

Как digital-маркетолог, я тщательно изучил недавнее масштабное исследование OpenAI об использовании ChatGPT. Я проанализировал все данные и выделил ключевые выводы, которые наиболее важны для нас, чтобы вам не пришлось тратить часы на самостоятельное чтение. Я делюсь тем, что узнал, чтобы сэкономить ваше время и помочь нам всем более эффективно использовать ChatGPT.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)TL;DR
- LLM не заменяют поиск. Но они меняют то, как люди получают доступ к информации и потребляют её.
- Запросы, основанные на поиске информации (49%) и выполнении действий (40%), доминируют на рынке и постоянно улучшают свое качество.
- Три основных варианта использования – Практические рекомендации, Поиск информации и Написание – составляют 80% всех бесед.
- Издателям необходимо создавать линк-активы, которые добавляют ценность. Нельзя просто гнаться за трафиком из статей.

Чат-боты 101
Как цифровой маркетолог, я часто объясняю чат-ботов как, по сути, машины предсказаний. Они создаются с использованием огромного количества данных, чтобы научиться отвечать на то, что люди вводят – по сути, они учатся на примерах. Вы даете им вводные данные, и они предсказывают наиболее вероятный текстовый ответ. Это как если бы они имитировали то, что они ‘видели’ раньше.
Более сложные чат-боты обучаются в несколько этапов. Первый этап, часто называемый «предварительным обучением», включает в себя обучение чат-бота угадывать следующее слово в предложении.
Они настолько же надёжны, насколько и неинтересны, и это абсолютно нормально. Я предпочитаю, чтобы мои повара были снисходительны, пилоты — сосредоточены, а люди, управляющие моими финансами, были настолько консервативны, что могли бы легко стать экологическими активистами.
На втором этапе модели становятся более усовершенствованными. Во время ‘post-training’ они учатся давать высококачественные ответы на вопросы. Используются такие методы, как обучение с подкреплением, чтобы научить модель оценивать свои собственные ответы и улучшать их.
Подобно дрессировке собаки с помощью угощений и корректировок, большие языковые модели учатся, получая положительную обратную связь за хорошие ответы и отрицательную за плохие.
Изначально, модель создает базовое, внутреннее понимание информации. Затем, она уточняет это понимание для создания наиболее эффективного ответа.
Несколько слов о температуре.
Если вы не настроите параметр ‘temperature’, большая языковая модель будет выдавать абсолютно одинаковый результат каждый раз, когда ей дают один и тот же ввод и используют те же обучающие данные.
Когда установлено более высокое значение (около 1.0), модель становится более изобретательной и непредсказуемой. Более низкие значения (ближе к 0) заставляют её сосредоточиться на точности и давать более прямые, ожидаемые результаты.
Лучшая настройка температуры зависит от того, что вы делаете. Для кодирования используйте более низкую температуру, ближе к нулю. Для творческого письма или генерации контента лучше работает более высокая температура, ближе к единице.
Я обсуждал это ранее в своей статье о создании бренда после подъема ИИ. Однако я также настоятельно рекомендую ознакомиться с этим отличным руководством о шкалах температуры и о том, как они влияют на пользователей больших языковых моделей.
Что говорят нам данные?
Большие языковые модели не собираются заменять поисковые системы в ближайшее время, и, на мой взгляд, даже близко к этому. Недавнее исследование от Semrush на самом деле показало, что люди, которые используют LLM *больше*, также склонны к большему количеству традиционных поисков. Это подтверждает предположение о том, что LLM расширяют, а не заменяют, способы поиска информации людьми, скорее всего, верно.
Эти новые технологии кардинально изменили то, как мы находим и используем информацию. Разговорные интерфейсы особенно ценны, особенно в профессиональной среде.
1. Руководство, Поиск Информации и Написание Доминируют
Большинство бесед с роботами укладываются всего в три категории: выполнение задач, запрос информации и просьба о помощи в написании текста – что часто приводит к невыразительному и лишенному креативности результату.
Признаю, большинство запросов, которые я получаю, связаны с полировкой уже написанного текста. Однако, если я обнаружу, что текст был создан ИИ, я почувствую себя обманутым, и я не ценю обман.
2. Использование не связанное с работой растет.
- Нерабочие сообщения выросли с 53% от общего объема использования до более 70% к июлю 2025 года.
- LLMs стали привычными. Особенно когда дело касается помощи нам в принятии правильных решений. Как на работе, так и вне её.
3. Письмо — самое распространённое применение на рабочем месте.
- Написание является наиболее распространенным вариантом использования в работе, составляя в среднем 40% рабочих сообщений в июне 2025 года.
- Примерно две трети всех сообщений, создаваемых при письме являются запросами на изменение существующего текста пользователя, а не на создание нового текста с нуля.
Я знаю многих людей, которые используют инструменты искусственного интеллекта, такие как LLMs, для улучшения написания электронных писем. Немного разочаровывает видеть, что основной способ использования этих инструментов не связан ни с чем особенно воображаемым или инновационным, и мне почти жаль энтузиастов технологий, которые их создали.
4. Меньше кодирования
- Запросы по компьютерному кодированию составляют относительно небольшую долю, всего 4,2% от всех сообщений.
- Это кажется очень контринтуитивным, но специализированные боты, такие как Claude, или инструменты, такие как Lovable, являются лучшими альтернативами.
- Это важный момент. Специализированное использование LLM будет расти и, вероятно, доминировать в определенных отраслях, поскольку они смогут разрабатывать более качественные результаты. Специализированное обучение стилю на втором этапе создает гораздо более превосходный продукт.
Стоит помнить, что исследования показывают, что люди используют большие языковые модели различными способами, поэтому картина не так проста, как кажется. И, по мере развития технологии, мы можем ожидать, что эти способы использования будут продолжать меняться.
5. Мужчины больше не доминируют
- Ранние последователи были непропорционально мужского пола (около 80% с типично мужскими именами).
- Это число снизилось до 48% к июню 2025 года, при этом активные пользователи теперь немного чаще имеют типично женские имена.
Да, мужчины, конечно, не идеальны. Исторически мы часто были слишком охочи до борьбы и склонны брать на себя инициативу. Приятно видеть, что сейчас ситуация становится более сбалансированной.
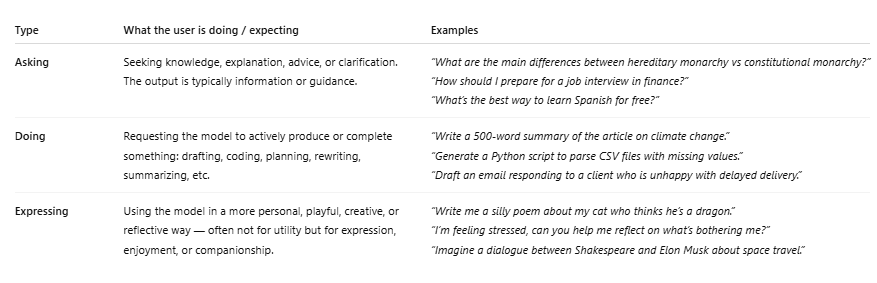
6. Запросы и выполнение доминируют.
- 89% всех запросов связаны с вопросами и действиями.
- 49% Спрашивают и 40% Действуют, всего лишь 11% для Выражения.
- Сообщения с запросами росли быстрее, чем сообщения о действиях, за последний год, и оцениваются как более качественные.
7. Отношения и личные размышления не являются заметными.
- Существует ряд исследований, утверждающих, что LLM стали личными терапевтами для людей (см. выше).
- Однако, отношения и личные размышления составляют лишь 1,9% от общего количества сообщений, согласно OpenAI.
8. Кровавая Молодежь (*Shakes Fist*)
- Почти половина всех сообщений, отправленных взрослыми, была от пользователей младше 26 лет.
- Это совпадает с исследованиями Кевина Индига о том, как различные демографические типы потребляют AI Overviews. Молодые люди a) более склонны доверять ему и b) более склонны внедрять его.
Основные выводы
Я не думаю, что большие языковые модели разрушат издательское дело. Это правда, что они не привлекают трафик на наши сайты и теперь требуют подписки для отображения источников — что раздражает. Но мы не должны ожидать подачек от технологических компаний в любом случае.
Это гонка на Луну, и мы – собака, которую они отправили на тестовый полёт.
Если вы издатель, который сформировал свой голос, лояльную аудиторию и некоторую узнаваемость бренда, вы должны быть в состоянии адаптироваться. Однако, сканирование поисковыми системами становится все более агрессивным.

Ключевой вывод для издателей из этих данных — изменение того, чего пытаются достичь пользователи. Традиционно мы классифицировали эти цели как навигационные (поиск конкретного сайта), информационные (получение знаний), коммерческие (изучение продуктов) и транзакционные (совершение покупки).
Теперь у нас есть Doing. Или Generating. И это огромно.
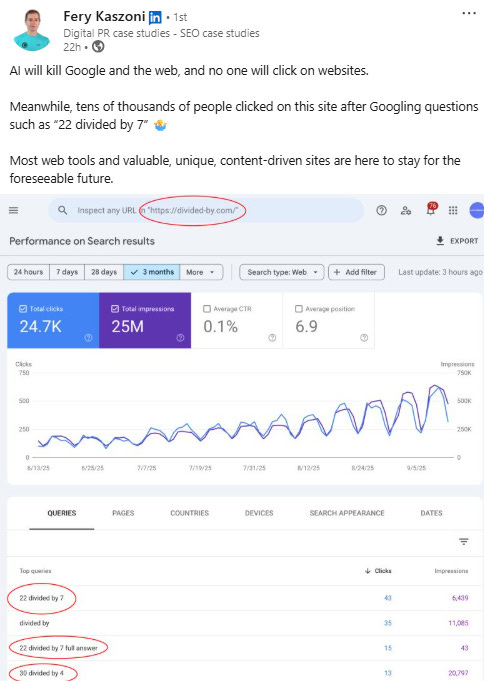
SEO по-прежнему ценно для издателей, но простого создания контента уже недостаточно. Разумно изучить преимущества ИИ, но также важно сохранять контроль и не полагаться на него полностью.
Как SEO-эксперт, я всегда думаю о том, что действительно выделяет контент. Для меня это создание вещей, подобных BBC Verify — контента, который действительно ценен и не может быть легко воспроизведён ИИ. Это означает сосредоточение внимания на глубоких репортажах, полезных инструментах и ресурсах для обмена. Самое главное — это заметное представление подлинных идей и мнений реальных экспертов — это то, что укрепляет доверие и авторитет в Интернете.
Поддержание высокого качества в масштабе – это сложная задача. Программный SEO и полезные инструменты могут принести значительные преимущества, особенно когда они последовательно отвечают на то, *что* пользователи пытаются сделать. Чтобы действительно выделиться, нам нужно создавать ресурсы, которые предлагают ценность, превосходящую уже доступную.
Как цифровой маркетолог, я обнаружил, что если вы ориентируетесь на более молодую аудиторию — или на ту, которая склонна быть более доверчивой — вам действительно нужно подчеркивать подлинность и строить эту связь. Речь идет о том, чтобы встретить их там, где они есть, и говорить на их языке.
Смотрите также
- Анализ динамики цен на криптовалюту ETH: прогнозы эфириума
- Акции RNFT. РуссНефть: прогноз акций.
- Акции NLMK. НЛМК: прогноз акций.
- Какой самый низкий курс евро к южноафриканскому рэнду?
2025-10-01 18:41