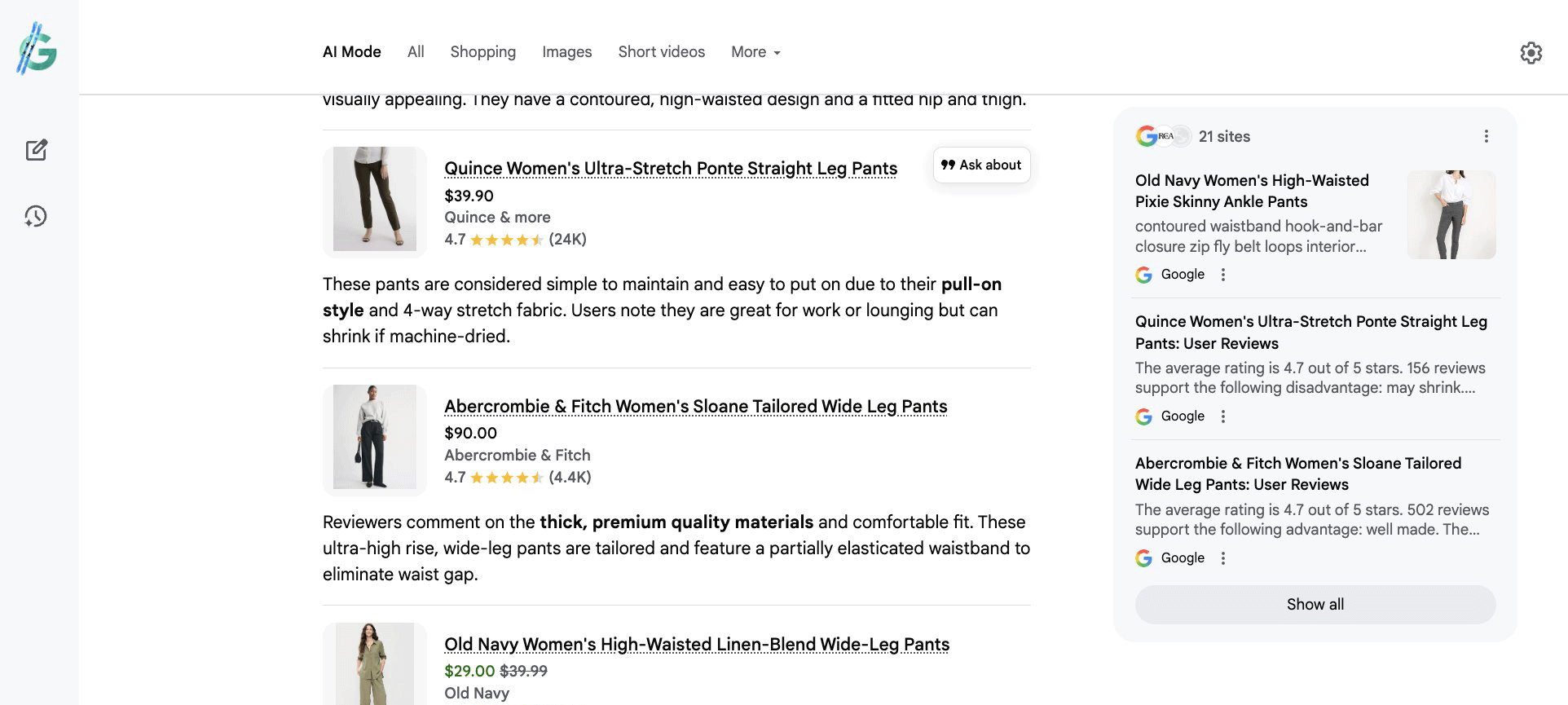
Некоторые издатели Google AdSense сталкиваются с проблемой, когда определённые рекламные объявления (якорные и виньеточные объявления) остаются открытыми для пользователей. Google знает об этой проблеме с 13 февраля и в настоящее время работает над её решением.
Google рекомендует пользователям, затронутым проблемой, отключить рекламу Anchor и Vignette до выхода решения.
Многие пользователи сообщили об этой проблеме на форуме поддержки Google AdSense. Вот некоторые скриншоты из этих обсуждений:
Похоже, нет возможности закрыть эту рекламу. Это недосмотр или это было сделано намеренно? Шучу, конечно.
Я увидел эту информацию, которой поделился Бруно Рамос Лара на X (ранее Twitter), и вот что, как сообщается, поддержка Google сообщила издателям AdSense:
Официальное обновление от поддержки Google: Они подтвердили, что это ‘регрессия на стороне продукта’, затронувшая множество издателей, начиная с 13 февраля. Они рекомендовали отключить Anchor и Vignette рекламу до развертывания исправления. Они активно работают над этим.
Доброе утро всем. Мы по-прежнему наблюдаем проблемы с выравниванием рекламы здесь, в Испании, и теперь это также влияет на медийную рекламу. Пользователи сообщают о горизонтальной прокрутке даже с рекламой, для которой установлен фиксированный размер, что, безусловно, вызывает опасения. Нам нужно немедленно это расследовать.
Bruno Ramos Lara (@brunoramoslara) February 18, 2026
Смотрите также
- Часть 1. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Акции CBOM. МКБ: прогноз акций.
- Google может меньше полагаться на Hreflang и перейти на автоматическое определение языка
- Акции GAZP. Газпром: прогноз акций.
- Часть 2. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Google Реклама тестирует расширяемую и сворачиваемую рекламу-карусель и дорабатывает ее
- Новый отчет показывает, что тенденции в сфере искусственного интеллекта стабилизируются
- Интеграция Google Lens для YouTube Shorts: Поиск внутри видео.
- Акции привилегированные ZILLP. ЗИЛ: прогноз акций привилегированных.
- Акции SOFL. Софтлайн: прогноз акций.
2026-02-18 15:45