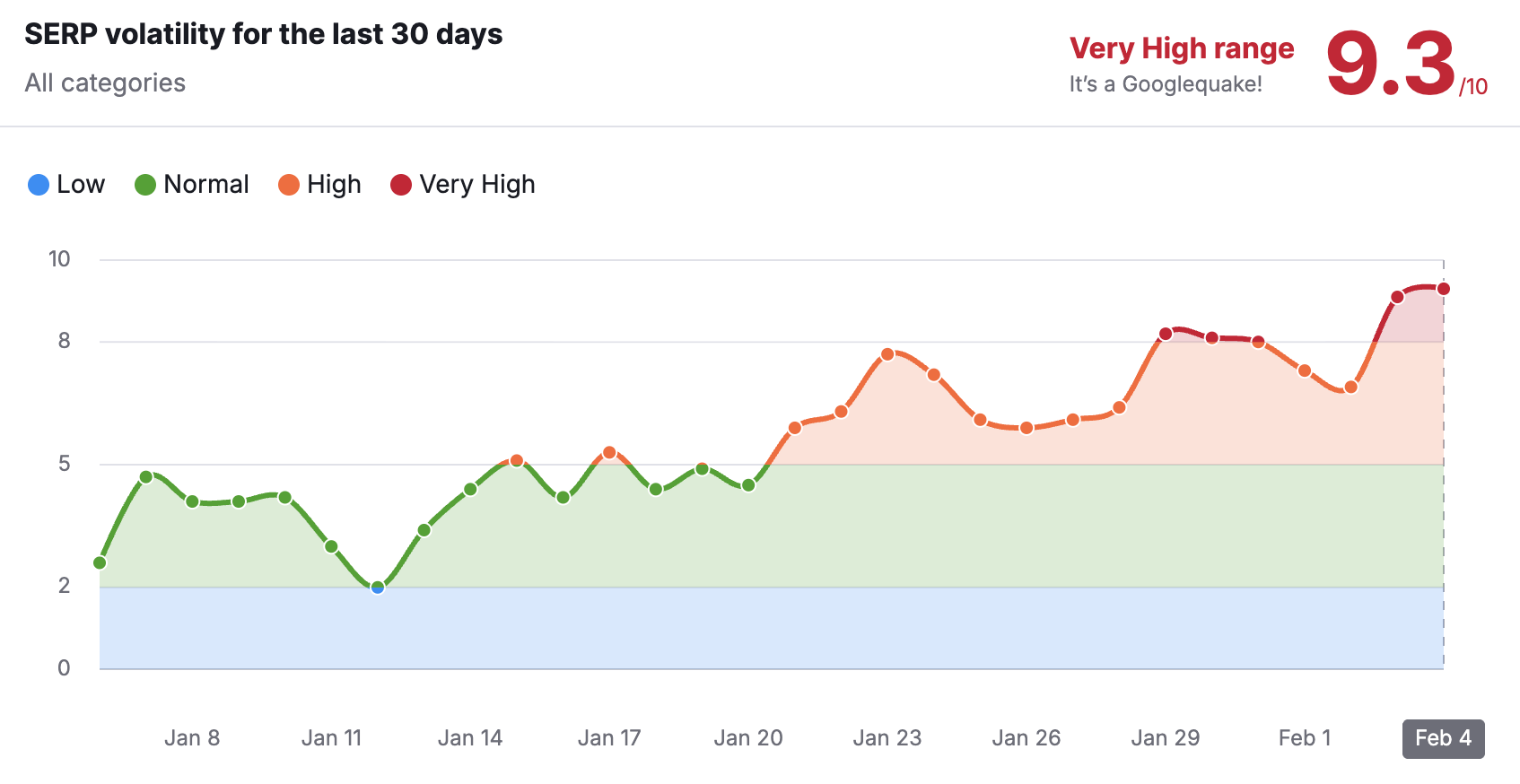
Accuranker:
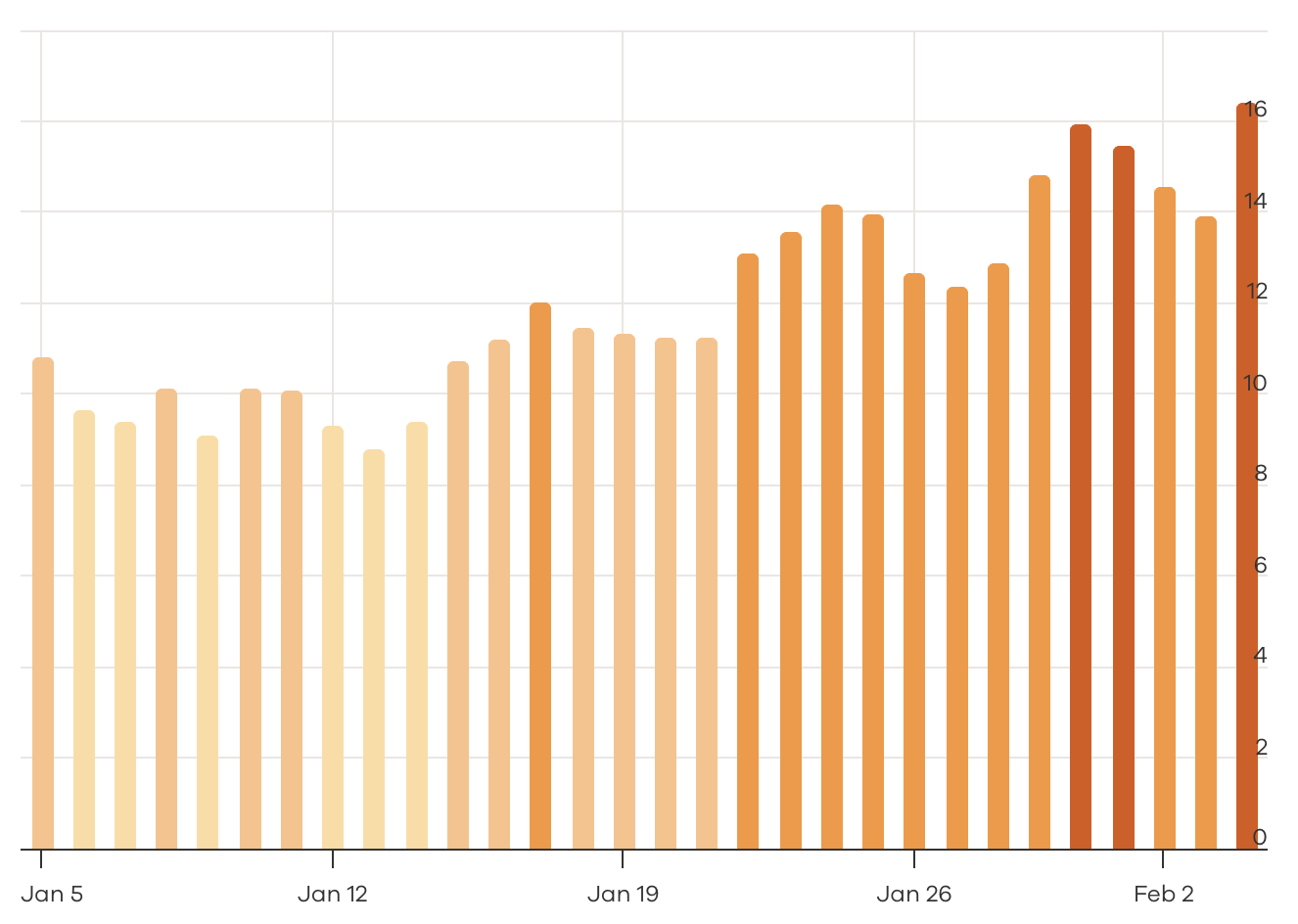
Wincher:
Advanced Web Rankings:
SimilarWeb:
Sistrix:
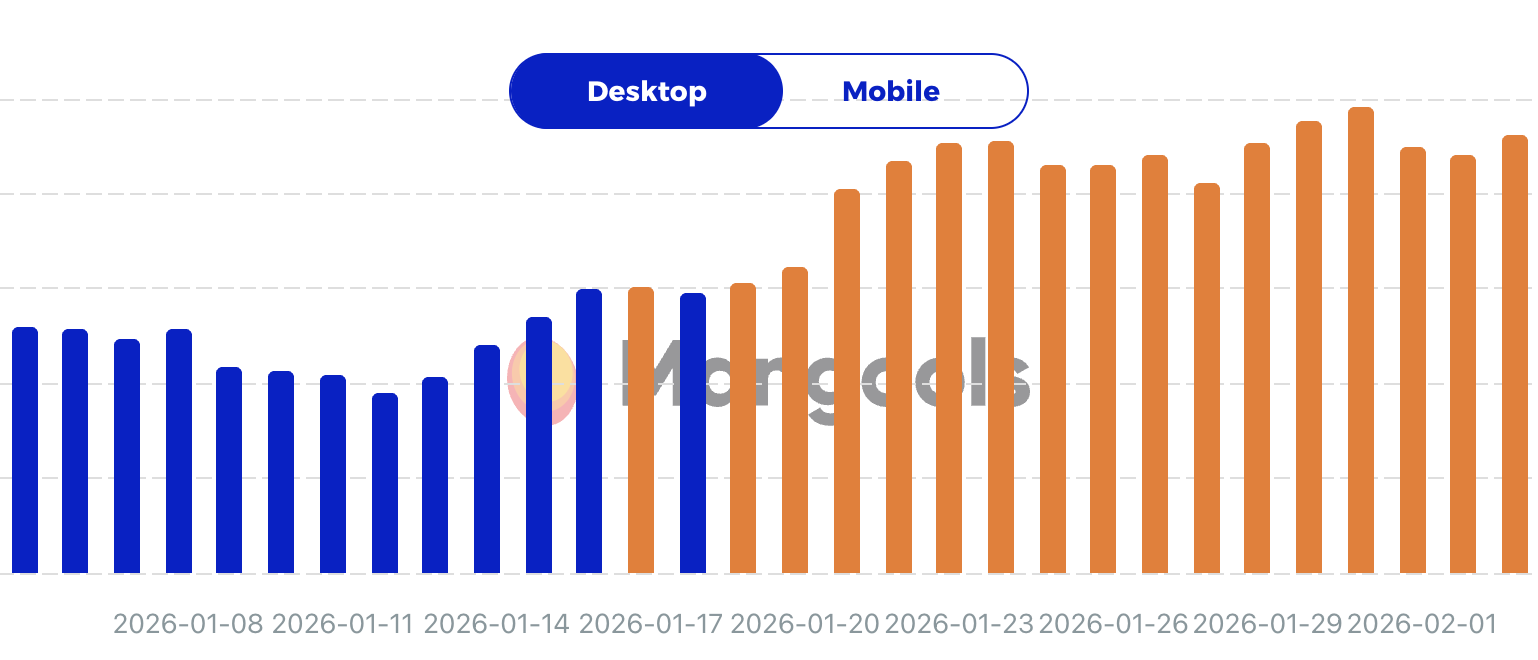
Mangools:
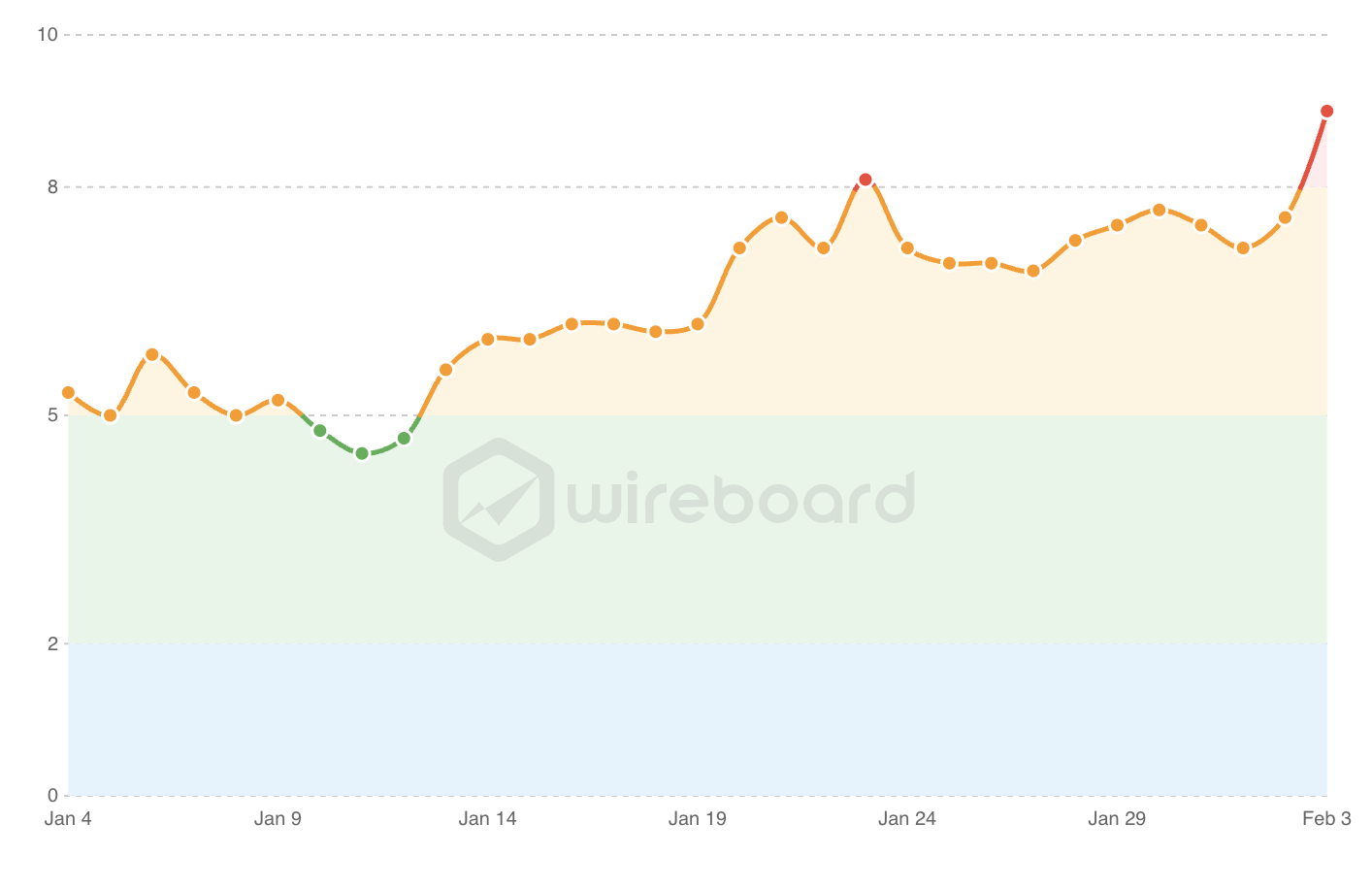
Агрегатор инструментов Wiredboard объединяет данные из инструментов, перечисленных выше, и отображает их все на одном графике.
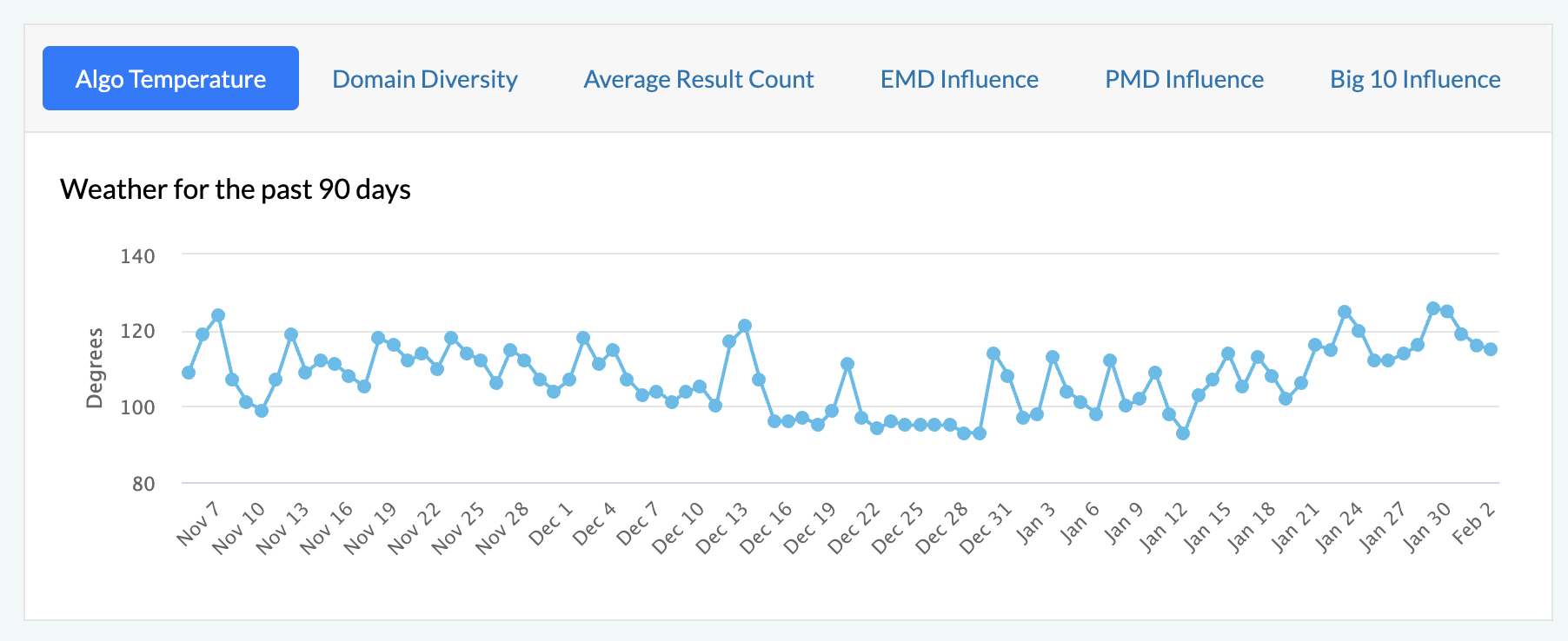
Mozcast:
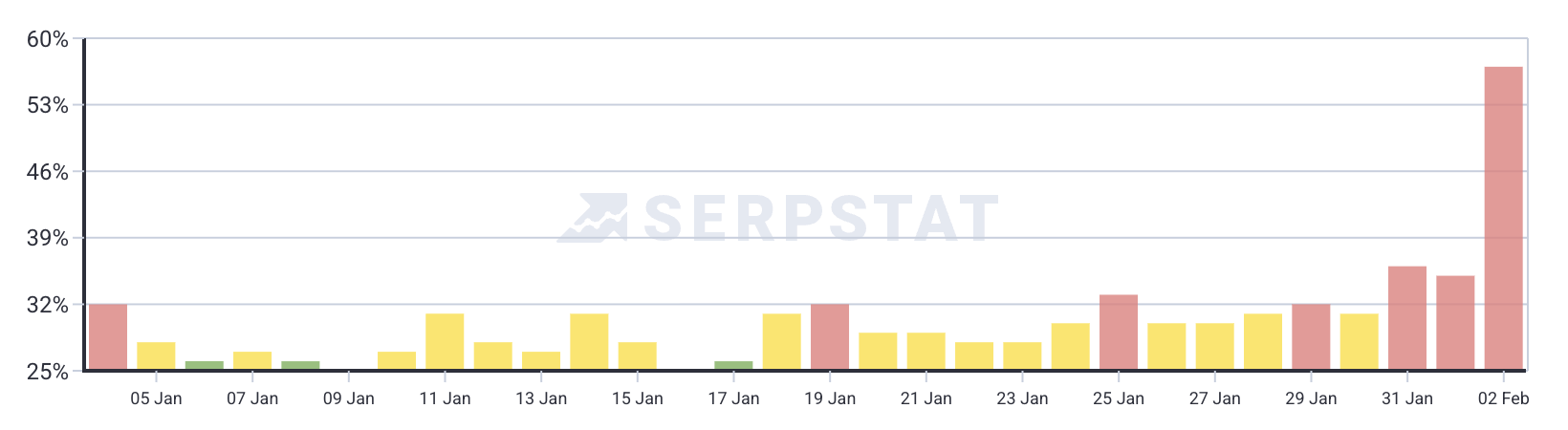
SERPstat:
Данные для SEO:
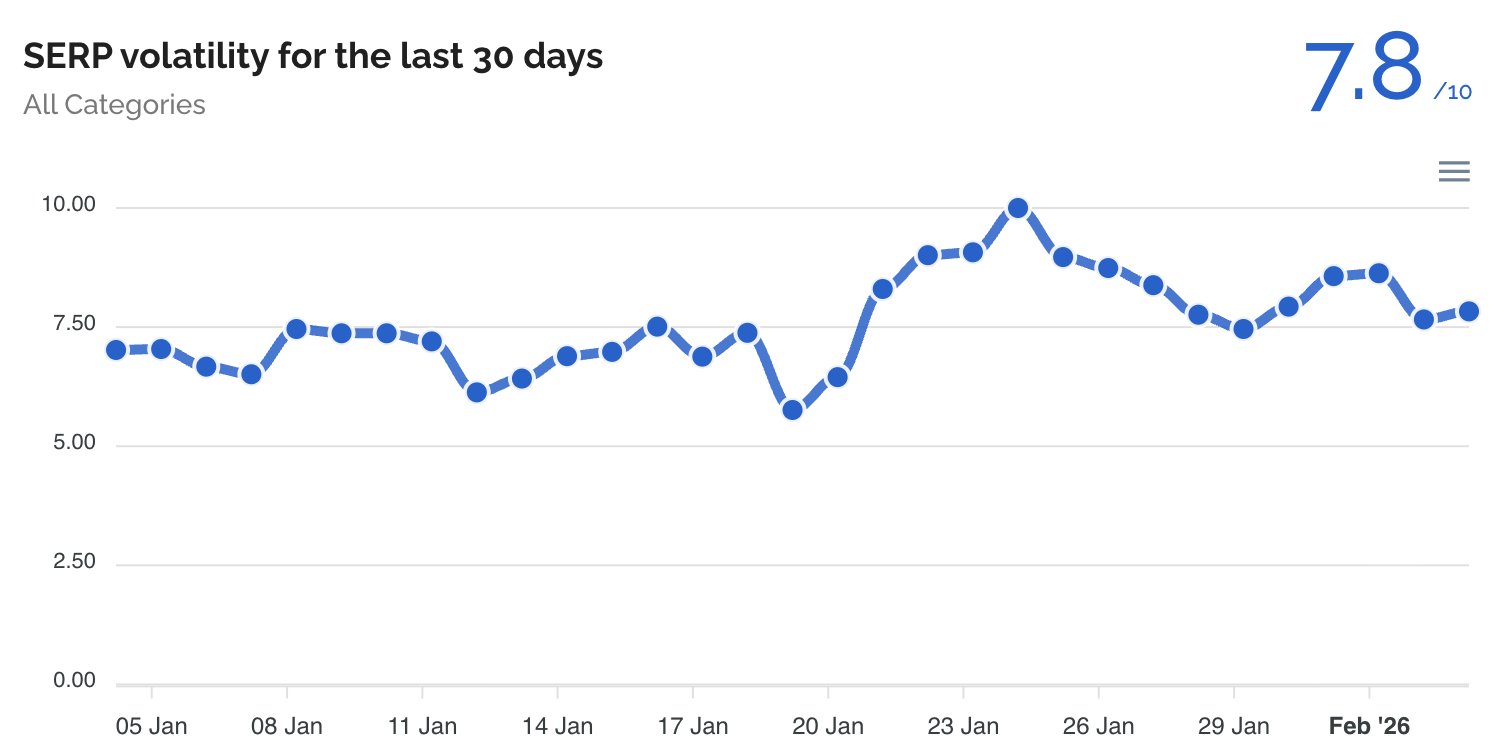
Algoroo:
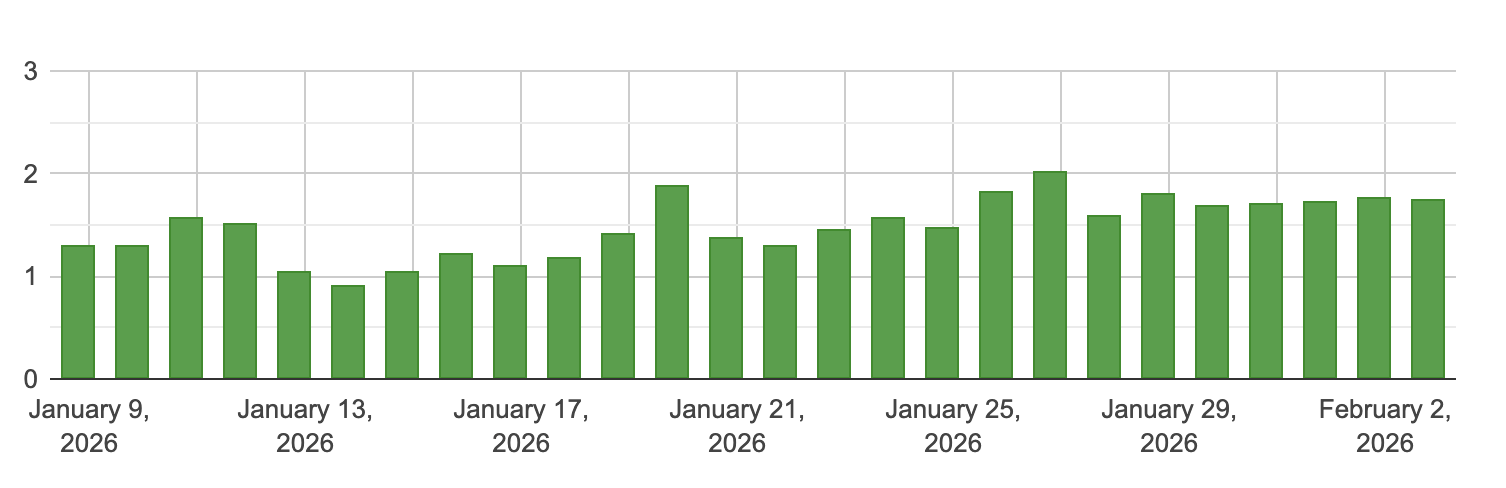
Zutrix:
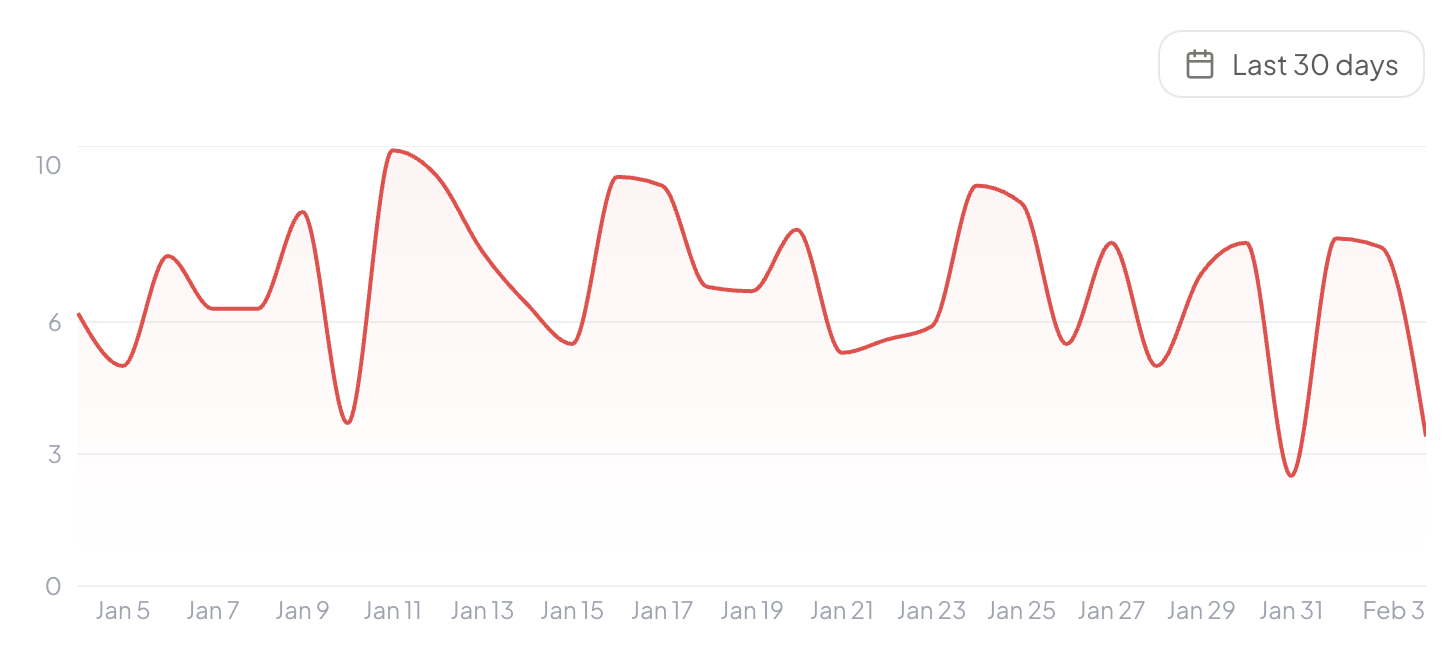
CognitiveSEO:
Смотрите также
2026-02-04 16:46