

Я только что увидел, что Google опубликовал новое руководство по поддержке под названием «Things to know about Google’s web crawling». По сути, в нём рассказывается о том, как работает Googlebot — на данный момент они охватывают девять ключевых моментов, которые нужно понимать о том, как они сканируют веб. Это хорошее чтение, если вы хотите знать, что происходит под капотом!
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Google создала этот документ, чтобы ответить на часто задаваемые вопросы о сканировании. Это полезное руководство для владельцев веб-сайтов, желающих узнать больше о том, как Google сканирует веб-сайты, и предоставляет ссылки на полезные ресурсы.
Вот краткая версия этого документа, но также ознакомьтесь с полной версией:
- Что такое обход? Короче говоря, обход — это то, как Google ‘видит’ веб
- У нас много обходчиков; у каждого из них есть важные задачи
- Мы выполняем повторные обходы, чтобы найти последние обновления и предоставить самые свежие результаты поиска
- Частый обход — это хороший знак!
- Обход Google со временем расширялся по мере того, как страницы становились более сложными
- Мы автоматически оптимизируем обход
- Обходчики Google никогда не заходят в контент за платной стеной или по подписке без разрешения
- Владельцы сайтов контролируют, что обходится и как
- Наши стандартные обходчики всегда уважают выбор веб-сайтов относительно того, как осуществляется доступ к их контенту и как он используется
Эта страница стоит того, чтобы её прочитать, ознакомьтесь с ней по адресу Things to know about Google’s web crawling.
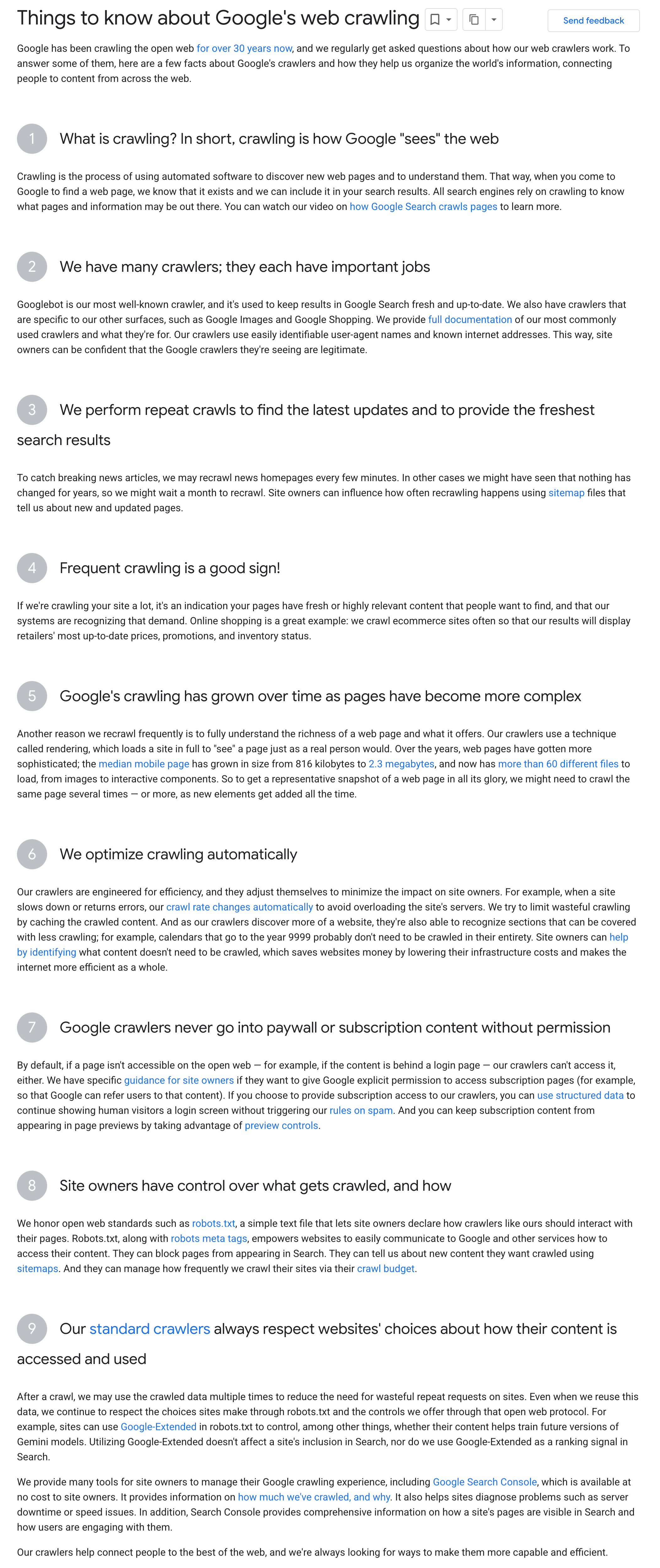
Вот скриншот этой страницы для архивных целей:
Смотрите также
- Анализ динамики цен на криптовалюту STX: прогнозы STX
- Акции NLMK. НЛМК: прогноз акций.
- Какой самый низкий курс евро к южноафриканскому рэнду?
- Анализ динамики цен на криптовалюту ETH: прогнозы эфириума
- Анализ динамики цен на криптовалюту TAO: прогнозы TAO
2026-03-04 16:45