В предыдущем месяце мы обсуждали антиспамные инициативы Google Maps; однако возможно вы не знали, что огромное количество отзывов было опубликовано на Google Maps только в 2024 году! Эта колоссальная доля составила примерно 999 миллионов отзывов, 752 миллиона изображений и видеозаписей, а также впечатляющие 94 миллиона правок информации о местах.
Google раскрыл информацию о том, что приблизительно 999 миллионов отзывов пользователей на Google Maps в первую очередь были сосредоточены на категориях таких как питание (еда и напитки), розничная торговля (покупки), услуги, досуг (развлечения и отдых), здоровье и фитнес, а также размещение (отели и проживание).
Я наткнулся на информацию, которой поделился Крис Сильвер Смит (Chris Silver Smith), где он упомянул, что Google Карты недавно выпустили свой отчет о доверии и безопасности контента. В отчете говорится, что за год 2024 года они обработали почти миллиард отзывов.
Вот некоторые ключевые моменты из отчета о прозрачности:
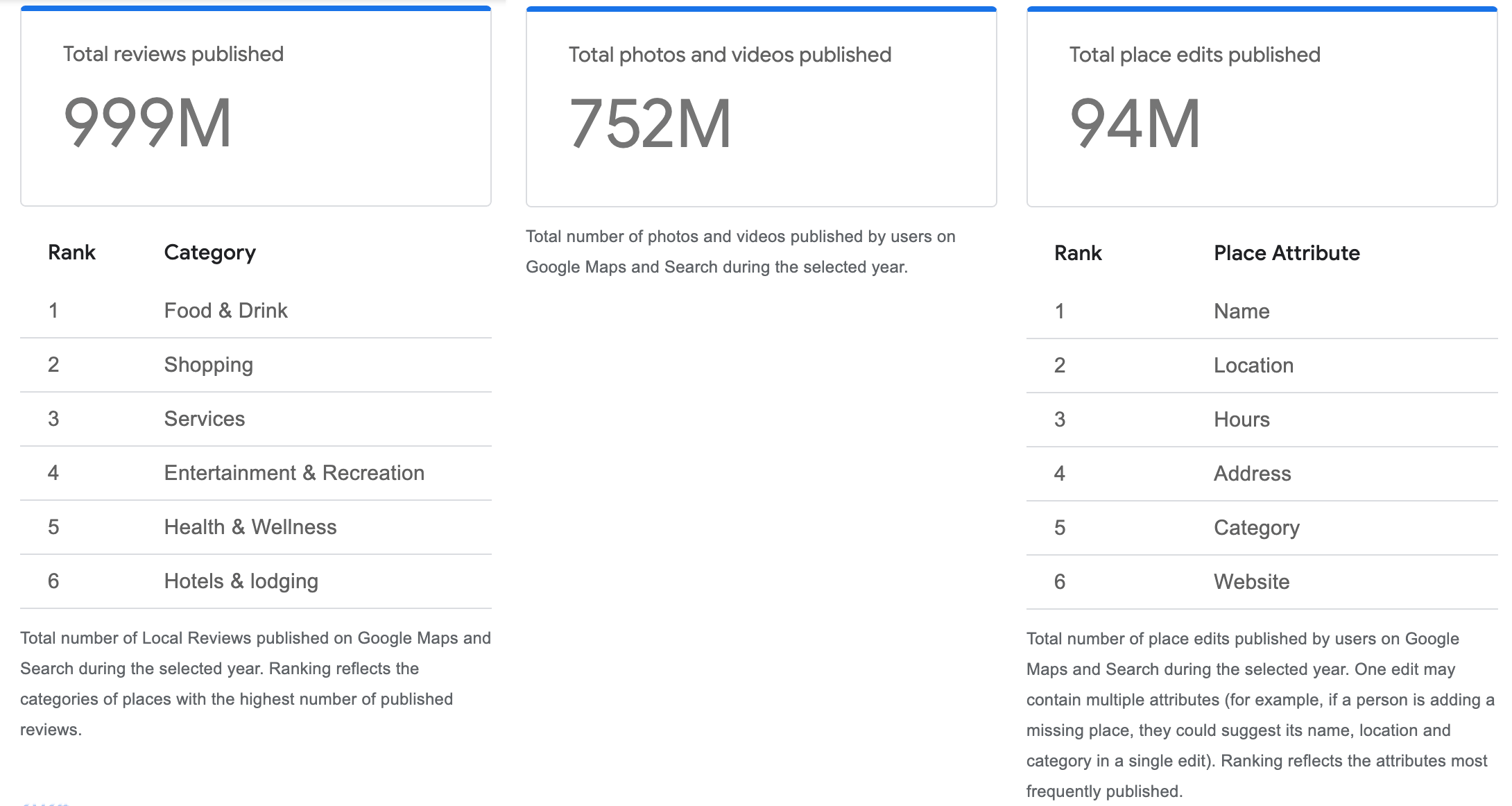
Это множество отзывов и вкладов пользователей в Google Maps.
— Любой может получить доступ ко всей информации, включенной в наш полный отчет о прозрачности.
— В прошлом месяце мы обсуждали раздел об исполнении во время нашего собрания.
Смотрите также
- Серебро прогноз
- Золото прогноз
- Акции LIFE. Фармсинтез: прогноз акций.
- Анализ динамики цен на криптовалюту LTC: прогнозы лайткоина
- Прогноз нефти
- Акции SFIN. ЭсЭфАй: прогноз акций.
- 10 октября снова наблюдается нестабильность рейтинга в Google Поиске
- Новое руководство по эффективности рекламных кампаний Google: лучшие практики
- Анализ динамики цен на криптовалюту FLR: прогнозы FLR
- Google возобновляет создание изображений с помощью ИИ с новыми мерами безопасности
2025-05-16 15:14