

Этот анализ основан на недавней утечке данных Google и соответствует тому, что я наблюдал в отношении контента, который стабильно хорошо работает в Discover. Я выявил ключевые факторы, которые, по-видимому, использует Google для ранжирования в Discover, и организовал их в логичный рабочий процесс.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Как уволенный сотрудник BBC, мои мысли принадлежат только мне.
TL;DR
- Discover работает на основе шестиэтапного конвейера, использующего хорошие и плохие клики (длительное время пребывания на странице против быстрого возврата) и повторные посещения для непрерывной оценки и переоценки качества контента.
- Свежий контент получает первоначальный импульс. Успех зависит от сильного CTR и положительного начального вовлечения (хорошие клики/репосты со всех каналов важны, а не только Discover).
- Контент, соответствующий интересам пользователя, имеет приоритет. Для оптимизации сосредоточьтесь на ваших областях тематического авторитета, используйте привлекательные заголовки, будьте ориентированы на сущности и используйте большие изображения (1200px+).

Я выявил 15 различных источников, которые Google использует для наполнения ленты Discover увлекательным контентом для пользователей, бесконечно прокручивающих её. Эта система не сильно отличается от того, как работает обычный поиск Google.
Традиционный поиск и Discover сильно отличаются. Люди используют традиционный поиск, когда у них есть конкретная потребность, но просматривают Discover, когда им скучно – например, по дороге на работу, в гостях у семьи или просто во время перерыва. Поскольку оба являются частью одной компании, к ним часто относятся как к единому целому, что не идеально.
И вот как это работает.
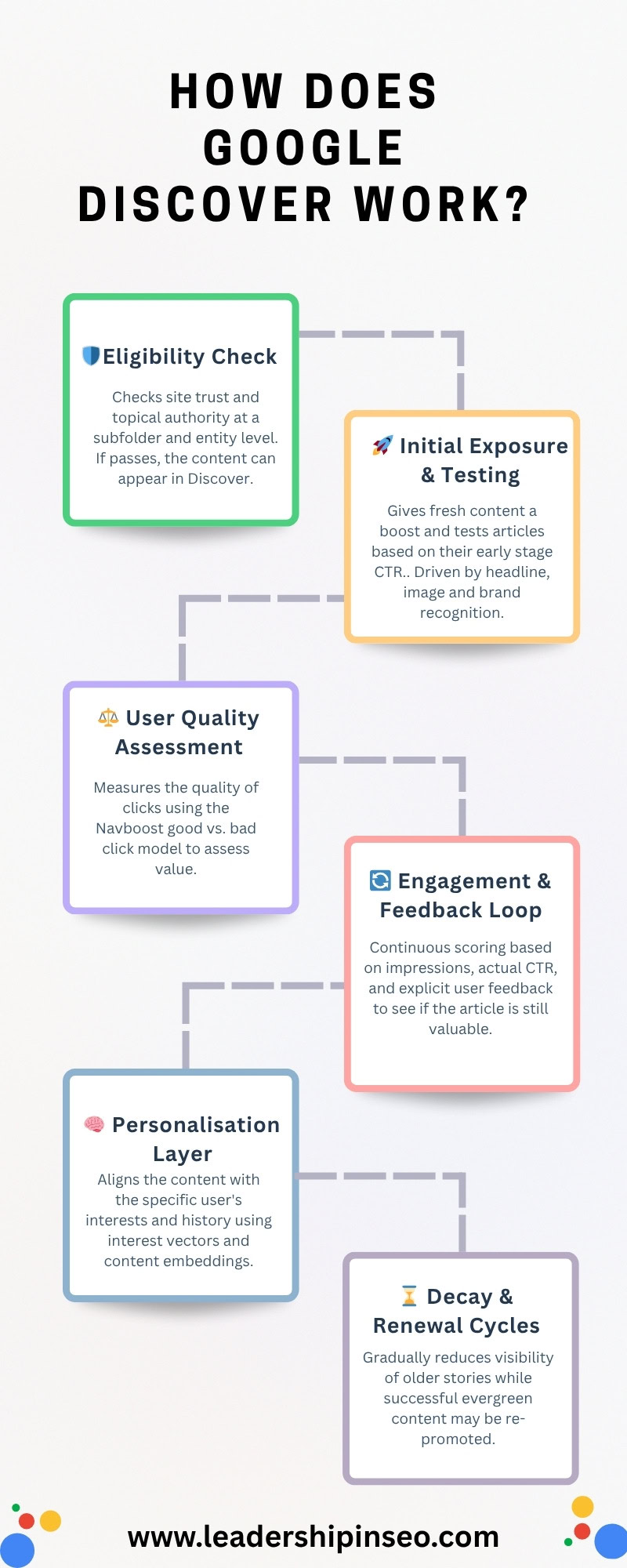
Руководство Google Discover
Discover использует схожие методы с Search для выявления контента, который полезен, заслуживает доверия и ориентирован на потребности людей.
Но мы можем сделать это лучше.
Контент-пайплайн Discover из шести частей
Давайте разберем, как ваш контент появляется в Discover от начала до конца – или, чаще, почему он этого не делает. Просто напоминаю, что группировки, которые я использую, созданы для этого объяснения, но они основаны на реальных данных Google из предыдущей утечки.
- Проверка соответствия и базовая фильтрация.
- Первоначальное ознакомление и тестирование.
- Оценка качества пользователей.
- Вовлечение и цикл обратной связи.
- Персонализированный слой.
- Циклы упадка и возрождения.
Критерии соответствия и базовая фильтрация
Существует три основных прокси-оценки для учета соответствия и базовой фильтрации:
- is_discover_feed_eligible: булева функция, которая фильтрует не подходящие страницы.
- publisher_trustScore: оценка, которая оценивает надёжность и репутацию издателя.
Как вебмастер, я узнал, что Google использует несколько ключевых факторов, чтобы решить, заслуживает ли мой сайт места в Discover. Они оценивают, насколько уважаем мой сайт в целом, насколько он демонстрирует экспертность по конкретной теме и насколько он релевантен тому, что ищут люди. По сути, эти факторы помогают Google определить, достоверен ли мой контент и стоит ли показывать его пользователям в Discover.
Первоначальное воздействие и тестирование
Как SEO-эксперт, я часто говорю о ‘факторе свежести’. По сути, Google временно повышает позиции нового контента, потому что люди естественным образом тяготеют к тому, что актуально. Представьте себе это так: мы все немного ‘управляем дофамином’, и свежая информация даёт нам ту небольшую дозу новизны, которой мы жаждем. Это краткосрочный импульс, но он реален, и именно поэтому постоянное создание нового контента так важно.
- freshnessBoost_discover: предоставляет временный импульс для свежего контента, чтобы поддерживать активность ленты.
- discover_clicks: где клики по статьям на ранней стадии используются в качестве предсказателя популярности.
- headlineClickModel_discover: является прогностической моделью CTR, основанной на заголовке и изображении.
Google, вероятно, использует прогностическую модель, аналогичную байесовской статистике, для оценки вероятности того, что люди кликнут на ваш контент (CTR). Чем больше высококачественного контента вы последовательно публикуете – на вашем веб-сайте, в конкретных разделах и отдельными авторами – тем выше ваши шансы занять более высокие позиции в результатах поиска.
Потому что меньше двусмысленности. Ключевая особенность SEO на данный момент.
Оценка качества пользователей
В конечном счете, то, как люди взаимодействуют со статьей, определяет ее успех. Google оценивает это, анализируя, как пользователи кликают и используют контент, используя систему под названием Navboost. Если у статьи низкий коэффициент кликабельности или пользователи быстро возвращаются к результатам поиска после клика (известное как ‘pogo-sticking’), то она с меньшей вероятностью будет ранжироваться высоко.
Мы определяем, насколько хорош контент, оценивая, как часто люди на него нажимают. Чтобы понять, действительно ли людям нравится контент с течением времени, мы отслеживаем повторные посещения и используем эту информацию для выделения наших наиболее эффективных материалов.
- discover_blacklist_score: Штраф за спам, дезинформацию или кликбейт.
- goodClicks_discover: Позитивные взаимодействия пользователей (длительное время пребывания на странице).
- badClicks_discover: Негативные взаимодействия (отказы, короткое время пребывания).
- nav_boosted_discover_clicks: Метрика повторного или возвратного вовлечения.
Мы определяем, насколько хороша статья, оценивая взаимодействие с ней пользователей. Поскольку Discover подстраивает контент под каждого пользователя, мы можем эффективно измерять это для большого числа людей. Мы группируем пользователей со схожими интересами и показываем им статьи, которые, по мнению системы, им понравятся.
Если сенсационное или вводящее в заблуждение название не удерживает людей от чтения (что означает низкое время пребывания на странице и малое количество взаимодействий), статья может занять более низкое место в результатах поиска. Повторное использование этих тактик в конечном итоге может нанести вред общей производительности вашего веб-сайта.

Важно понимать, что данные о кликах, используемые системой, не ограничиваются статьями, найденными через Discover. Chrome отслеживает клики по любой опубликованной статье – будь то статья, которой поделились в социальных сетях, или статья, найденная где-либо в интернете – и использует эти данные для улучшения своего алгоритма.
Чтобы добиться успеха в Discover, сосредоточьтесь на получении большого количества ранних кликов и репостов – свежий контент – это ключ к успеху! Думайте об этом как о платформе, где всё становится вирусным, поэтому не бойтесь продвигать свою работу и распространять информацию.
Вовлечение и цикл обратной связи
Как только статья опубликована, начинается процесс постоянной оценки. Данные, такие как коэффициенты кликабельности, просмотры и прямые отзывы пользователей (например, лайки, дизлайки и опции для скрытия контента), используются такими системами, как Navboost, для улучшения того, что видят люди.
- discover_impressions: Количество показов статьи в ленте Discover.
- discover_ctr: Клик-рейт (CTR) — это отношение количества кликов к количеству показов. Данные о показах и кликах используются для моделирования CTR.
- discover_feedback_negative: Конкретные отзывы пользователей, например, «не интересует», подавляют контент для отдельных лиц, групп и на платформе в целом.
Насколько хорошо статья работает, зависит от того, как люди с ней взаимодействуют. Она преуспевает или терпит неудачу на основе простых показателей, таких как клики и вовлечённость. Кроме того, чем больше людей используют платформу, тем умнее она становится в предсказании того, что вы и другие сочтёте интересным и приятным.

Система, вероятно, хранит информацию о заголовках и изображениях, чтобы анализировать, что работает лучше всего. Понимая, какие заголовки, изображения и статьи привлекают разные группы людей, она может быстро адаптировать контент для каждого конкретного пользователя, делая персонализацию более эффективной.
Персонализированный слой
Google собирает значительный объём личной информации – такие вещи, как номера кредитных карт, пароли и контактные данные – как основную часть своей работы. Этот сбор данных распространяется практически на всё, что вы делаете в интернете, отслеживая вашу активность на веб-страницах.
Как SEO-эксперт, я очень заинтригован Discover. Это кажется взглядом в будущее результатов поиска – высоко персонализированной лентой статей, видео и социального контента. Представьте себе этот адаптированный кластер, появляющийся прямо в SERP, возможно, даже вместе с такими функциями, как AI Mode, разработанными для удержания пользователей. Это мощный способ привлечь внимание и может значительно изменить наше представление о поиске.
Цель всего этого — побудить вас проводить больше времени на веб-сайтах и в сервисах Google, поскольку именно так они получают больше дохода.
- contentEmbeddings_discover: Встраивания контента определяют, насколько хорошо контент соответствует интересам пользователя. Это обеспечивает работу механизма сопоставления интересов Discover.
- personalization_vector_match: Этот модуль динамически персонализирует ленту пользователя в режиме реального времени. Он определяет сходство между векторами контента и интересов пользователя.
Контент, который хорошо соответствует вашим личным и групповым интересам, будет продвигаться в вашей ленте.
Chrome отслеживает веб-сайты, которые вы часто посещаете, через страницу Site Engagement (вы можете найти её, набрав chrome://site-engagement/ в вашем браузере). Эта страница и связанные с ней данные, отображаемые в виде графиков, показывают, как вы взаимодействуете с веб-сайтами, измеряя, насколько быстро и плавно браузер реагирует на ваши действия на этих страницах.
Журналы не показывают напрямую *что* пользователь кликнул или прокрутил, но они фиксируют *как долго* браузеру потребовалось для обработки действия.
Циклы упадка и обновления
Как цифровой маркетолог, я обнаружил, что последовательная публикация свежего контента является ключевым моментом. Люди жаждут новой информации, и она естественным образом отодвигает более старые истории на второй план. Когда мы продвигаем новые материалы, старый контент неизбежно уходит в прошлое по мере развития новостного цикла и снижения вовлеченности – так это работает в интернете.
Для успешных историй это достигается за счет насыщения рынка.
- freshnessDecay_timer: Этот модуль измеряет снижение актуальности после первоначального воздействия, постепенно снижая видимость, чтобы освободить место для более свежего контента.
- content_staleness_penalty: Устаревший контент или темы получают более низкий приоритет, как только вовлечение начинает снижаться, чтобы поддерживать актуальность ленты.
Discover – это попытка Google создать социальную платформу, но давайте будем честны, большинство людей там не тусуются. Она просто не очень увлекательна. И это преднамеренно – она не создана, чтобы вызывать привыкание или постоянно привлекать ваше внимание, как другие социальные сети.
Google Discover определённо движется в этом направлении – становясь центральным хабом для информации. Именно поэтому они вносили последние обновления, чтобы помочь вам оставаться в курсе событий о создателях и издателях, на которых вы подписаны, даже на разных веб-сайтах и в приложениях.
Мы видим, как ИИ создаёт краткие обзоры для всевозможного контента – видео, публикаций в социальных сетях, статей, всего на свете. Честно говоря, я хотел бы, чтобы они прекратили это делать.
Мой 11-шаговый рабочий процесс, чтобы получить максимум пользы от Google Discover
Соблюдение нескольких простых рекомендаций обеспечит вам успех. Определите, что ваш веб-сайт уже делает хорошо, а затем сосредоточьтесь на создании контента, который предоставляет реальную ценность вашей аудитории. Существует множество различных подходов, которые вы можете использовать для достижения этой цели.
Если ваш контент нечасто появляется в Discover, вы можете найти возможности, изучив данные из Search Console. В частности, определите темы, по которым вы получаете больше всего кликов и показов – это области, в которых вы зарекомендовали себя как авторитет. Я рекомендую анализировать эти данные на детальном уровне, сосредотачиваясь на конкретных подтемах и сущностях – например, изучите ‘политику’, а затем углубитесь в такие фигуры, как ‘Rachel Reeves’, или партии, как ‘the Labor Party’.
Также полезно анализировать эти данные как в целом, так и для каждой отдельной статьи. В качестве альтернативы, инструменты, такие как отчет Traffic Share от Ahrefs, могут оценить вашу долю голоса, используя внешние данные.
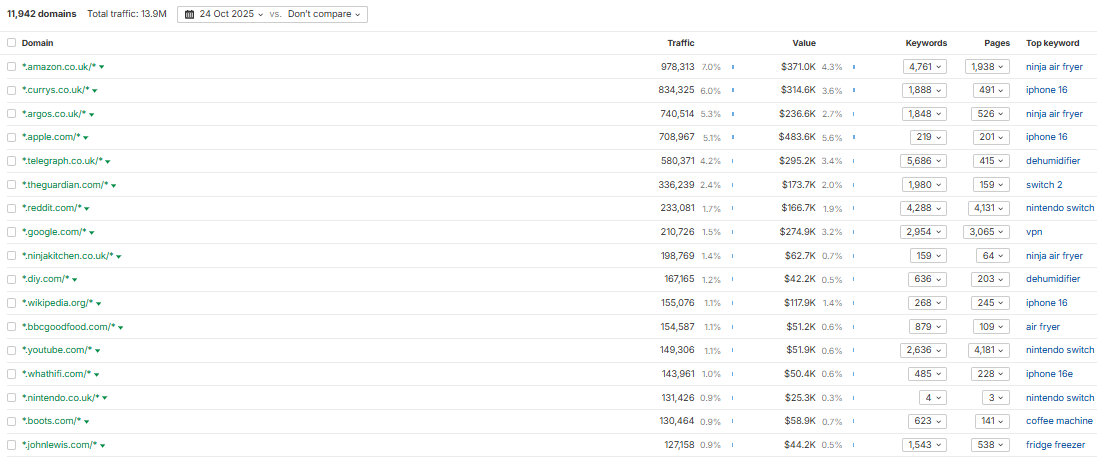
Сосредоточьте свои усилия на двух ключевых вещах: во-первых, на темах, которые вы уже хорошо знаете, а во-вторых, на предметах, которые действительно принесут пользу вашей аудитории.
Предполагая, что вы не сосредотачиваетесь на контенте NSFW и вы хотя бы примерно подходите, вот что бы я сделал:
- Убедитесь, что вы соблюдаете базовые требования к изображениям. Минимальная ширина — 1200 пикселей.
- Определите свои области тематического авторитета. Где вы уже эффективно ранжируетесь на уровне подпапки? Есть ли конкретный автор, который показывает лучшие результаты? Постарайтесь развивать ваши ценные контент-хабы контентом, который должен принести дополнительную ценность в этой области.
- Инвестируйте в контент, который принесет реальную ценность (ссылки и вовлечение) в этих областях. Не гонитесь за кликами через Discover. Это билет в один конец в город кликбейта.
- Убедитесь, что вы в курсе новостей. Быть первым оказывает огромное влияние на видимость ваших новостей в поиске. Если вы не первые на месте, убедитесь, что вы добавляете что-то дополнительное к обсуждению. Будьте смелыми. Добавляйте ценность. Понимайте, как на самом деле работает новостной SEO.
- Будьте ориентированы на сущность. В ваших заголовках, первом абзаце, подзаголовках, структурированных данных и альтернативном тексте изображений. Ваша страница должна устранять неоднозначность. Вам необходимо предельно ясно дать понять, о ком или о чем эта страница. Недостаток ясности — одна из причин, по которой Google переписывает заголовки.
- Используйте заголовок Open Graph. Заголовок OG — это заголовок, который не отображается на вашей странице. В первую очередь предназначенный для использования в социальных сетях, это один из наиболее часто выбираемых заголовков в Discover. Он может быть ярким. Вызывающим любопытство. Богатым. Интересным. Но все же ориентированным на сущность.
- Убедитесь, что вы публикуете контент, который, вероятно, хорошо покажет себя в Discover через соответствующие каналы push на ранних этапах его жизненного цикла. Ему необходимо превзойти свои прогнозируемые показатели на ранней стадии.*
- Создайте хороший пользовательский опыт. Ваша страница (и сайт) должны быть быстрыми, безопасными, с минимальным количеством рекламы и запоминающимися по правильным причинам.
- Постарайтесь продвигать качественные путешествия. Если вы можете по-разному относиться к пользователям из Discover по сравнению с вашим основным сайтом, подумайте о том, как эффективно установить связь для них. Возможно, вы используете всплывающее окно «мы думаем, вам понравится это следующее» раздел, основанный на глубине прокрутки или времени пребывания пользователя.
- Привлекайте трафик для конверсий. Хотя Discover — это персонализированная лента, стандартный скроллер не очень вовлечён. Поэтому сосредоточьтесь на более простых конверсиях, таких как регистрации (если вы компания, работающая по подписке в первую очередь) или рекламные доходы и т. д.
- Веди учёт своих лучших исполнителей. Вечнозелёный контент можно обновлять и перепубликовать из года в год. Он всё ещё может приносить пользу.
Смотрите также
- Акции PHOR. ФосАгро: прогноз акций.
- Google Merchant Center теперь позволяет вам выбирать способы оплаты
- Акции ROLO. Русолово: прогноз акций.
- WP Engine против Automattic: судья склонен вынести предварительный судебный запрет
- Акции MRKV. МРСК Волги: прогноз акций.
- Биткойна «Время взрыва» – Видение Сатоши подрывается?
- Изображения Google Ads с искусственным интеллектом Теперь могут создавать людей и лица
- Важные функции поисковой выдачи торговой площадки Google
- Новые Playbooks Google Business Profile с советами по локальной оптимизации.
- Акции OBNE. Обьнефтегазгеология: прогноз акций.
2025-10-29 15:16