

Целью поиска является тема с множеством аспектов. Например, её можно исследовать используя продвинутые методы машинного обучения, такие как глубокое обучение, которое помогает классифицировать поисковые запросы на основе их значения; или же использовать методы обработки естественного языка (NLP) для анализа заголовков страниц выдачи поисковых систем (SERP). Кроме того, может применяться группировка результатов на основе семантической близости, при этом каждый метод предлагает свой набор преимуществ.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Помимо простого понимания преимуществ интерпретации поискового намерения, мы располагаем различными стратегиями как для крупномасштабного применения, так и для автоматизации.
Так почему же нам нужна ещё одна статья об автоматизации намерений поиска?
Намерение поиска становится всё более важным сейчас, когда появился поиск на базе искусственного интеллекта.
Во времена традиционных поисковых систем, где доминировали десять синих ссылок, основной задачей было предоставление большего количества результатов. Но когда речь идет об AI-управляемых технологиях поиска, я стремлюсь минимизировать вычислительные затраты на операцию (FLOPs), чтобы гарантировать бесперебойное и эффективное обслуживание.
В SERP по-прежнему содержатся лучшие идеи относительно поисковых намерений.
Пока что методы состоят из двух подходов. Во-первых, вы собираете весь текст заголовков наиболее высоко ранжированного контента по определенному ключевому слову и затем используете эти данные для обучения и валидации модели нейронной сети, которую вам нужно спроектировать и протестировать. Второй вариант — это использование обработки естественного языка (NLP) для группировки ключевых слов.
Если у вас нет времени или знаний, чтобы создать свой собственный искусственный интеллект или использовать API от OpenAI?
Хотя многие эксперты по SEO хвалят косинусное сходство как инструмент для определения границ тем в таксономии и архитектуре веб-сайта, я продолжаю считать, что группировка результатов поиска на основе их выдачи SERP (страницы результатов поисковой системы) предлагает значительно лучший подход.
ИИ фокусируется на оптимизации результатов поиска поисковых систем (SERP), по уважительной причине, так как он моделирован вокруг паттернов поведения пользователей.
Альтернативный подход использует встроенные возможности искусственного интеллекта Google для автоматического выполнения задач, обходя необходимость ручного сбора содержимого страниц результатов поиска (SERP) и создания собственной модели ИИ.
Проще говоря, когда Google отображает сайты в ответ на запрос поиска, это происходит исходя из того, насколько вероятно содержание сайта соответствует заданному вопросу. Если два поисковых запроса имеют одинаковую цель, результаты поиска скорее всего будут очень похожи.
В течение продолжительного времени многие SEO-специалисты исследовали страницы результатов поиска (SERP) по ключевым словам для определения общих поисковых намерений как способ быть в курсе основных обновлений алгоритмов поисковиков. Иными словами, они занимались этим достаточно долго, чтобы адаптироваться к изменениям в алгоритмах. Таким образом, эта практика не является совершенно новой и инновационной.
Основное преимущество заключается в автоматизации и расширении этого процесса сравнения, обеспечивающего скорость и повышенную точность.
Как Кластеризовать Ключевые Слова по Запросам Пользователей в Масштабе с Помощью Python (с Кодом)
Предполагая, что у вас есть результаты поисковых запросов в формате CSV-файла, давайте импортируем их в вашу записную книжку Python.
1. Импортируйте список в ваш блокнот на Python
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
Ниже представлен файл SERP, теперь импортированный в DataFrame панды.
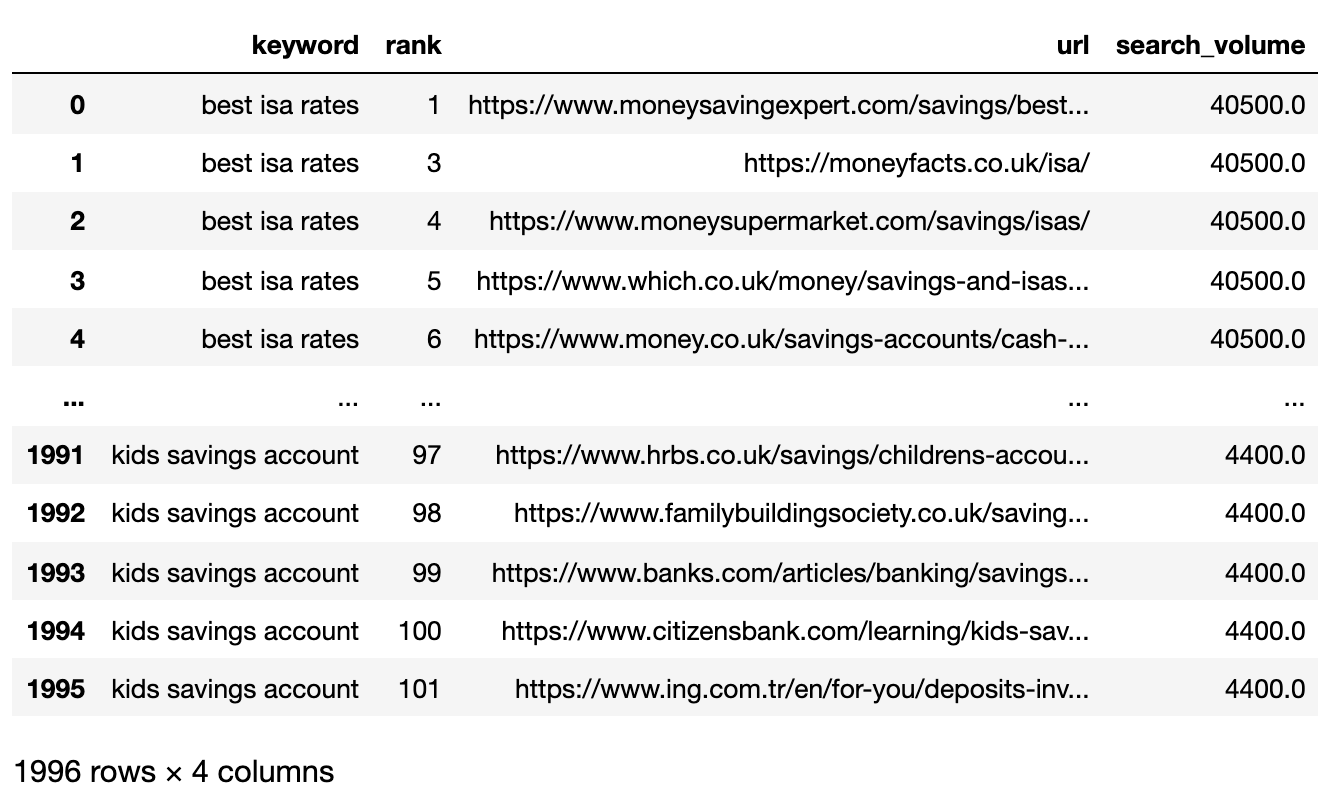
Отфильтруйте данные для первой страницы
Мы хотим сравнить результаты первой страницы каждой поисковой выдачи по ключевым словам.
Как опытный вебмастер, я предпочитаю разбивать наш датафрейм на более мелкие и управляемые DataFrame по ключевым словам. Таким образом, можно эффективно применять функцию фильтрации по каждому ключевому слову отдельно. После фильтрации эти маленькие DataFrame затем плавно объединяются обратно в один общий DataFrame, гарантируя эффективное таргетирование ключевых слов.
# Split
serps_grpby_keyword = serps_input.groupby("keyword")
k_urls = 15
# Apply Combine
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
return filtered_df
filtered_serps = serps_grpby_keyword.apply(filter_k_urls)
# Combine
## Add prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with initial data frame
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
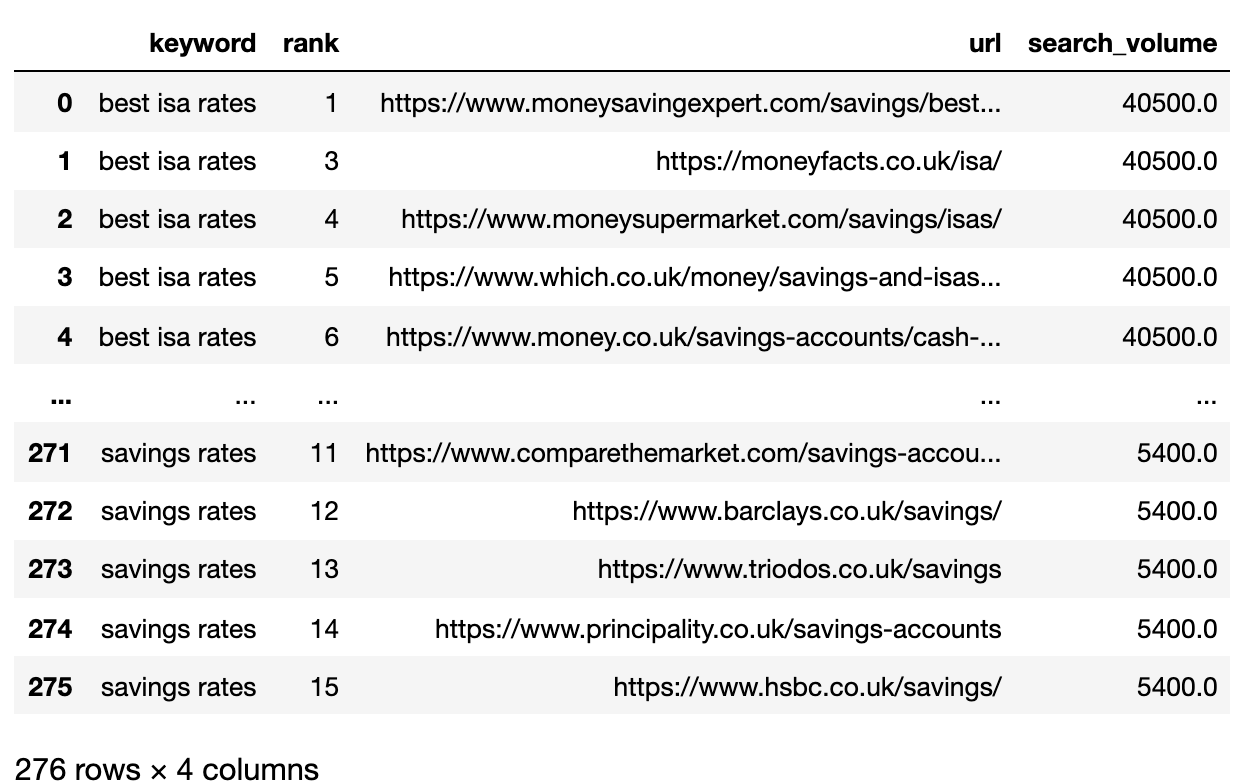
Преобразуйте URL рейтинга в строку
Поскольку URL-адреса из результатов поисковых систем превосходят количество уникальных ключевых слов, необходимо сократить эти URL-ы до краткого однострочного представления поисковой выдачи по ключевому слову.
Вот как:
# convert results to strings using Split Apply Combine
filtserps_grpby_keyword = filtered_serps_df.groupby("keyword")
def string_serps(df):
df['serp_string'] = ''.join(df['url'])
return df # Combine strung_serps = filtserps_grpby_keyword.apply(string_serps)
# Concatenate with initial data frame and clean
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Ниже показана страница результатов поиска (SERP), сжатая в одну строку для каждого ключевого слова.
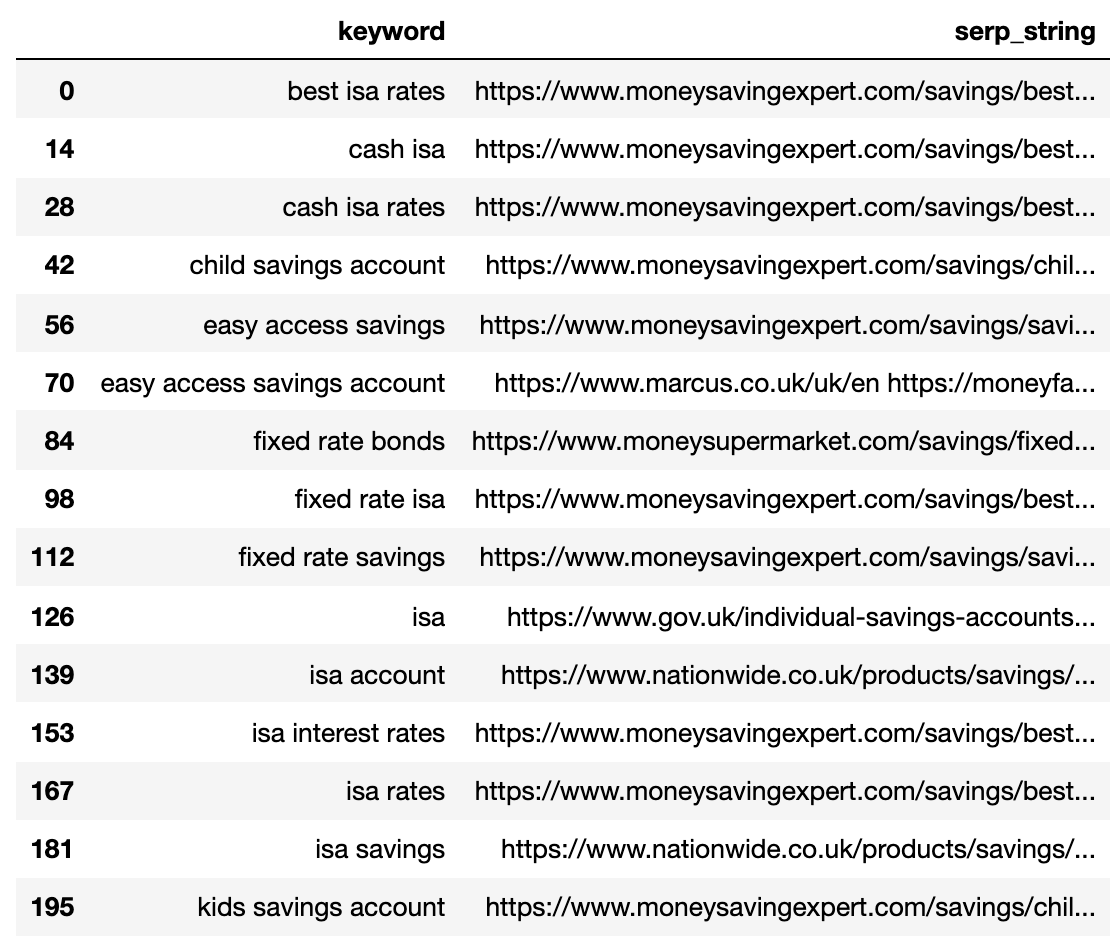
Сравните расстояние SERP
Для выполнения сравнения нам теперь нужны все комбинации ключевых слов SERP с другими парами:
# align serps
def serps_align(k, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'keyword': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'keyword': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'keyword'})
return prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.keyword.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

Информация, представленная в данном контексте, включает все возможные комбинации ключевых слов и их страницы результатов поисковых систем (SERP), что позволяет провести прямое сравнение строк SERP.
Функция serp_compare оценивает схожесть в расположении и внешнем виде веб-сайтов на страницах результатов поисковых систем (SERP).
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]

Теперь, когда сравнительный анализ завершен, можно начать кластеризацию ключевых слов.
Мы будем обрабатывать любые ключевые слова, которые имеют взвешенную схожесть не менее 40%.
# group keywords by search intent
simi_lim = 0.4
# join search volume
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append topic vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'keyword', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'keyword': 'topic', 'keyword_b': 'keyword',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NAN
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
We now have the potential topic name, keywords SERP similarity, and search volumes of each.
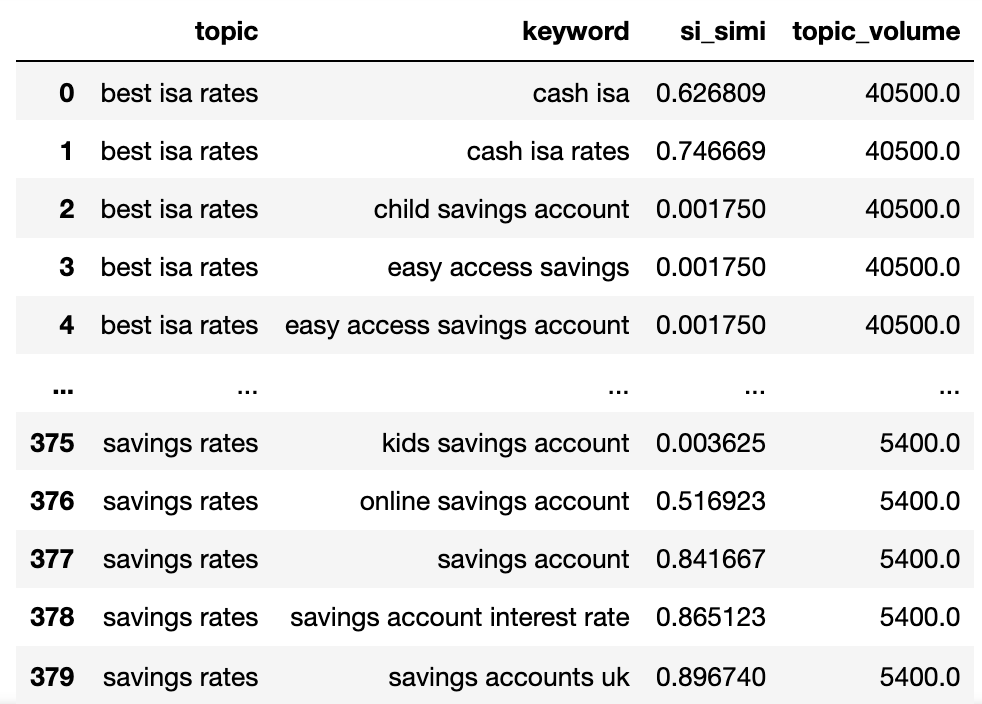
Заметьте, что ключевые слова keyword и keyword_b были переименованы в тему (topic) и ключевое слово (keyword), соответственно.
Теперь мы будем перебирать столбцы в DataFrame, используя технику лямбда-функций.
Использование лямбда-подхода является упрощённым методом для итерации по строкам pandas DataFrame, так как он преобразует каждую строку в список вместо непосредственного использования функции .iterrows().
Вот идет:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
Словарь ниже сортирует ключевые слова согласно их целям поиска и присваивает им номера:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}Давайте добавим это в DataFrame.
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
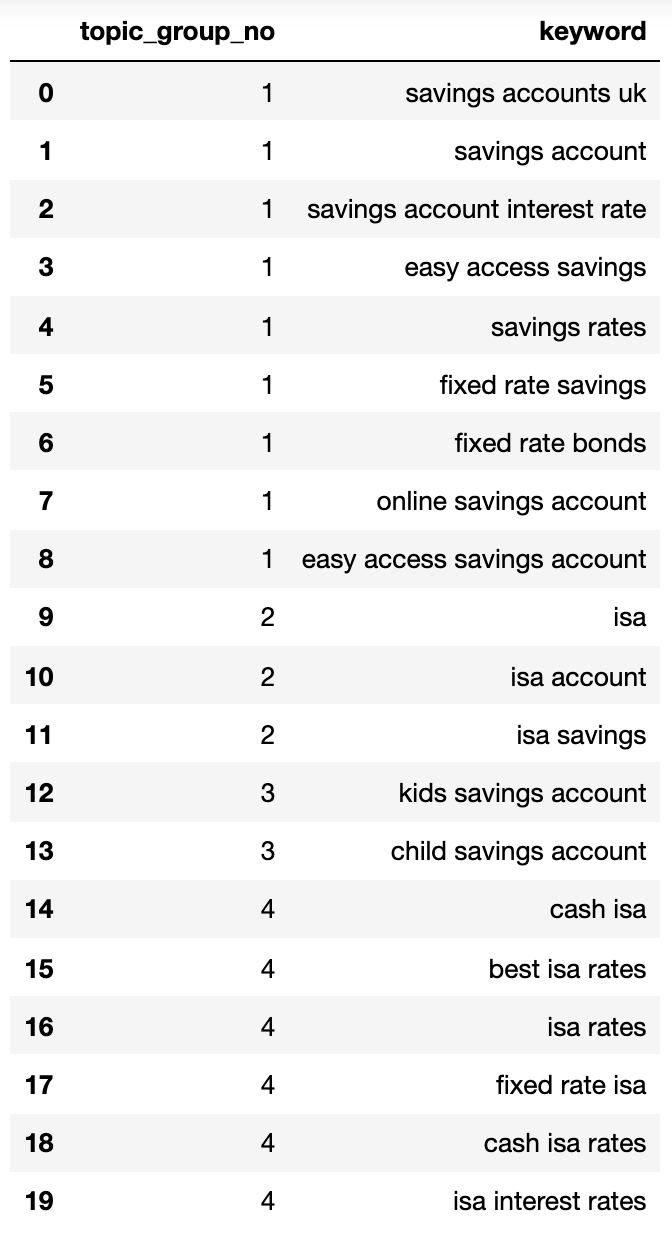
Группированные поисковые запросы выше представляют собой разумное представление ключевых терминов в них, что обычно является задачей специалиста по SEO.
Подход, даже при ограниченном наборе ключевых слов, ясно адаптирован к обработке значительно больших наборов, потенциально десятков тысяч или даже более.
Активация выходов для улучшения вашего поиска
Абсолютно верно, я обнаружил, что более глубокое изучение области нейронных сетей может значительно повысить точность кластеризации контента. Используя эти продвинутые технологии, мы можем улучшить процесс обработки ранжированного содержания, приводя к более точным кластерам и даже более умным названиям групп. На самом деле, некоторые коммерческие решения уже используют этот подход.
Пока что с этим результатом вы можете:
- Добавьте это в свои системы анализа данных для SEO, чтобы сделать отчеты о трендах и SEO более значимыми.
- Стройте более эффективные платные поисковые кампании, организуя свои аккаунты в Google Ads по интенту поиска (поиска) для повышения оценки качества.
- Объедините повторяющиеся URL поиска в экосистеме электронной коммерции.
- Структурируйте таксономию сайта электронной коммерции в соответствии с намерениями поиска вместо обычного каталога товаров.
Конечно, возможно есть другие приложения, которые я не упомянул — пожалуйста, поделитесь значимыми приложениями, о которых вы думаете, что я их пропустил.
Действительно, процесс исследования ключевых слов SEO стал более эффективным, точным и быстрым для Вас!
Загрузите полный код здесь для личного использования.
Смотрите также
- Часть 1. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Акции CBOM. МКБ: прогноз акций.
- Акции SGZH. Сегежа: прогноз акций.
- Акции TGKN. ТГК-14: прогноз акций.
- Часть 2. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Акции привилегированные SBERP. Сбербанк: прогноз акций привилегированных.
- Google может меньше полагаться на Hreflang и перейти на автоматическое определение языка
- Контролируя Вашу Розничную Позицию Онлайн С помощью SEO
- Акции SBER. Сбербанк: прогноз акций.
- Акции LSNG. Ленэнерго: прогноз акций.
2025-05-29 04:12