Google и Microsoft сегодня объявили о своих последних финансовых результатах. Прибыль Google за третий квартал 2025 года показала увеличение доходов от рекламы на 13%, достигнув 74 миллиарда долларов, в то время как доходы от рекламы Microsoft в первом квартале 2026 года выросли на 16%. Общий доход Google увеличился на 16%, достигнув 102,3 миллиарда долларов — это его самый высокий квартальный доход за всю историю. Общий доход Microsoft вырос на 18%, составив 77,7 миллиарда долларов.
Мне нравится углубляться конкретно в доходы от рекламы, но обе компании выступили очень хорошо.
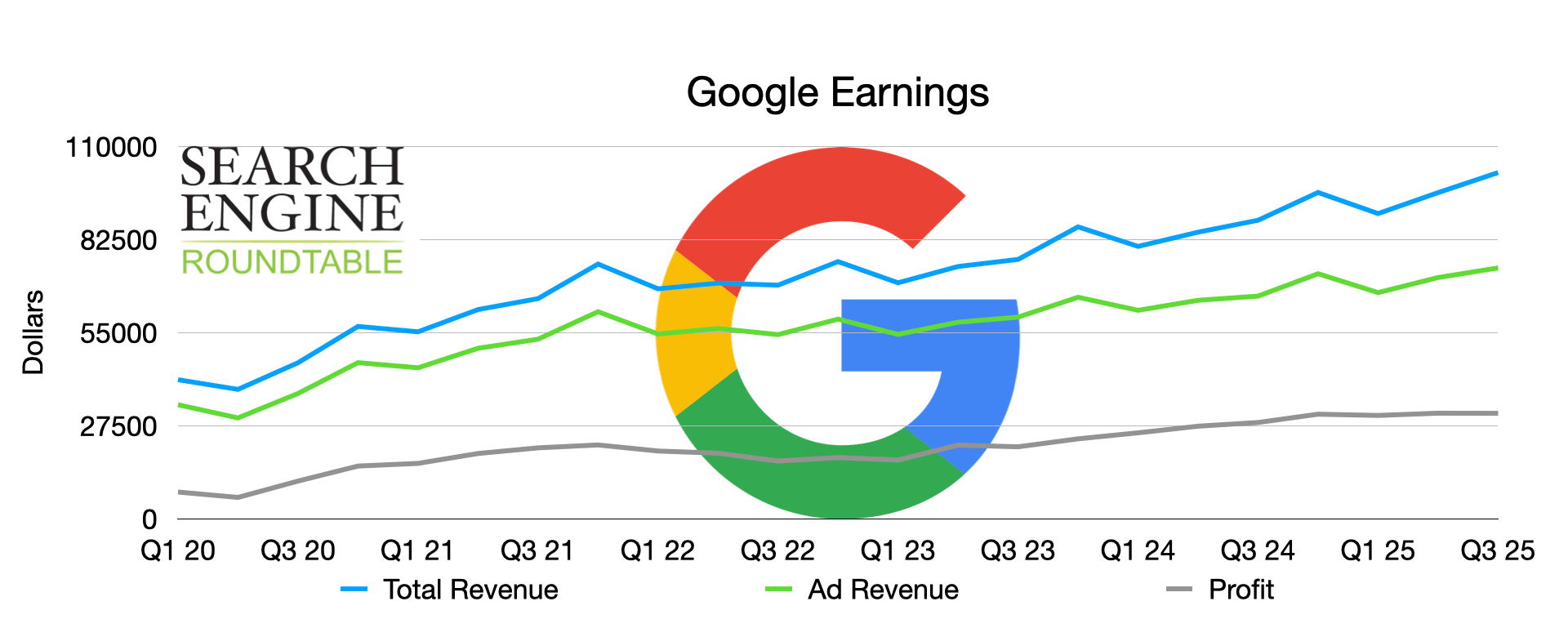
Прибыль GOOG
Google объявила о своих финансовых результатах за второй квартал 2025 года сегодня, показав продолжение роста доходов от рекламы – увеличение на 13% по сравнению с прошлым годом. В целом, доходы компании увеличились на 16%.
Сравнивая второй квартал 2025 года с первым, мы увидели увеличение рекламных доходов на 4%, увеличение общих доходов на 6,2% и отсутствие изменений в прибыли.
Сандар Пичаи, генеральный директор Google, заявил:
Alphabet показал отличный квартал с двузначным ростом по всем основным направлениям нашего бизнеса. Мы достигли первого в истории квартала с выручкой в 100 миллиардов долларов.
Этот график показывает, сколько денег компания Google заработала в целом, от рекламы и в качестве прибыли за последние несколько кварталов.
Вот выдержка из отчета о доходах:
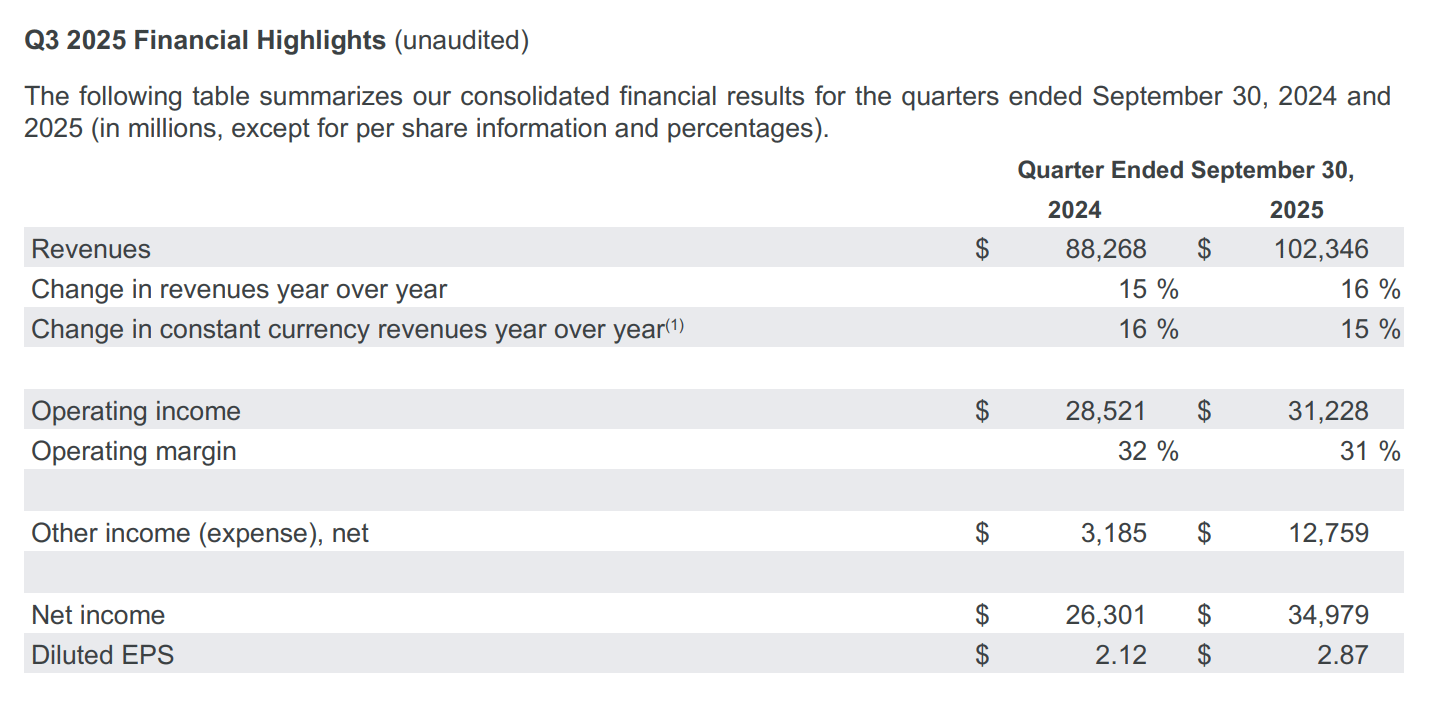
Основные моменты из отчёта о доходах Google:
- Выручка: $102,35 млрд против $99,89 млрд по скорректированной оценке
- Прибыль на акцию: $2,87, не подлежит немедленному сравнению
- Выручка от рекламы YouTube: $10,26 млрд против $10,01 млрд
- Выручка Google Cloud: $15,15 млрд против $14,74 млрд
- Затраты на привлечение трафика (TAC): $14,87 млрд против $14,82 млрд
Мы рады объявить о наших результатах за третий квартал! Впервые мы достигли 100 миллиардов долларов квартальной выручки, с уверенным двузначным ростом во всех областях нашего бизнеса. (Пять лет назад наша квартальная выручка составляла 50 миллиардов долларов.) Наша комплексная стратегия искусственного интеллекта набирает обороты, и мы быстро выпускаем новые продукты и функции.
‘ Sundar Pichai (@sundarpichai) 29 октября 2025 г.
Компания Google недавно сообщила о сильных финансовых результатах, подчеркнув, что её новые AI Overviews значительно увеличивают поисковую активность. Они также отметили, что пользователи ищут в два раза чаще при использовании AI Mode. В течение последнего квартала Google добавила более 100 улучшений в AI Mode, что привело к общему увеличению поисковых запросов.
Прибыль Microsoft
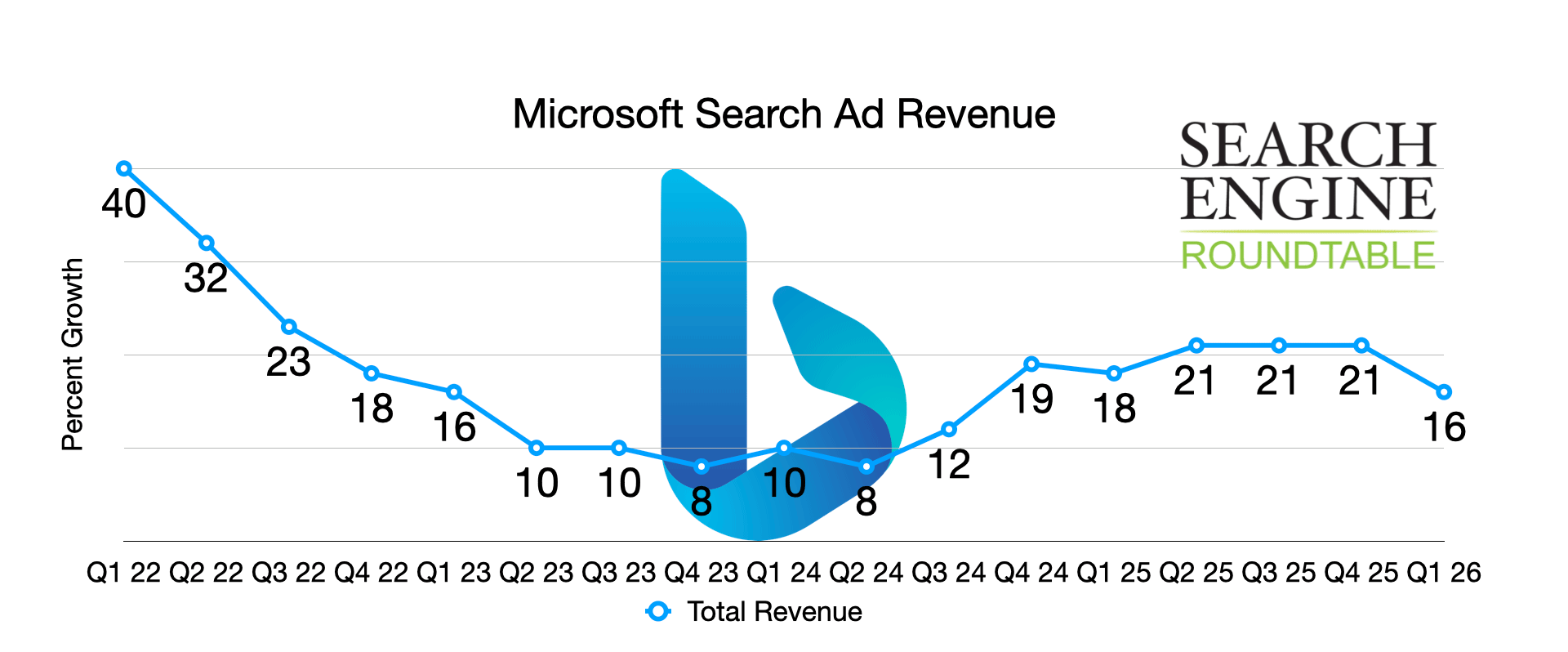
Microsoft объявила о своих финансовых результатах за первый квартал 2026 года, показав увеличение выручки от поиска и рекламы на 16%. Хотя это все еще положительный результат, этот рост является замедлением по сравнению с предыдущими тремя кварталами, в которых наблюдался рост на 21%. До этого рост составлял 18%, 19%, 12% и 8% в предыдущих кварталах.
Рекламные доходы Microsoft от поиска и новостей, не включая затраты на привлечение этого трафика, выросли на 16% (или на 15%, если рассчитывать с использованием стабильных валютных курсов).
Вот основные моменты финансового отчёта:
- Выручка составила 77,7 миллиарда долларов и увеличилась на 18% (рост на 17% в постоянной валюте)
- Операционная прибыль составила 38,0 миллиарда долларов и увеличилась на 24% (рост на 22% в постоянной валюте)
- Чистая прибыль по GAAP составила 27,7 миллиарда долларов и увеличилась на 12%, а по non-GAAP — 30,8 миллиарда долларов и увеличилась на 22% (рост на 21% в постоянной валюте)
- Прибыль на акцию, разводнённая, по GAAP составила 3,72 доллара и увеличилась на 13%, а по non-GAAP — 4,13 доллара и увеличилась на 23% (рост на 21% в постоянной валюте)
- Результаты по non-GAAP не включают влияние инвестиций в OpenAI, что объясняется в разделе «Определение non-GAAP» ниже
Вот разбивка того, как доходы от рекламы из поисковых источников и новостных ресурсов изменились каждый квартал.
Сатья Наделла, генеральный директор Microsoft, сказал:
‘Наша планетарная облачная и AI-фабрика, вместе с Copilots в высокоценных областях, стимулирует широкое распространение и реальное влияние’, — заявил Сатья Наделла, председатель и главный исполнительный директор Microsoft. ‘Именно поэтому мы продолжаем увеличивать наши инвестиции в AI как в капитале, так и в талантах, чтобы удовлетворить огромные возможности впереди.’
Мы создаём масштабную глобальную облачную инфраструктуру и центр разработки ИИ. В этом году мы увеличиваем наши вычислительные мощности ИИ на 80%, и планируем почти удвоить размер наших центров обработки данных в течение следующих двух лет. Ключевой частью этого расширения является Fairwater в Висконсине, который станет самым мощным в мире центром обработки данных ИИ, в конечном итоге потребляющим до двух гигаватт электроэнергии.
— Satya Nadella (@satyanadella) October 29, 2025
Эта неделя ознаменовалась значительным достижением – подписанием нового соглашения с OpenAI, которое принесет пользу обеим нашим компаниям. Эта инвестиция оказалась чрезвычайно успешной, принеся почти десятикратную отдачу без каких-либо комиссий – то есть вся прибыль идет напрямую нашим акционерам. Я также очень рад сообщить, что Microsoft теперь поддерживает…
— Satya Nadella (@satyanadella) October 29, 2025
Во время телефонной конференции Microsoft представители заявили, что страницы результатов поиска Bing теперь оснащены встроенными инструментами для общения, и Bing увеличил свою долю на рынке поиска.
Смотрите также
2025-10-30 02:46