Джон Мюллер из Google затронул идею предоставления простых страниц в формате markdown непосредственно AI-краулерам и ботам. Хотя он и не дал однозначного ответа «да» или «нет», он выделил несколько потенциальных проблем и моментов, которые следует учитывать, если вы решите это сделать.
Markdown — это простой способ форматирования текста с использованием специальных символов. Он используется для создания документов, которые можно легко преобразовать в HTML, делая их доступными для просмотра в веб-браузерах.
Кто-то на Reddit спросил о потенциальных преимуществах и опасностях предоставления моделям ИИ для обработки текста в формате raw Markdown.
Джон ответил с этими опасениями:
- Вы уверены, что они вообще могут распознать MD на веб-сайте как что-то отличное от текстового файла?
- Могут ли они разбирать и переходить по ссылкам?
- Что произойдет с внутренней перелинковкой вашего сайта, заголовком, нижним колонтитулом, боковой панелью, навигацией?
- Одно дело вручную дать ему MD файл, а совсем другое — предоставить ему текстовый файл, когда они ищут HTML страницу.
Джон опубликовал пост в Bluesky, критикуя практику преобразования веб-страниц в markdown. Он отметил, что большие языковые модели на самом деле могут обрабатывать изображения, предполагая, что было бы проще просто использовать изображения для всего веб-сайта.
Поэтому имейте в виду эти вопросы, когда будете рассматривать возможность сделать это.
Благодарность Gagan за это: Hat tip to Gagan on this:
Задумываетесь об использовании markdown файлов для краулеров больших языковых моделей (LLM)? Джон Мюллер из Google поднял некоторые вопросы о том, могут ли краулеры правильно распознавать и обрабатывать markdown файлы на веб-сайте, или они видят их просто как обычный текст. Он также спрашивает, как это может повлиять на внутренние ссылки и заголовки на вашем сайте.
‘ Gagan Ghotra (@gaganghotra_) February 3, 2026
Также ознакомьтесь:
Я недавно добавил функцию на свой веб-сайт, которая позволяет инструментам искусственного интеллекта и поисковым системам получать доступ к страницам в упрощенном текстовом формате. Я думал, что это будет использоваться несколько раз, но в течение часа я получал сотни запросов от AI ботов, таких как ClaudeBot, GPTBot и OpenAI’s SearchBot!
‘ Dries Buytaert (@Dries) January 14, 2026
Смотрите также
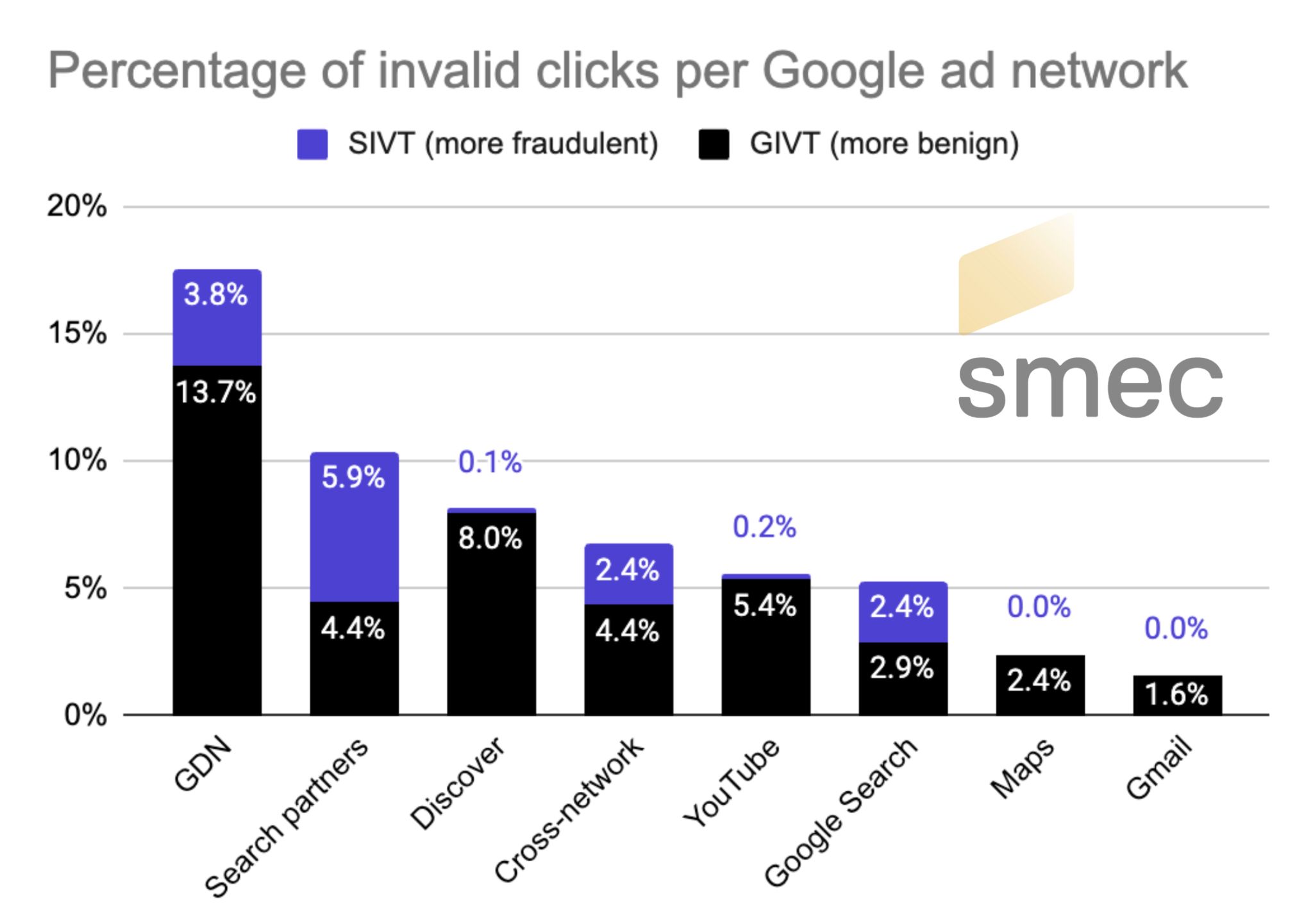
- Акции CBOM. МКБ: прогноз акций.
- Акции LSNG. Ленэнерго: прогноз акций.
- Анализ динамики цен на криптовалюту CRV: прогнозы CRV
- Как оптимизировать свой сайт электронной торговли для праздничных покупателей
- Приложение DeepSeek запрещёно в Германии из-за нелегального передачи пользовательских данных.
- Мы разобрались как работают обзоры искусственного интеллекта (& построили инструмент, чтобы доказать это)
- Какой самый низкий курс евро к тайскому бату?
- Сколько времени должна занять SEO-миграция? [Исследование обновлено]
- Танец бычьего роста Биткойна: сможет ли он вальсировать до 144,000 долларов?
- Акции WUSH. Whoosh: прогноз акций.
2026-02-04 15:44