

Как опытный специалист по SEO с многолетним опытом работы за плечами, я не могу не подчеркнуть важность получения последних мета- и HTML-тегов для оптимизации веб-сайтов. Увидев радикальные изменения в алгоритмах поисковых систем за последние годы, я понял, что игнорирование этих тегов может означать потерю ценного органического трафика.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)В этом последнем сборнике статей мы стремимся провести вас через процесс сотрудничества с моделями больших языков (LLM), чтобы усилить ваши усилия по SEO. Наша цель — предоставить вам знания, необходимые для беспрепятственного внедрения искусственного интеллекта в вашу стратегию SEO, тем самым повысив ваш опыт в этой области.
Я рад, что предыдущая статья оказалась для вас информативной. Позвольте мне разъяснить вам понятия векторов, векторного расстояния и встраивания текста.
После этого работайте над улучшением своего «понимания концепций ИИ», изучая методы выявления совпадения ключевых слов с помощью встраивания текста.
Мы начнем с встраивания текста OpenAI и сравним их.
| Модель | Размерность | Цены | Примечания |
|---|---|---|---|
| встраивание текста-ада-002 | 1536 | 0,10 доллара США за 1 миллион токенов | Отлично подходит для большинства случаев использования. |
| встраивание текста-3-маленький | 1536 | 0,002 доллара США за 1 миллион токенов | Быстрее и дешевле, но менее точно |
| встраивание текста-3-большой | 3072 | 0,13 доллара США за 1 миллион токенов | Более точный для сложных задач, связанных с длинным текстом, медленнее |
(*токены можно рассматривать как слова.)
Но прежде чем мы начнем, вам необходимо установить Python и Jupyter на свой компьютер.
Jupyter — это универсальный инструмент для экспертов и исследователей, позволяющий им проводить сложный анализ данных и создавать продвинутые модели машинного обучения, используя предпочитаемые ими языки программирования в веб-среде.
Не беспокойтесь: завершить установку довольно просто и не отнимет у вас много времени. Кроме того, считайте ChatGPT своим полезным помощником в написании кода.
В двух словах:
- Загрузите и установите Python.
- Откройте командную строку Windows или терминал на Mac.
- Введите эти команды
pip install jupyterlabиpip install Notebook - Запустите Jupiter этой командой:
jupyter lab
Мы будем использовать Jupyter для экспериментов с встраиванием текста; вы увидите, как весело с вами работать!
Но прежде чем мы начнем, вы должны зарегистрироваться в API OpenAI и настроить выставление счетов, пополнив свой баланс.
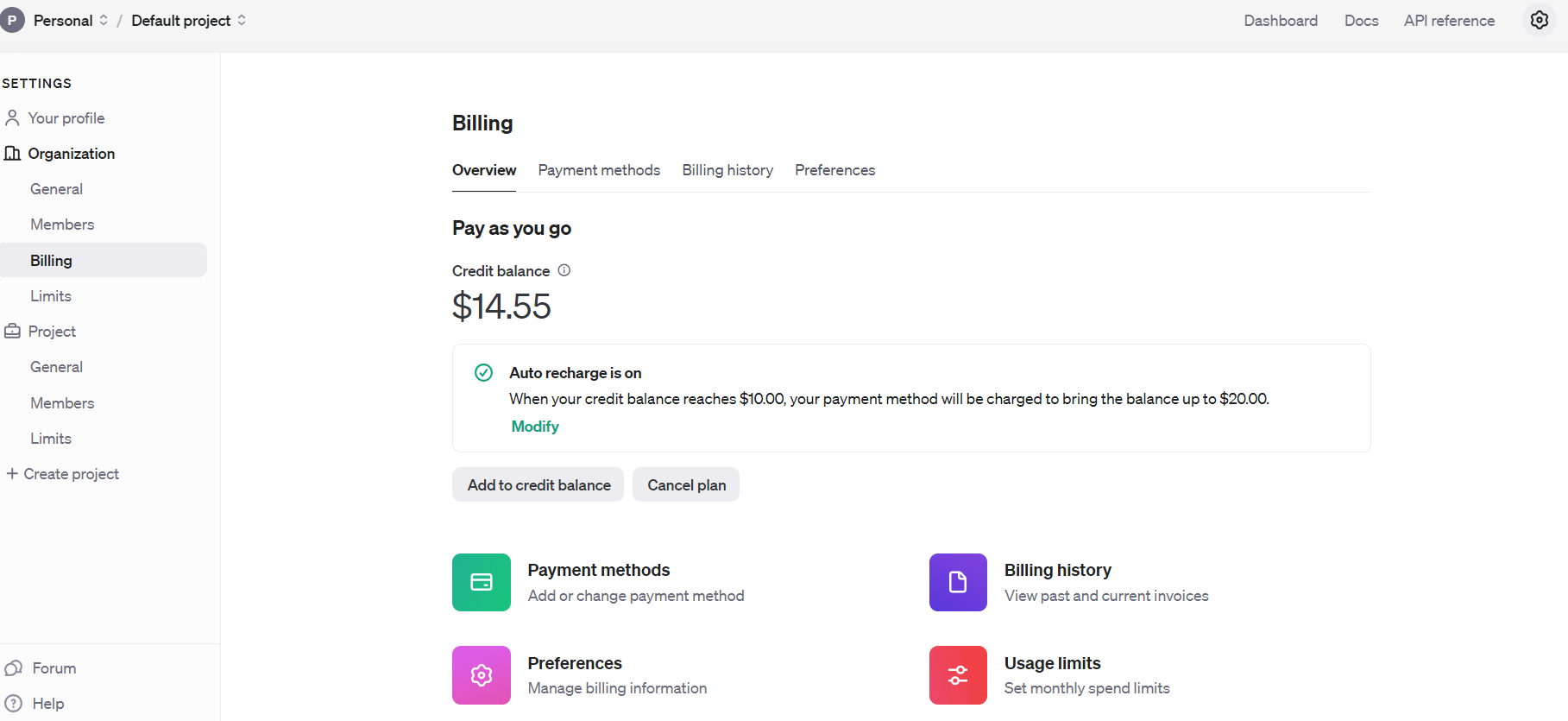
После выполнения этой задачи настройте оповещения по электронной почте, чтобы уведомлять вас, когда ваши расходы превышают заранее определенный порог, называемый «лимитами использования».
После этого получите ключи API через раздел «Панель управления», а именно «Ключи API». Не забывайте беречь эти ключи и не разглашать их публично.
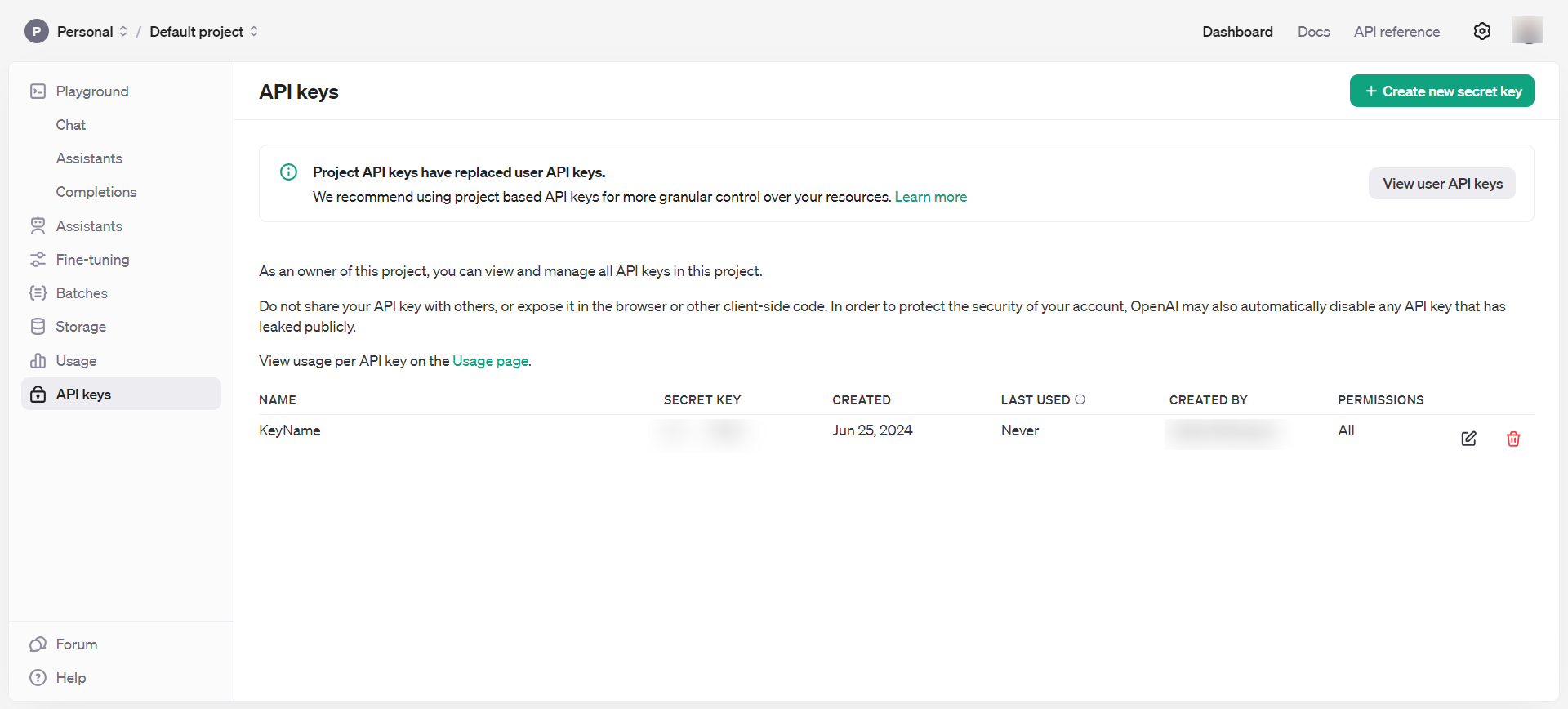
Теперь у вас есть все необходимые инструменты, чтобы начать экспериментировать с встраиваниями.
- Откройте командный терминал вашего компьютера и введите
jupyter lab. - В вашем браузере вы должны увидеть что-то вроде изображения ниже.
- Нажмите Python 3 в разделе Блокнот.
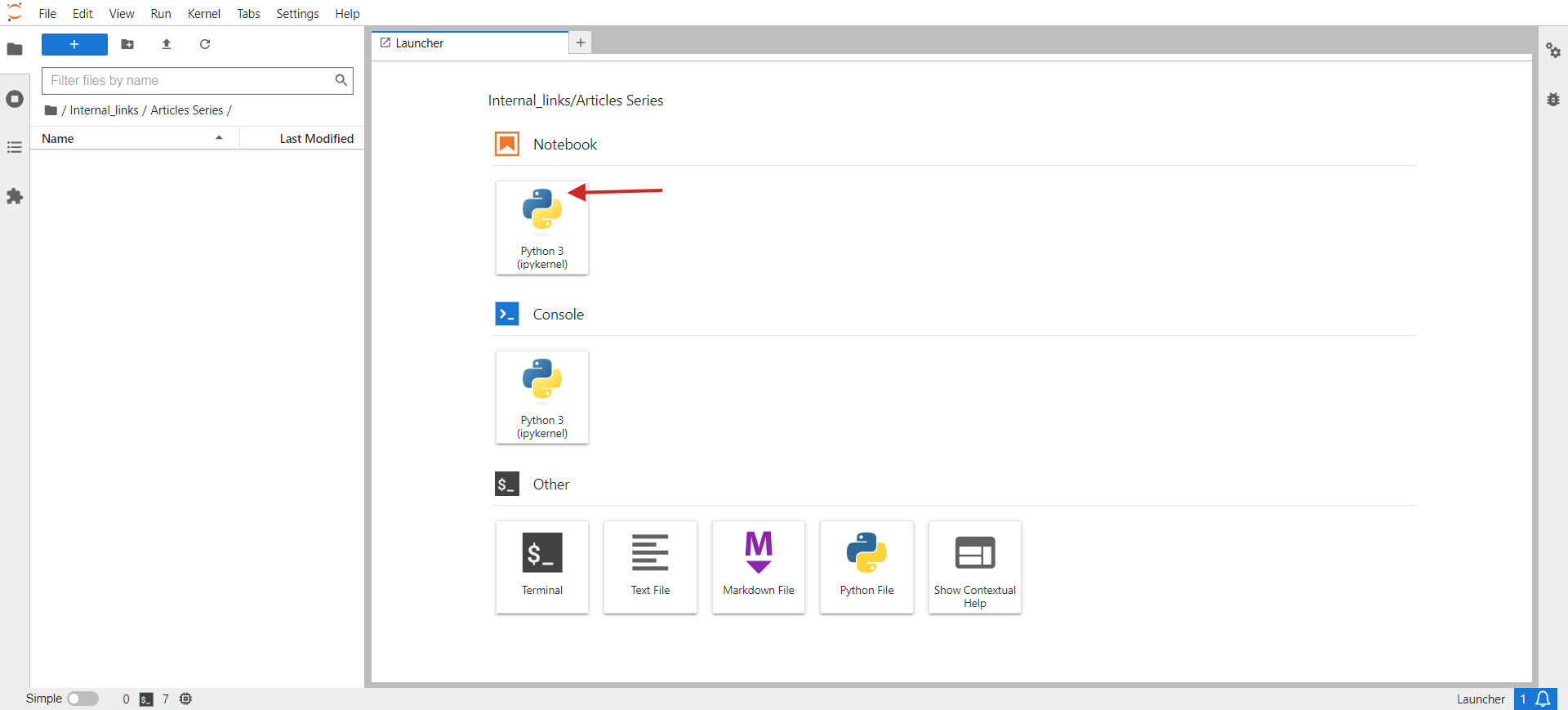
В открывшемся окне вы напишете свой код.
В качестве небольшой задачи давайте сгруппируем похожие URL-адреса из CSV. Образец CSV-файла содержит два столбца: URL-адрес и заголовок. Задача нашего скрипта будет состоять в том, чтобы сгруппировать URL-адреса со схожим семантическим значением на основе заголовка, чтобы мы могли объединить эти страницы в одну и исправить проблемы каннибализации ключевых слов.
Вот шаги, которые вам нужно сделать:
Чтобы установить необходимые библиотеки Python с помощью терминала вашего ПК или ноутбука Jupyter, используйте pip — установщик пакетов для Python.
pip install pandas openai scikit-learn numpy unidecode
Чтобы использовать API OpenAI и получать внедрения, вам необходимо использовать библиотеку openai. Между тем, «панды» пригодятся для управления данными и работы с файлами CSV.
Для расчета сходства косинусов необходима библиотека scikit-learn. Однако для обработки числовых операций и управления массивами вам понадобится библиотека numpy. Наконец, unidecode пригодится для очистки текста.
После этого вы можете получить образец данных в виде файла CSV для сохранения, присвоить ему имя «pages.csv» и впоследствии перенести его в каталог, в котором находится сценарий Jupyter Notebook.
Чтобы использовать API OpenAI с полученным ключом, замените заполнитель в следующем фрагменте кода своим конкретным ключом API, прежде чем вставлять его в свой блокнот:
Запустите код, щелкнув значок треугольника воспроизведения в верхней части блокнота.
import pandas as pd
import openai
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import csv
from unidecode import unidecode
# Function to clean text
def clean_text(text: str) -> str:
# First, replace known problematic characters with their correct equivalents
replacements = {
'–': '–', # en dash
'’': '’', # right single quotation mark
'“': '“', # left double quotation mark
'â€': '”', # right double quotation mark
'‘': '‘', # left single quotation mark
'â€': '—' # em dash
}
for old, new in replacements.items:
text = text.replace(old, new)
# Then, use unidecode to transliterate any remaining problematic Unicode characters
text = unidecode(text)
return text
# Load the CSV file with UTF-8 encoding from root folder of Jupiter project folder
df = pd.read_csv('pages.csv', encoding='utf-8')
# Clean the 'Title' column to remove unwanted symbols
df['Title'] = df['Title'].apply(clean_text)
# Set your OpenAI API key
openai.api_key = 'your-api-key-goes-here'
# Function to get embeddings
def get_embedding(text):
response = openai.Embedding.create(input=[text], engine="text-embedding-ada-002")
return response['data'][0]['embedding']
# Generate embeddings for all titles
df['embedding'] = df['Title'].apply(get_embedding)
# Create a matrix of embeddings
embedding_matrix = np.vstack(df['embedding'].values)
# Compute cosine similarity matrix
similarity_matrix = cosine_similarity(embedding_matrix)
# Define similarity threshold
similarity_threshold = 0.9 # since threshold is 0.1 for dissimilarity
# Create a list to store groups
groups = []
# Keep track of visited indices
visited = set
# Group similar titles based on the similarity matrix
for i in range(len(similarity_matrix)):
if i not in visited:
# Find all similar titles
similar_indices = np.where(similarity_matrix[i] >= similarity_threshold)[0]
# Log comparisons
print(f"\nChecking similarity for '{df.iloc[i]['Title']}' (Index {i}):")
print("-" * 50)
for j in range(len(similarity_matrix)):
if i != j: # Ensure that a title is not compared with itself
similarity_value = similarity_matrix[i, j]
comparison_result = 'greater' if similarity_value >= similarity_threshold else 'less'
print(f"Compared with '{df.iloc[j]['Title']}' (Index {j}): similarity = {similarity_value:.4f} ({comparison_result} than threshold)")
# Add these indices to visited
visited.update(similar_indices)
# Add the group to the list
group = df.iloc[similar_indices][['URL', 'Title']].to_dict('records')
groups.append(group)
print(f"\nFormed Group {len(groups)}:")
for item in group:
print(f" - URL: {item['URL']}, Title: {item['Title']}")
# Check if groups were created
if not groups:
print("No groups were created.")
# Define the output CSV file
output_file = 'grouped_pages.csv'
# Write the results to the CSV file with UTF-8 encoding
with open(output_file, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Group', 'URL', 'Title']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader
for group_index, group in enumerate(groups, start=1):
for page in group:
cleaned_title = clean_text(page['Title']) # Ensure no unwanted symbols in the output
writer.writerow({'Group': group_index, 'URL': page['URL'], 'Title': cleaned_title})
print(f"Writing Group {group_index}, URL: {page['URL']}, Title: {cleaned_title}")
print(f"Output written to {output_file}")
Этот код считывает файл CSV «pages.csv», содержащий заголовки и URL-адреса, которые вы можете легко экспортировать из своей CMS или получить, просканировав клиентский веб-сайт с помощью Screaming Frog.
Впоследствии он обрабатывает заголовки, удаляя символы, отличные от UTF, создает векторы внедрения для каждого заголовка с помощью API OpenAI, вычисляет сходство между заголовками, группирует похожие заголовки вместе и сохраняет кластеризованные данные в новый файл CSV с именем «grouped_pages.csv».
При назначении каннибализации ключевых слов мы установили порог сходства 0,9. Это означает, что если косинусное сходство ниже 0,9, мы классифицируем изделия как отдельные. Чтобы сделать это более понятным в двухмерном представлении, эти векторы кажутся расположенными под углом примерно 25 градусов друг от друга.
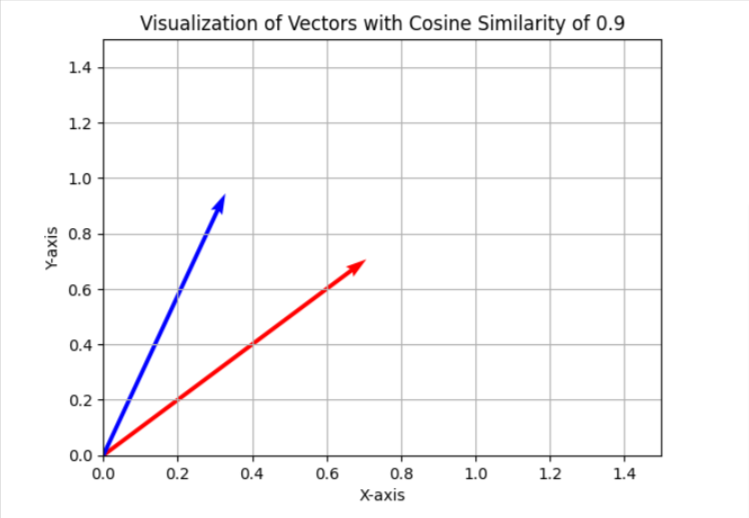
В вашей конкретной ситуации рассмотрите возможность изменения порога до 0,85, что соответствует разнице между точками данных примерно в 31 градус. Проверьте этот параметр на подмножестве ваших данных и оцените результаты и общее качество соответствия. Если результаты не оправдывают ожиданий, увеличьте порог повышения точности.
Вы можете установить matplotlib через терминал.
pip install matplotlibКак опытный специалист по данным с многолетним опытом за плечами, я не могу не призвать вас исследовать увлекательный мир косинусных сходств и визуализировать его в двумерном пространстве с помощью Python. Поверьте мне, это обогащающий опыт, который добавляет глубины вашим навыкам анализа данных!
import matplotlib.pyplot as plt
import numpy as np
# Define the angle for cosine similarity of 0.9. Change here to your desired value.
theta = np.arccos(0.9)
# Define the vectors
u = np.array([1, 0])
v = np.array([np.cos(theta), np.sin(theta)])
# Define the 45 degree rotation matrix
rotation_matrix = np.array([
[np.cos(np.pi/4), -np.sin(np.pi/4)],
[np.sin(np.pi/4), np.cos(np.pi/4)]
])
# Apply the rotation to both vectors
u_rotated = np.dot(rotation_matrix, u)
v_rotated = np.dot(rotation_matrix, v)
# Plotting the vectors
plt.figure
plt.quiver(0, 0, u_rotated[0], u_rotated[1], angles='xy', scale_units='xy', scale=1, color='r')
plt.quiver(0, 0, v_rotated[0], v_rotated[1], angles='xy', scale_units='xy', scale=1, color='b')
# Setting the plot limits to only positive ranges
plt.xlim(0, 1.5)
plt.ylim(0, 1.5)
# Adding labels and grid
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.grid(True)
plt.title('Visualization of Vectors with Cosine Similarity of 0.9')
# Show the plot
plt.show
При проверке каннибализации ключевых слов я обычно использую порог 0,9 или выше. Однако для перенаправления старых статей вам может потребоваться снизить порог до 0,5. Более старые статьи могут не иметь точных совпадений с более поздними, но все же имеют некоторое сходство.
Альтернативным подходом может быть объединение метаописания с тегом заголовка для перенаправленных страниц. Это обеспечивает единообразие в том, как поисковые системы отображают информацию о вашей веб-странице.
В зависимости от конкретной задачи мы подробно рассмотрим процесс реализации перенаправлений в следующей статье этой серии.
Давайте рассмотрим результаты трех моделей, которые мы обсуждали ранее. Мы оценим их эффективность в распознавании похожих статей из набора данных Search Engine Journal.
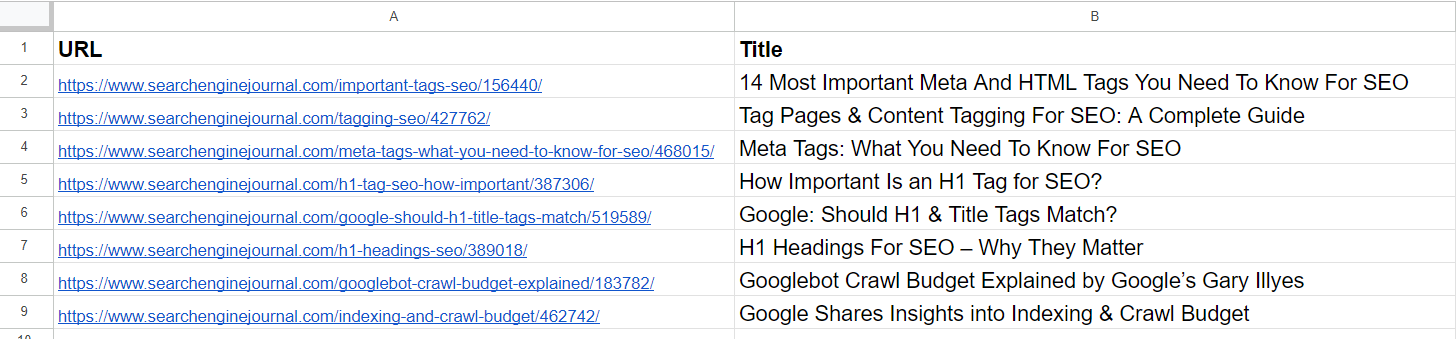
Судя по приведенному списку, становится ясно, что вторая и четвертая статьи посвящены одной и той же теме, касающейся «мета-тегов». Кроме того, пятая и седьмая статьи имеют схожее содержание о значении тегов H1 в SEO, что позволяет их объединить.
Статья в третьем ряду не похожа ни на одну другую статью в списке, но в ней используются общие термины, такие как «Тег» и «SEO».
В шестой строке вы найдете статью, в которой еще раз обсуждается H1, но с другой точки зрения на значение H1 для SEO. Это отражает точку зрения Google относительно того, насколько тесно H1 и другие факторы ранжирования должны совпадать.
Статьи в 8-й и 9-й строках довольно близки, но все же различны; их можно комбинировать.
встраивание текста-ада-002
Используя «text-embedding-ada-002», мы определили вторую и четвертую статьи, которые имеют высокую степень сходства с показателем косинусного сходства 0,92. Аналогичным образом, пятая и седьмая статьи демонстрируют сильное сходство с показателем косинусного сходства 0,91.
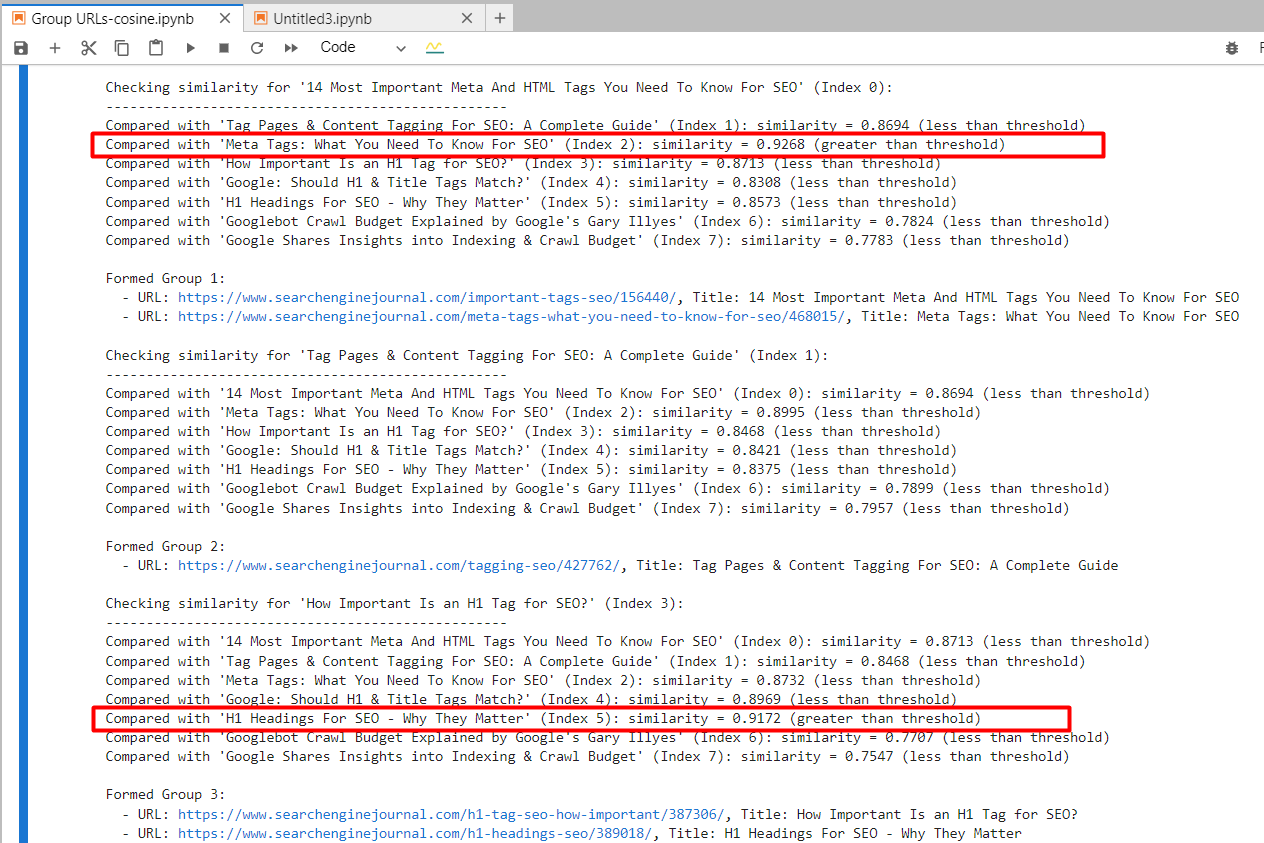
Как специалист по цифровому маркетингу, я реализовал решение, которое группировало URL-адреса на основе сходства их контента. Это было достигнуто путем присвоения одного и того же номера группы URL-адресам с сопоставимыми статьями. Важно отметить, что цветовое кодирование применяется вручную для улучшения визуального представления.
Для второй и третьей статей, которые используют термины «Тег» и «SEO», но не связаны друг с другом, косинусное сходство было рассчитано равным 0,86. Этот вывод подчеркивает важность установления строгого порога сходства, например 0,9 или выше. Если бы вместо этого мы снизили его до 0,85, результаты, скорее всего, включали бы множество ложных срабатываний и потенциально могли бы предложить объединить статьи, которые не связаны друг с другом.
встраивание текста-3-маленький
Используя модель «text-embedding-3-small», мы обнаружили, что при применении порога сходства 0,9 или выше совпадений не обнаружено.
Косинусное подобие между 2-м и 4-м изделиями составило 0,76, а между 5-м и 7-м изделиями — 0,77.
Чтобы глубже понять эту модель, я представил исправленную версию первой строки с «пятнадцатью» вместо «четырнадцати» для сравнительного анализа в наборе данных.
- «14 самых важных мета- и HTML-тегов, которые нужно знать для SEO»
- «15 самых важных мета- и HTML-тегов, которые нужно знать для SEO»

Напротив, «text-embedding-ada-002» дал косинусное сходство между этими версиями на уровне 0,98.
| Название 1 | Название 2 | Косинусное сходство |
| 14 самых важных мета- и HTML-тегов, которые нужно знать для SEO | 15 Наиболее важные мета- и HTML-теги, которые необходимо знать для SEO | 0,92 |
| 14 самых важных мета- и HTML-тегов, которые нужно знать для SEO | Мета-теги: что нужно знать для SEO | 0,76 |
Здесь мы видим, что эта модель не совсем подходит для сравнения названий.
встраивание текста-3-большой
Размерность этой модели составляет 3072, что в два раза больше, чем у «text-embedding-3-small» и «text-embedding-ada-002», каждая из которых имеет размерность 1536.
Как опытный веб-мастер, я заметил, что эта модель, благодаря своей многомерной природе, может представлять семантические значения более точно, чем другие модели.
Косинусное подобие между 2-м и 4-м изделиями составило 0,70, а между 5-м и 7-м изделиями — 0,75.
Я проводил эксперименты, используя измененные варианты исходной статьи, сравнивая цифры «15» и «14» и исключая из названия «Самое важное».
- «14 самых важных мета- и HTML-тегов, которые нужно знать для SEO»
- «15 самых важных мета- и HTML-тегов, которые нужно знать для SEO»
- «14 мета- и HTML-тегов, которые нужно знать для SEO»
| Название 1 | Название 2 | Косинусное сходство |
| 14 самых важных мета- и HTML-тегов, которые нужно знать для SEO | 15 Наиболее важные мета- и HTML-теги, которые необходимо знать для SEO | 0,95 |
| 14 самых важных мета- и HTML-тегов, которые нужно знать для SEO | 14 |
0,93 |
| 14 самых важных мета- и HTML-тегов, которые нужно знать для SEO | Мета-теги: что нужно знать для SEO | 0,70 |
| 15 самых важных мета- и HTML-тегов, которые нужно знать для SEO | 14 |
0,86 |
Похоже, что «text-embedding-3-large» уступает по производительности по сравнению с «text-embedding-ada-002» при вычислении косинусного сходства с использованием данных заголовка.
Основываясь на моем обширном опыте обработки естественного языка и работе с различными моделями встраивания текста, я могу засвидетельствовать интригующее наблюдение, что «text-embedding-3-large» показывает повышение точности по мере увеличения длины текста. Однако важно признать, что «text-embedding-ada-002» в целом превосходит «text-embedding-3-large», исходя из моего личного опыта реализации и сравнения этих моделей в многочисленных проектах.
Альтернативный метод — исключить из текста общие слова, называемые «стоп-словами». Таким образом, модель может больше сосредоточиться на важных терминах, повышая точность различных задач, таких как определение сходства.
Как опытный веб-мастер с большим опытом анализа текста, я могу предположить, что наиболее эффективный метод выяснить, повышает ли удаление стоп-слов точность вашего конкретного задания и базы данных, — это экспериментальная оценка обоих методов и сопоставление их результатов.
Заключение
Используя эти иллюстрации, теперь у вас есть возможность выполнять различные задания, используя модели внедрения OpenAI.
Как специалист по цифровому маркетингу, я понимаю важность установки соответствующих порогов сходства для моего конкретного случая использования. Однако определение идеального порога не является универсальным решением. Чтобы найти то, что работает лучше всего, я предлагаю поэкспериментировать с моими собственными наборами данных, пропустив через систему небольшие выборки и проведя тщательную человеческую проверку результатов. Это поможет мне оценить эффективность каждого порогового значения и принять обоснованные решения на основе результатов.
Основываясь на моем обширном опыте обработки данных и понимании естественного языка, я твердо убежден, что код, представленный в этой статье, возможно, не является самым эффективным решением для обработки больших наборов данных. Причина в том, что каждый раз, когда в вашем наборе данных происходит обновление, вам необходимо создавать новые встраивания текста. Это может оказаться весьма ресурсоемким и трудоемким, особенно при работе с огромными объемами данных. В своем профессиональном пути я сталкивался с аналогичными проблемами и узнал, что предварительные вычисления и хранение встраивания текста могут значительно повысить производительность и масштабируемость вашего конвейера обработки данных. Итак, я бы посоветовал рассмотреть этот метод оптимизации, чтобы сделать ваш код более эффективным для больших наборов данных.
Для оптимальной эффективности вместо этого рекомендуется использовать векторные базы данных для хранения сгенерированной информации о встраивании. Вскоре мы подробно обсудим использование векторных баз данных, так что следите за обновлениями. Тем временем обновите свой пример кода соответствующим образом, чтобы включить базу данных векторов.
Смотрите также
- Акции CBOM. МКБ: прогноз акций.
- Часть 1. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Google может меньше полагаться на Hreflang и перейти на автоматическое определение языка
- Акции AKRN. Акрон: прогноз акций.
- Anthropic анонсирует бесплатный чат-бот Claude AI для Android
- Часть 3: Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Танец бычьего роста Биткойна: сможет ли он вальсировать до 144,000 долларов?
- Акции GAZP. Газпром: прогноз акций.
- Google AIO отправляет больше трафика на YouTube.
- В Google Maps появилось обновление, направленное на борьбу с фейковыми отзывами.
2024-07-26 13:39