

В этой статье описывается процесс проверки гипотез SEO посредством сплит-тестирования. Автор подчеркивает важность наличия достаточно большого размера выборки для обеспечения статистической значимости и достоверности результатов тестирования. Они предлагают использовать функцию Python np.where для назначения URL-адресов между тестовыми и контрольными группами на основе различных критериев, таких как шаблон URL-адреса или тип контента.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Работа на веб-сайтах со значительным трафиком приносит равные риски и выгоды при применении рекомендаций по SEO.
Как опытный веб-мастер, я понял, что реализация стратегий SEO сопряжена с собственным набором рисков. Одним из потенциальных недостатков являются непредвиденные последствия изменений в факторах ранжирования поисковых систем. Чтобы снизить этот риск, я бы рекомендовал использовать модели машинного обучения для предварительного тестирования. Поступая таким образом, вы можете смоделировать влияние различных тактик SEO на рейтинг в поисковых системах, прежде чем вносить какие-либо постоянные изменения на свой веб-сайт. Такой подход позволяет принимать обоснованные решения и минимизировать вероятность негативного исхода.
Прежде чем принять решение о внедрении стратегии SEO по всему сайту, важно провести сплит-тестирование как более надежный метод, чем просто предварительное тестирование.
Мы рассмотрим шаги, необходимые для использования Python для проверки ваших теорий SEO.
Выбирайте ранговые позиции
Одним из препятствий при проверке гипотез SEO является необходимость в существенных наборах данных, чтобы гарантировать статистически значимые результаты тестов.
«Уилл Кричлоу из SearchPilot популяризировал использование A/B-тестов, которые фокусируются на показателях, связанных с трафиком веб-сайта, таких как клики. Этот подход хорошо работает для крупных компаний или компаний со значительным веб-трафиком».
Если вашему веб-сайту не хватает привилегии высокого уровня трафика, может потребоваться длительный период времени, чтобы трафик стал показателем результатов ваших исследований, что приведет к длительным процессам экспериментирования и тестирования.
Для компаний, стремящихся к расширению, особенно для компаний малого и среднего размера, их веб-страницы часто занимают позиции в результатах поисковых систем по ключевым словам с относительно низким объемом трафика, но еще не на первых позициях.
В течение вашего исследования каждый конкретный момент времени, например день, неделя или месяц, имеет тенденцию занимать несколько позиций в рейтинге по различным ключевым словам. Напротив, измерение трафика (которое обычно генерирует меньше точек данных на страницу за дату) может помочь вам быстрее достичь меньшего требуемого размера выборки.
Как опытный веб-мастер, я бы порекомендовал использовать отслеживание рейтингов компаниям среднего размера, стремящимся провести A/B-тестирование SEO. Благодаря такому подходу вы быстрее получите ценные результаты по сравнению с более крупными предприятиями.
Консоль поиска Google — ваш друг
Как эксперт по SEO, я бы рекомендовал использовать Google Search Console (GSC) для вашего проекта из-за его надежной функциональности API. С помощью этой функции вы можете легко получать огромные объемы исторических данных и применять фильтры на основе определенных строк URL-адресов.
Хотя данные могут и не соответствовать евангельской истине, они, по крайней мере, будут последовательными, и это достаточно хорошо.
Заполнение недостающих данных
Чтобы получить данные из Google Search Console (GSC) для всех нужных URL-адресов, даже для тех, у которых нет связанных страниц, вам потребуется создать дополнительные строки с заполнителями дат и заполнить пустые данные вручную.
В Python мы будем использовать набор функций слияния, которые можно рассматривать как аналогичные VLOOKUP в Excel, для добавления недостающих строк данных на основе URL-адреса. Кроме того, мы заполним необходимые данные для отсутствующих дат в URL-адресах.
Для показателей трафика это будет ноль, тогда как для позиций рейтинга это будет либо медиана (если вы предполагаете, что URL-адрес ранжировался, когда не было показов), либо 100 (если предположить, что он не ранжировался). ).
Код приведен здесь.
Проверьте дистрибутив и выберите модель
Размещение значений данных в любом распределении раскрывает его характер, в частности определяя, где находится наиболее часто встречающееся значение (режим) для определенного показателя, такого как ранговое положение, среди конкретной группы или выборки.
Как специалист по цифровому маркетингу, я бы объяснил это так: анализ распределения наших ранжированных данных позволит понять, насколько кластеризованы или разбросаны точки данных вокруг среднего значения (среднего или медианного). Проще говоря, это помогает нам понять степень разброса между различными ранговыми позициями в нашем наборе данных.
Это очень важно, поскольку это повлияет на выбор модели при оценке вашего теста по теории SEO.
Используя Python, это можно сделать как визуально, так и аналитически; визуально, выполнив этот код:
ab_dist_box_plt = (
ggplot(ab_expanded.loc[ab_expanded['position'].between(1, 90)],
aes(x = 'position')) +
geom_histogram(alpha = 0.9, bins = 30, fill = "#b5de2b") +
geom_vline(xintercept=ab_expanded['position'].median, color="red", alpha = 0.8, size=2) +
labs(y = '# Frequency \n', x = '\nGoogle Position') +
scale_y_continuous(labels=lambda x: ['{:,.0f}'.format(label) for label in x]) +
#coord_flip +
theme_light +
theme(legend_position = 'bottom',
axis_text_y =element_text(rotation=0, hjust=1, size = 12),
legend_title = element_blank
)
)
ab_dist_box_plt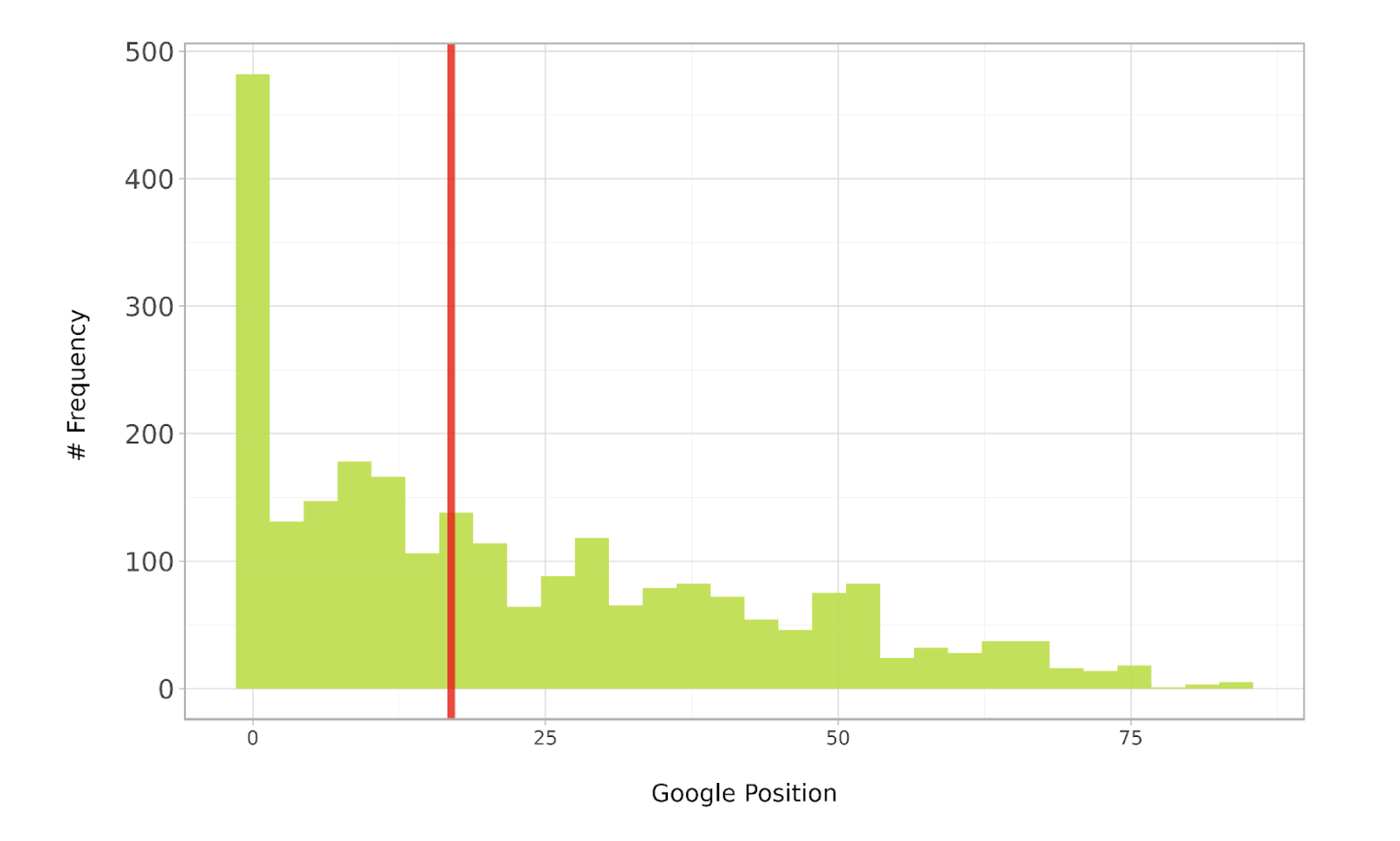 Image from author, July 2024
Image from author, July 2024Диаграмма иллюстрирует положительно асимметричное распределение, представленное стрелкой, указывающей вправо. Большинство ключевых слов занимают более высокие позиции в левой части красной срединной линии. Прежде чем выполнять этот код, убедитесь, что вы установили необходимые библиотеки с помощью команды: pip install pandasplotnine.
Как эксперт по SEO, я бы рекомендовал использовать соответствующий статистический тест, чтобы определить, имеет ли данная теория SEO обоснованность. В зависимости от распределения данных в нашем распоряжении доступны различные тесты. Например, если вы имеете дело с нормально распределенными данными, подходящим вариантом может быть t-критерий или ANOVA. Напротив, для ненормальных распределений альтернативные тесты, такие как критерий суммы рангов Уилкоксона или H-критерий Крускала-Уоллиса, могут дать ценную информацию. В конечном счете, выбор наиболее подходящей тестовой статистики имеет решающее значение для получения точных выводов из анализа данных SEO.
Минимальный размер выборки
Выбранную модель также можно использовать для определения минимально необходимого размера выборки.
Достаточное количество образцов в каждой группе необходимо для того, чтобы отличить истинные различия от простых случайных явлений.
Как эксперт по SEO, я могу с уверенностью заявить, что результаты моего недавнего исследования или гипотезы в области SEO продемонстрировали существенные различия, выходящие за рамки случайности. Другими словами, вероятность того, что наблюдаемая разница окажется простой случайностью, невелика. Эта статистическая значимость дополнительно подкрепляется высокой мощностью нашего теста, гарантируя, что наши результаты точно отражают реалии ситуации.
Мы можем добиться этого, создав различные модели случайного распределения, которые соответствуют заданному шаблону как для тестовой, так и для контрольной группы, а затем проведя моделирование с использованием этих моделей.
Код приведен здесь.
При запуске кода мы видим следующее:
(0.0, 0.05) 0
(9.667, 1.0) 10000
(17.0, 1.0) 20000
(23.0, 1.0) 30000
(28.333, 1.0) 40000
(38.0, 1.0) 50000
(39.333, 1.0) 60000
(41.667, 1.0) 70000
(54.333, 1.0) 80000
(51.333, 1.0) 90000
(59.667, 1.0) 100000
(63.0, 1.0) 110000
(68.333, 1.0) 120000
(72.333, 1.0) 130000
(76.333, 1.0) 140000
(79.667, 1.0) 150000
(81.667, 1.0) 160000
(82.667, 1.0) 170000
(85.333, 1.0) 180000
(91.0, 1.0) 190000
(88.667, 1.0) 200000
(90.0, 1.0) 210000
(90.0, 1.0) 220000
(92.0, 1.0) 230000Чтобы разобрать это, цифры представляют собой следующее, используя пример ниже:
Проще говоря, (39,333%) представляет собой процент испытаний или тестов, в которых получен статистически значимый результат. Эта цифра указывает как на вероятность достижения значимости, так и на устойчивость теста.
Как опытный веб-мастер с большим опытом анализа данных, я бы объяснил это следующим образом:
60000: размер выборки
Информация, представленная выше, интригует, но может поставить в тупик тех, кто не имеет опыта работы со статистикой. С одной стороны, это указывает на то, что нам потребуется примерно 230 000 точек данных (состоящих из ранжированных точек данных за определенный период времени) для достижения 92% вероятности наблюдения статистически значимых экспериментов по SEO. Однако, с другой стороны, утверждается, что мы можем достичь статистической значимости, имея только 10 000 точек данных. Итак, как нам действовать?
Как эксперт по SEO с обширным опытом анализа данных, я понял, что спешка с выводами на основе недостаточных данных может привести к неточным результатам. Поэтому рекомендуется стремиться к размеру выборки, охватывающему не менее 90% возможных сценариев. Следовательно, вам потребуется около 220 000 точек данных для обеспечения надежного и надежного анализа.
Основываясь на моем опыте обучения нескольких групп корпоративных SEO-специалистов, я обнаружил, что они постоянно выражали разочарование по поводу неубедительных результатов тестов при внедрении успешных модификаций тестов.
Назначьте и внедрите
Имея это в виду, теперь мы можем начать назначать URL-адреса между тестом и контролем, чтобы проверить нашу теорию SEO.
В программировании на Python вы можете использовать функцию np.where из библиотеки NumPy, которая работает аналогично расширенному оператору IF в Excel. Используя эту функцию, у вас есть возможность разделить темы на основе различных критериев, таких как шаблоны URL-адресов, типы контента, ключевые слова, встречающиеся в заголовках, или любые другие теории SEO, которые вы хотите изучить.
Используйте приведенный здесь код Python.
Чтобы собрать данные для дальнейшего развития вашей теории, необходимо провести новый эксперимент. Однако если нет других переменных, которые потенциально могли бы повлиять на гипотезу, вы можете изучить прошлые данные в качестве проверки своей теории. Такой подход называется ретроспективным анализом.
Об этом следует помнить, поскольку это всего лишь предположение!
Тест
Собрав все необходимые данные или убедившись, что у вас достаточно исторической информации, вы можете приступить к проведению теста.
Как профессионал в области цифрового маркетинга, я бы объяснил это так: при проверке наших позиций в рейтинге мы, вероятно, выберем статистический тест, такой как U-тест Манна-Уитни. Этот выбор обусловлен его уникальной способностью обрабатывать непараметрические распределения данных.
Если вы используете другой показатель, например клики, который соответствует распределению Пуассона, вам вообще потребуется альтернативная статистическая модель.
Код для запуска теста приведен здесь.
После запуска вы можете распечатать результаты теста:
Mann-Whitney U Test Test Results
MWU Statistic: 6870.0
P-Value: 0.013576443923420183
Additional Summary Statistics:
Test Group: n=122, mean=5.87, std=2.37
Control Group: n=3340, mean=22.58, std=20.59Как эксперт по SEO, я недавно провел эксперимент, чтобы изучить разницу между коммерческими целевыми страницами, подкрепленными внутренними руководствами блогов с межссылками, и теми, которые не были таковыми. Результаты указаны… (продолжение от первого лица)
В среднем разница в рейтинге Google между оффер-страницами с поддержкой контент-маркетинга и без нее существенная — примерно 11 позиций (от 5,87 до 22,58). Этот существенный разрыв наблюдался в 98% случаев.
Хотя нам требуются дополнительные 210 000 точек данных для усиления нашего набора данных, наши текущие результаты надежны и позволяют определить, что теория SEO воспроизводима менее чем в 10% случаев.
Сплит-тестирование может продемонстрировать навыки, знания и опыт
Как опытный веб-мастер, я разбирался в тонкостях оценки теорий SEO в различных статьях. Этот подход включает в себя как логические рассуждения, так и сбор необходимых данных для проведения надежного SEO-эксперимента.
Возможно, вы уже поняли, что нужно многое изучить и понять, когда дело доходит до проектирования, проведения и оценки экспериментов по SEO. Моя серия видеороликов «Наука о данных для SEO» углубляет эту тему (с дополнительным кодированием), предоставляя исчерпывающую информацию о научных аспектах SEO-тестов, включая разделенные A/A и разделенные A/B-тесты.
С точки зрения SEO, я не могу переоценить значение контент-маркетинга в повышении рейтинга в поисковых системах.
Клиенты часто проверяют наш опыт, поэтому крайне важно использовать методы A/B-тестирования в качестве доказательства вашего профессионализма в области SEO.
Смотрите также
- Анализ динамики цен на криптовалюту ENA: прогнозы ENA
- Анализ динамики цен на криптовалюту JUP: прогнозы JUP
- СЕО Рокстар «доказывает», что мета-описания не нужны
- Анализ динамики цен на криптовалюту FIL: прогнозы FIL
- Основные плагины WordPress, которые должен иметь каждый сайт.
- Анализ динамики цен на криптовалюту WLD: прогнозы WLD
- Объяснение Великого Отвязывания Высшему Руководству
- Анализ динамики цен на криптовалюту POL: прогнозы POL
- Режим Google AI может отвечать на языках, отличных от английского
- Что такое платный медиа: различные типы и примеры
2024-07-08 17:39