

Чат-боты с искусственным интеллектом, такие как ChatGPT, Perplexity и Google AI Mode, не создают оригинальный контент, когда отвечают на вопросы. Вместо этого они находят информацию на веб-сайтах, сокращают ее и собирают по-новому. Это означает, что если ваш веб-сайт не оптимизирован для поисковых систем, он не будет отображаться в этих результатах поиска на основе искусственного интеллекта. По сути, поиск теперь управляется искусственным интеллектом.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Иногда веб-сайты сложно понять компьютерам. Здесь помогает структурированные данные – дело не только в улучшении позиций в поисковых системах, но и в предоставлении чёткой структуры для того, чтобы ИИ точно идентифицировал ключевую информацию. По этому поводу было некоторое обсуждение, и в этой статье я объясню:
- проведение контролируемых экспериментов на 97 веб-страницах, демонстрирующих, как структурированные данные улучшают согласованность сниппетов и контекстную релевантность.
- отобразите эти результаты в нашей семантической структуре.
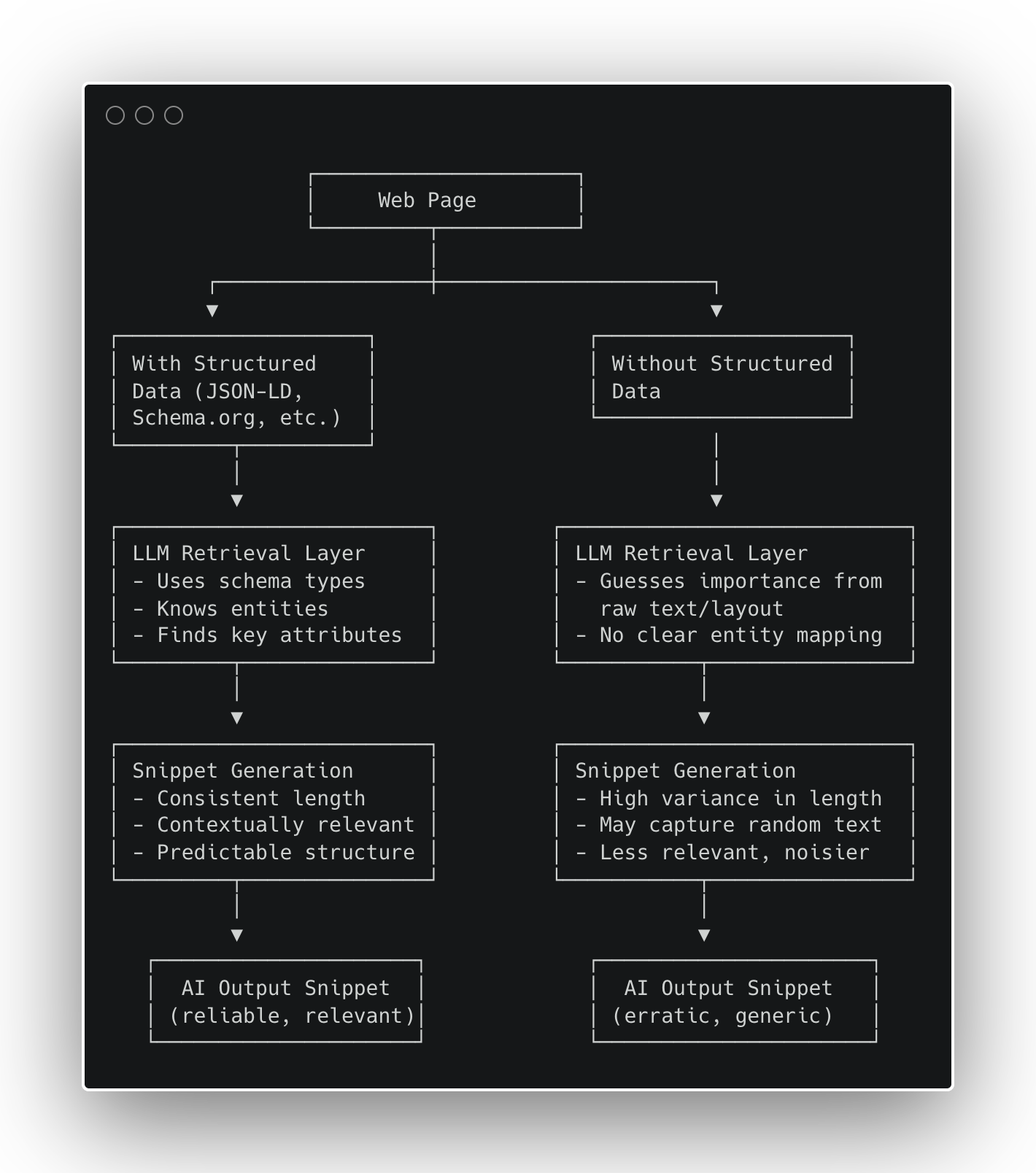
В последнее время я получаю много вопросов о том, работают ли большие языковые модели (LLM) с организованными данными. Мой ответ последователен: LLM сами напрямую не используют структурированные данные, поскольку они не могут напрямую получать доступ к интернету. Вместо этого они полагаются на инструменты для поиска в интернете и извлечения информации с веб-сайтов. Эти инструменты часто работают намного лучше, когда *могут* получать доступ и использовать структурированные данные.

Наши первоначальные тесты показывают, что использование структурированных данных делает ответы GPT-5 более последовательными и релевантными. Это также говорит о том, что мы можем получать более длинные ответы от ИИ – представьте это как увеличение объема контента, который учитывает GPT-5. Лучший, более подробный контент, похоже, расширяет этот предел, повышая видимость вашей информации. Я впервые обсудил эту идею в посте в LinkedIn, если вы хотите узнать больше.
Почему это важно сейчас
- Ограничения Wordlim: AI-стеки работают с жесткими бюджетами токенов/символов. Неопределенность тратит бюджет; типизированные факты экономят его.
- Разграничение и привязка: Schema.org сужает область поиска модели («это Рецепт/Продукт/Статья»), делая выбор более безопасным.
- Графы знаний (KG): Схемы часто используются для наполнения графов знаний, к которым системы искусственного интеллекта обращаются при поиске фактов. Это мост от веб-страниц к логическому мышлению агента.
Я считаю, что мы должны рассматривать структурированные данные как способ направлять ИИ. Вместо простого предоставления результатов, это гарантирует, что ИИ последовательно предоставляет точную информацию об отдельных лицах.
Дизайн экспериментов (97 URL)
Мне было интересно, как ChatGPT извлекает информацию непосредственно в своем интерфейсе чата, а не через программный интерфейс (API). Даже несмотря на то, что мой тест включал ограниченное количество поисков, я попросил его найти и получить доступ к нескольким веб-страницам с различных сайтов, а затем показать мне исходный контент, который он нашел.
Возможно попросить GPT-5 (или другой ИИ) напрямую отображать необработанные данные из его внутренних инструментов с помощью простого запроса. Затем я собрал результаты поиска и контент, извлечённый для каждой веб-страницы, и использовал WordLift (наш SEO-инструмент на базе ИИ) для их анализа. Этот анализ проверил наличие структурированных данных на каждой странице и определил типы представленных схем.
Эти два шага привели к созданию набора данных из 97 URL-адресов, аннотированных ключевыми полями:
- has_sd → Флаг True/False, указывающий на наличие структурированных данных.
- schema_classes → обнаруженный тип (например, Recipe, Product, Article).
- search_raw → фрагмент «search-style«, представляющий то, что показал инструмент поиска с использованием ИИ.
- open_raw → сводка извлекателя или структурный обзор страницы от GPT-5.
Затем я использовал Gemini 2.5 Pro для работы в качестве автоматизированного оценщика, анализируя данные и выявляя три ключевых измерения.
- Согласованность: распределение длин необработанных сниппетов поиска (ящик с усами).
- Контекстная релевантность: покрытие ключевых слов и полей в open_raw по типу страницы (Recipe, E-comm, Article).
- Оценка качества: консервативный индекс 0–1, объединяющий присутствие ключевых слов, базовые подсказки NER (для электронной коммерции) и эхо-сигналы схемы в результатах поиска.
Скрытая квота: Разбираем «wordlim»
Во время тестирования я обнаружил интересную деталь, которая может объяснить, почему использование структурированных данных приводит к более качественным и полным ответам. У GPT-5 есть внутренний лимит, называемый ‘wordlim’, который контролирует, сколько текста с одной веб-страницы может быть включено в его ответы. Этот лимит динамически изменяется.
Похоже на ограничение по количеству слов, но на самом деле оно подстраивается автоматически. Страницы с высококачественным, хорошо структурированным контентом получают больше места в системе для обработки.
Из моих продолжающихся наблюдений:
- Неструктурированный контент (например, стандартная запись в блоге) обычно содержит около ~200 слов.
- Структурированный контент (например, разметка продуктов, каналы) расширяется примерно до ~500 слов.
Это не произвольное ограничение. Лимит помогает AI-системам:
- Избегайте проблем с авторским правом.
- Поддерживайте ответы краткими и читаемыми.
Структурированные данные становятся все более важными для SEO. По сути, они расширяют возможности видимости вашего веб-сайта в результатах поиска. Без них ваш охват ограничен. С ними вы помогаете поисковым системам лучше понимать ваш контент, повышая доверие и вероятность того, что ваш бренд будет представлен на видном месте.
Хотя набор данных все еще растет и не достиг размера, который гарантирует окончательные результаты во всех областях, мы уже видим четкие тенденции, которые мы можем применить на практике.
Результаты
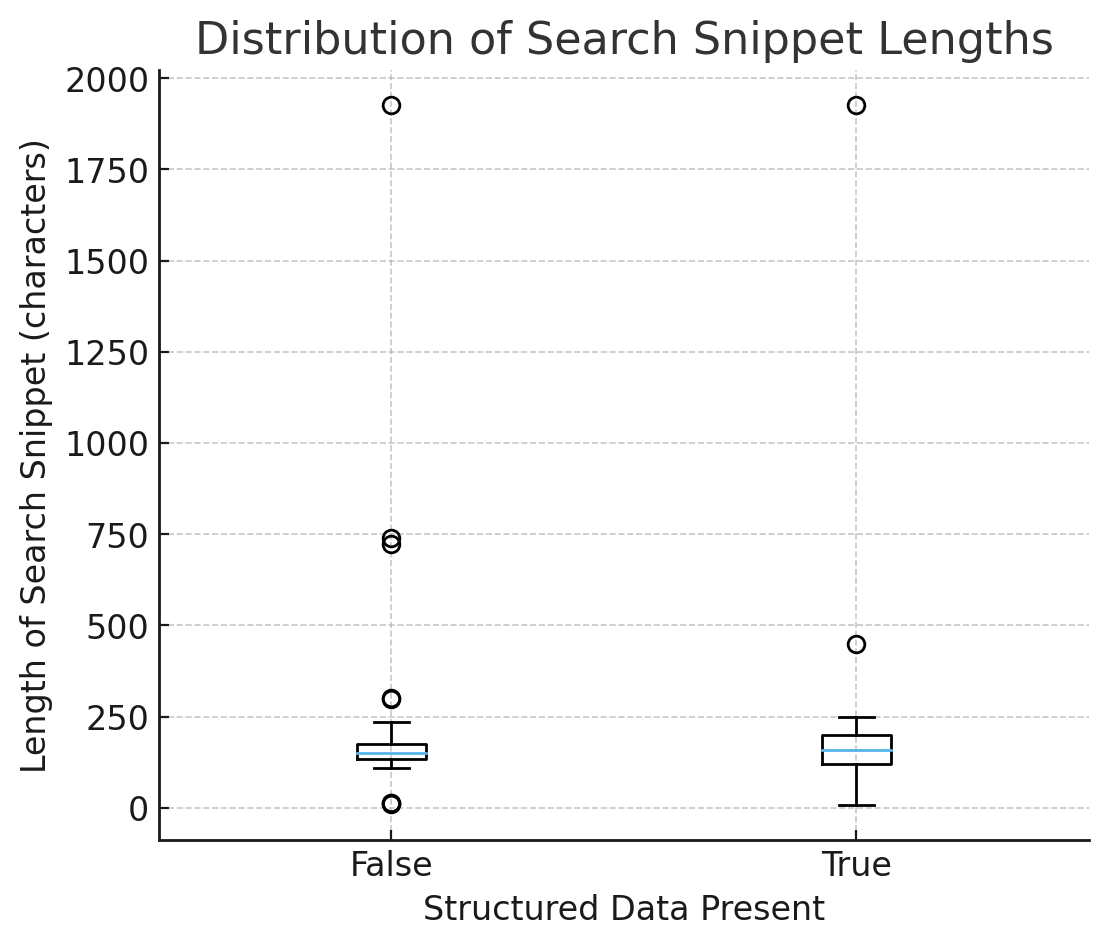
1) Консистентность: Сниппеты более предсказуемы со схемой.
На ящиковой диаграмме длин фрагментов поиска (с и без структурированных данных):
- Медианы похожи → схема не делает сниппеты длиннее/короче в среднем.
- Разброс (IQR и усы) более узкий, когда has_sd = True → менее хаотичный вывод, более предсказуемые сводки.
Использование структурированных данных не делает контент длиннее – оно на самом деле делает его более понятным и надёжным. Вместо того, чтобы пытаться понять что-либо из беспорядочного кода веб-сайта, системы могут полагаться на точную, предварительно определённую информацию.
2) Контекстуальная релевантность: Извлечение руководств по схемам
- Рецепты: С использованием схемы рецептов сводки гораздо чаще включают ингредиенты и шаги. Четкий, измеримый прирост.
- Электронная коммерция: Инструмент поиска часто повторяет поля JSON‑LD (например, aggregateRating, offer, brand), что свидетельствует о том, что схема читается и отображается. Полученные сводки склоняются к точным названиям продуктов, а не к общим терминам, таким как «цена», но привязка к идентификатору сильнее при использовании схемы.
- Статьи: Небольшие, но заметные успехи (автор/дата/заголовок с большей вероятностью появятся).
3) Оценка качества (Все страницы)
Усреднение оценки от 0 до 1 по всем страницам:
- Нет схемы → ~0.00
- Со схемой → позитивный рост, обусловленный в основном рецептами и некоторыми статьями.
Даже когда различные подходы кажутся похожими, предсказуемость является ключевым фактором. В мире ИИ, где скорость обработки и доступ к данным ограничены, последовательность дает вам преимущество.
За пределами согласованности: более богатые данные расширяют возможности Wordlim (Ранний сигнал)
Хотя наш набор данных все еще растет, мы заметили тенденцию: веб-страницы с подробной, организованной информацией, похоже, генерируют немного более длинные и информативные сниппеты до того, как они будут сокращены.
Мы считаем, что чётко структурированные данные (например, связывание продукта с его предложением, брендом и рейтингами, или статьи с её автором и датой публикации) помогают моделям ИИ сосредоточиться на самой важной информации и более эффективно использовать свои вычислительные мощности – по сути, позволяя им обрабатывать больше контента. Веб-сайты без этих структурированных данных часто обрываются преждевременно, вероятно, потому, что ИИ испытывает трудности с определением того, что является наиболее важным.
Далее мы исследуем, как количество подробной информации из структурированных данных (в частности, количество уникальных деталей, которые они предоставляют) связано с идеальной длиной предварительных просмотров поисковых сниппетов. Если наша гипотеза верна, использование структурированных данных не только обеспечит согласованность длины сниппетов, но и позволит им передавать больше информации в фиксированном количестве слов.
От Схемы к Стратегии: Игровой План
Мы структурируем сайты как:
- Граф сущностей (Схема/GS1/Статьи/…): продукты, предложения, категории, совместимость, местоположения, политики;
- Лексический граф: фрагментированное копирование (инструкции по уходу, таблицы размеров, часто задаваемые вопросы), связанные обратно к сущностям.
Эта система работает, потому что базовый слой обеспечивает работу ИИ в безопасных границах, а языковой слой предоставляет легкодоступный и проверяемый вспомогательный текст. В сочетании эти элементы помогают добиться точных результатов, даже при ограничениях по количеству слов.
Мы преобразовали эти результаты в пошаговое руководство по SEO для брендов, сталкивающихся с ограничениями при использовании поиска на основе искусственного интеллекта.
- Отправка JSON‑LD для основных шаблонов
<ул> - Рецепты → Рецепт (ингредиенты, инструкция, выход, время).
- Товары → Товар + Предложение (бренд, GTIN/SKU, цена, наличие, рейтинги).
- Статьи → Статья/НовостиСтатья (заголовок, автор, дата публикации).
- Объединить сущность + лексику
Сохраняйте спецификации, часто задаваемые вопросы и текст политик разбивками и с привязкой к сущностям. - Усиление фрагмента поверхности
Факты должны быть согласованы как в видимом HTML, так и в JSON‑LD; важные факты должны находиться в верхней части страницы и быть стабильными. - Инструмент
Отслеживайте разброс, а не только средние значения. Оценивайте охват ключевых слов/полей внутри машинных сводок по шаблону.
Заключение
Структурированные данные не делают AI-рефераты длиннее или короче, но *действительно* делают их более надёжными. Они помогают создавать последовательные рефераты и контролировать, какая информация включена. С будущими AI-моделями, такими как GPT-5 – особенно при ограничении определённым количеством слов – эта надёжность приводит к лучшим ответам, меньшему количеству случаев неверной информации и повышению узнаваемости вашего бренда в AI-генерируемых результатах.
После многих лет работы с веб-сайтами я усвоил одну вещь о SEO: рассматривайте структурированные данные как фундаментальную часть вашего сайта, а не просто дополнение. Если базовый HTML вашего сайта не организован и не имеет смысла, не спешите использовать JSON-LD. Серьезно, сначала приведите в порядок свой код *first*. Убедитесь, что базовая структура правильная, а затем добавляйте структурированные данные поверх нее. Речь идет о создании прочного, семантического фундамента, который поможет поисковым системам – особенно с развитием AI поиска – действительно понять, о чем ваш контент. В наши дни самое важное – насколько *meaningful* ваш контент.
Смотрите также
- Google Merchant Center теперь позволяет вам выбирать способы оплаты
- Акции PHOR. ФосАгро: прогноз акций.
- Новые Playbooks Google Business Profile с советами по локальной оптимизации.
- Акции MRKV. МРСК Волги: прогноз акций.
- Биткойна «Время взрыва» – Видение Сатоши подрывается?
- WP Engine против Automattic: судья склонен вынести предварительный судебный запрет
- Изображения Google Ads с искусственным интеллектом Теперь могут создавать людей и лица
- Акции ROLO. Русолово: прогноз акций.
- Акции EUTR. ЕвроТранс: прогноз акций.
- Важные функции поисковой выдачи торговой площадки Google
2025-10-15 15:41