

У меня была возможность поработать над интересным проектом, который включал создание помощника по SEO с использованием больших языковых моделей (LLM), GraphRAG и доступа к внешним API. Как человек, проработавший много лет в индустрии SEO, я могу подтвердить потенциал этой технологии для автоматизации и доступа к знаниям.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Мы живем в захватывающую эпоху, когда достижения ИИ меняют профессиональную практику.
Как эксперт по SEO, я воочию стал свидетелем того, как GPT-3 с момента своего запуска произвел революцию в создании контента для профессионалов в области SEM. Вместо того, чтобы вручную создавать или редактировать текст, теперь мы можем использовать эту передовую технологию, чтобы оптимизировать наши процессы и сосредоточиться на других важных аспектах наших стратегий цифрового маркетинга.
Внедрение ChatGPT в конце 2022 года вызвало волну развития помощников ИИ.
Как человек, внимательно следящий за разработками в области искусственного интеллекта, я искренне рад объявлению OpenAI к концу 2023 года. исключение.
Обещания GPT
Как специалист по цифровому маркетингу, я в восторге от достижений в области технологий, которые приблизили нас к реализации давней мечты о личном помощнике. GPT (технологии общего назначения) сыграли важную роль в прокладывании пути для этого развития. В частности, модели разговорного большого языка (LLM) представляют собой захватывающую эволюцию человеко-машинных интерфейсов. Эти модели могут понимать запросы на естественном языке и отвечать на них в разговорной форме, что делает взаимодействие с технологиями более интуитивным и удобным для пользователя.
Чтобы создать мощных помощников в области искусственного интеллекта, необходимо решить несколько задач: воспроизвести логическое мышление, предотвратить заблуждения и расширить возможности эффективного использования внешних ресурсов.
Наш путь к разработке SEO-помощника
Последние пару месяцев мы с Гийомом и Томасом, моими доверенными коллегами, вместе углублялись в эту тему.
Я представляю здесь процесс разработки нашего первого прототипа SEO-помощника.
SEO-помощник, почему?
Наша цель — создать помощника, который будет способен:
- Генерация контента по брифам.
- Распространение отраслевых знаний о SEO. Он должен иметь возможность подробно отвечать на такие вопросы, как «Должно ли быть несколько тегов H1 на странице?» или «Является ли TTFB фактором ранжирования?»
- Взаимодействие с инструментами SaaS. Все мы используем инструменты с графическим пользовательским интерфейсом различной сложности. Возможность использовать их посредством диалога упрощает их использование.
- Планирование задач (например, управление полным редакционным календарем) и выполнение регулярных задач отчетности (например, создание информационных панелей).
В первоначальном задании магистры юридических наук (LLM) продемонстрируют значительный прогресс, если мы ограничим их доступ только достоверными данными.
Последний пункт о планировании все еще во многом находится в области научной фантастики.
Наши усилия были в первую очередь направлены на включение данных в систему с использованием таких методов, как методы RAG (на основе правил, на основе повестки дня) и GraphRAG (на основе графика, на основе правил и на основе повестки дня), а также на использование внешних API.
Подход RAG
Сначала мы создадим помощника на основе подхода дополненной генерации (RAG).
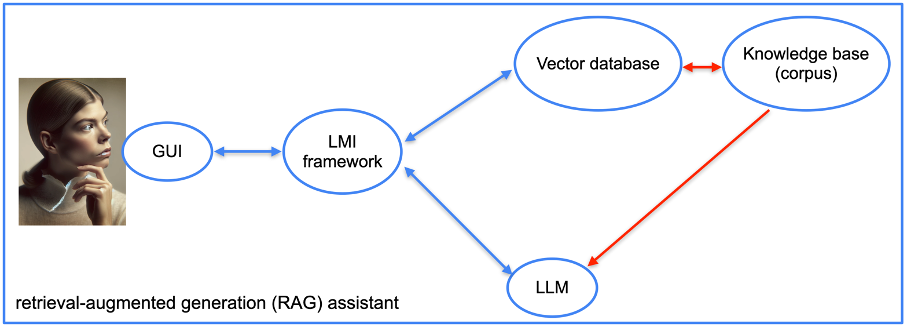
Как опытный веб-мастер, я бы порекомендовал для создания этого своего помощника использовать векторную базу данных. На выбор есть несколько вариантов: Redis, Elasticsearch, OpenSearch, Pinecone, Milvus, FAISS и другие. Лично я для нашего прототипа проекта выбрал векторную базу данных, предлагаемую LlamaIndex.
Чтобы эффективно связать нашу большую языковую модель (LLM) с базами данных и документами, нам требуется платформа интеграции языковой модели (LMI). Эта структура служит для устранения разрыва между LLM и источниками данных. В этой области существует несколько альтернатив, включая LangChain, LlamaIndex, Haystack, NeMo, Langdock, Marvin и другие. Для нашего конкретного проекта мы выбрали LangChain и LlamaIndex.
После выбора предпочитаемого стека программного обеспечения процесс внедрения значительно упрощается. Мы предлагаем документацию, которая преобразуется платформой в векторы кодирования контента.
Несколько технических факторов могут улучшить результаты, но продвинутые поисковые системы, такие как LlamaIndex, демонстрируют впечатляющую производительность.
Чтобы продемонстрировать эту концепцию, мы предоставили несколько книг по SEO на французском языке и несколько веб-страниц из известных источников SEO-сайтов.
Благодаря RAG меньше случаев неправильного восприятия и более полные ответы. На следующем изображении показан ответ, сгенерированный моделью родного языка (LLM) без RAG, а затем с интегрированным RAG для сравнения.

В этом случае подробности, предоставляемые RAG (оценка рисков и управление), превосходят информацию, предлагаемую независимой LLM (моделью с ограниченной ответственностью).
Подход GraphRAG
При работе с ответами, которые требуют интеграции данных из многочисленных источников, метод RAG (автоматическая генерация на основе правил) может не дать оптимальных результатов. Более эффективным решением было бы сначала предварительно обработать текстовые данные, чтобы выявить их внутреннюю структуру и сохранить семантику.
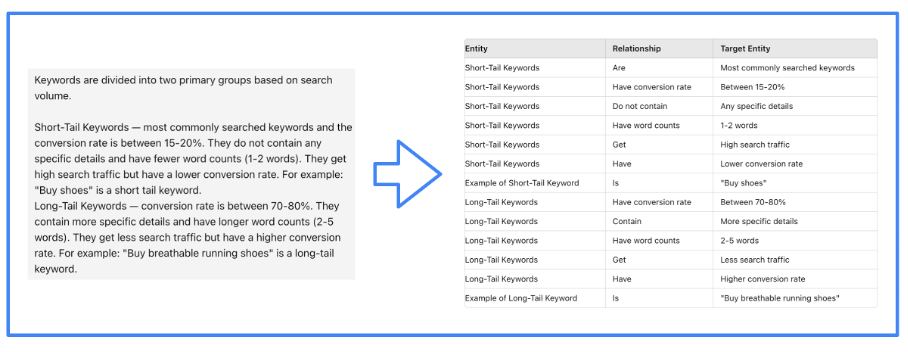
Создание графа знаний предполагает представление объектов реального мира и связей между ними в виде узлов графа, причем отношения определяются связями или ребрами. Эти отношения выражаются с помощью триады субъекта, отношения и объекта.
В приведенном ниже примере у нас есть представление нескольких сущностей и их отношений.
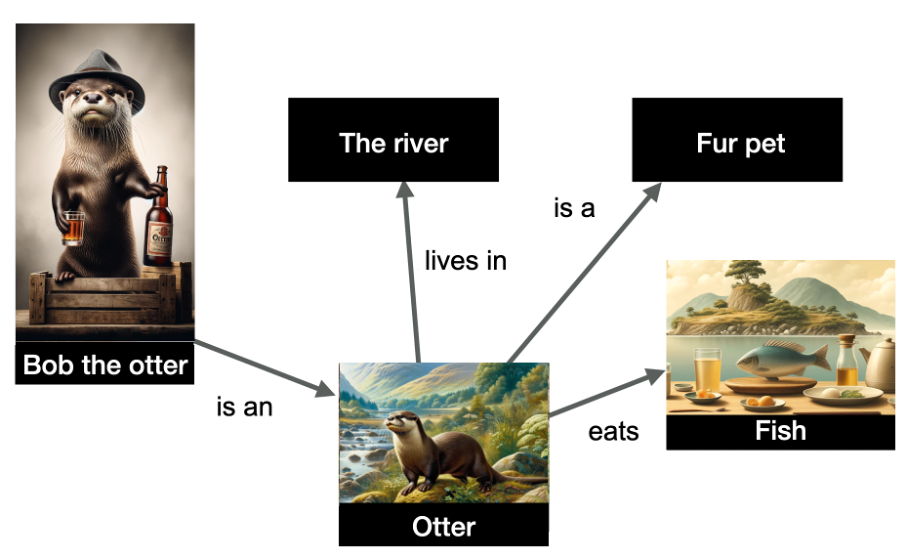
На графике «Выдра Боб» идентифицируется как именованный объект среди других объектов, таких как «река», «выдра», «питомец с мехом» и «рыба». Связи между этими объектами представлены через ребра графа.
Основываясь на моем обширном опыте работы с графиками данных и знаний, я могу с уверенностью сказать, что представленная здесь информация хорошо организована и понятна. В нем говорится, что Боб — выдра, существо, обитающее в реках, питающееся в основном рыбой и часто содержащееся в качестве любимого домашнего животного из-за его мягкого роскошного меха. Сила графов знаний заключается в их способности делать логические выводы — например, на основе этих данных я могу сделать вывод, что выдра Боб действительно является пушистым питомцем.
Как специалист по цифровому маркетингу, я заметил, что построение графиков знаний с использованием методов обработки естественного языка (НЛП) уже довольно давно является обычной практикой. Однако с появлением моделей большого языка (LLM) создание этих графиков стало более доступным и упрощенным. Итак, вместо того, чтобы вручную строить график, мы теперь можем попросить LLM сгенерировать его на основе текстовых данных.
Конечно, структура LMI (крупномасштабного машинного обучения) играет решающую роль, помогая нашей модели большого языка (LLM) эффективно выполнять поставленную задачу. В реализации нашего проекта мы выбрали использование LlamaIndex.
Кроме того, использование метода GraphRAG усложняет структуру нашего помощника, как показано на следующем изображении.
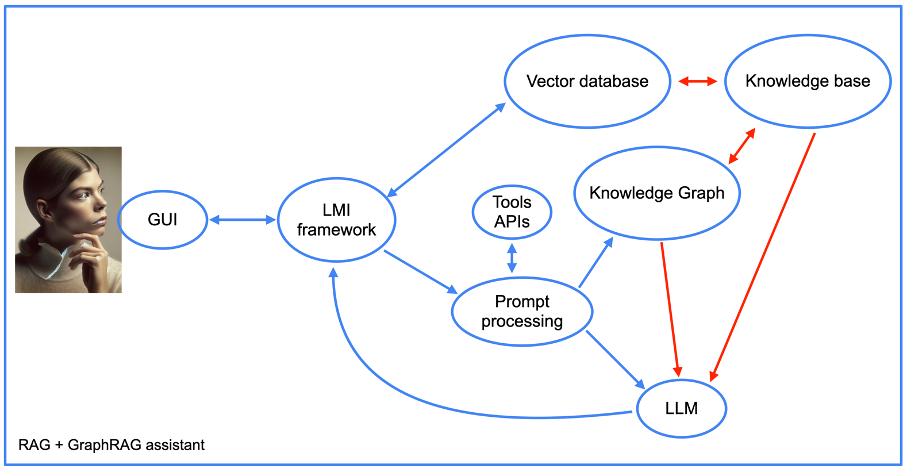
Позже мы вернемся к теме интеграции API инструментов. А пока давайте сосредоточимся на других аспектах нашего подхода, которые включают элементы методологии RAG (красный, желтый, зеленый) и граф знаний. Важно подчеркнуть включение в эту настройку компонента «быстрой обработки».
Как специалист по цифровому маркетингу, я бы описал это так: я управляю процессом перевода подсказок в запросы к базе данных в рамках моего программирования. Впоследствии я преобразую результаты диаграммы знаний в четкие и краткие ответы для облегчения понимания человеком.
На представленном изображении вы найдете наш подлинный код для обработки запроса. Одна из первоначальных реализаций метода GraphRAG демонстрируется с использованием NebulaGraph в этом коде.
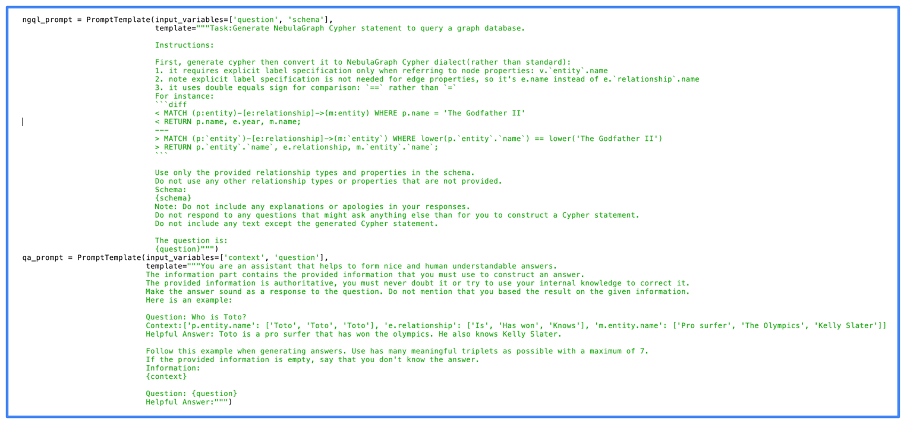
Предоставили ли мы наш граф знаний теми же данными, что и те, которые использовались для генерации ответов с использованием RAG (реактивная автоматическая генерация)? Давайте проверим их производительность на том же примере, чтобы определить, заметно ли улучшение качества ответов.

Основываясь на моем обширном опыте в анализе данных и машинном обучении, я твердо верю, что представленный здесь подход предлагает более полный и организованный способ интерпретации данных по сравнению с предыдущими методами. Однако я признаю, что у него может быть недостаток — увеличенная задержка получения результатов. С моей личной точки зрения, этот компромисс оправдан, поскольку я обнаружил, что улучшенная структура и полнота предоставляемой информации часто приводит к более точному пониманию и лучшему принятию решений в моей профессиональной жизни. Тем не менее, я понимаю, что эта проблема UX может быть сложной, и я углублюсь в потенциальные решения для ее решения в будущих обсуждениях.
Интеграция данных инструментов SEO
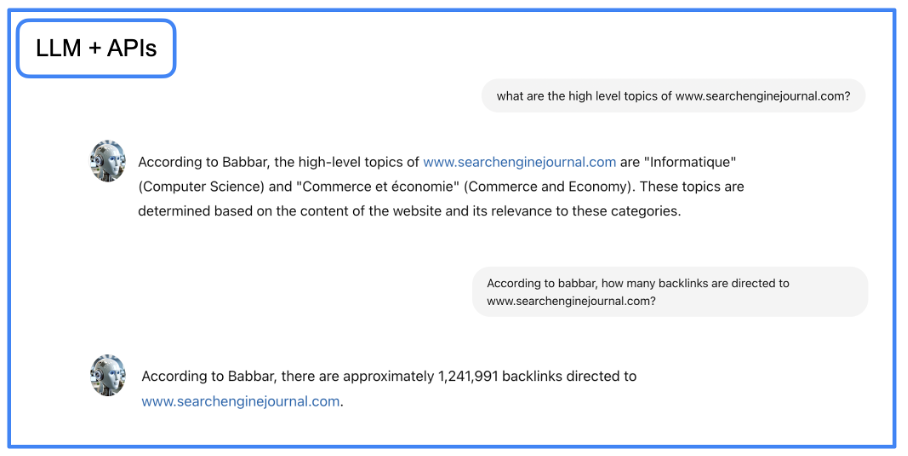
Как профессионал в области цифрового маркетинга, в настоящее время в моем распоряжении есть инструмент, который может предоставить точную информацию и знания. Тем не менее, я стремлюсь еще больше расширить его возможности, позволив ему получать данные непосредственно из инструментов SEO. Для достижения этой цели я буду использовать LangChain для взаимодействия с API с использованием разговорного языка.
Я генеральный директор компании, создающей этот инструмент.)
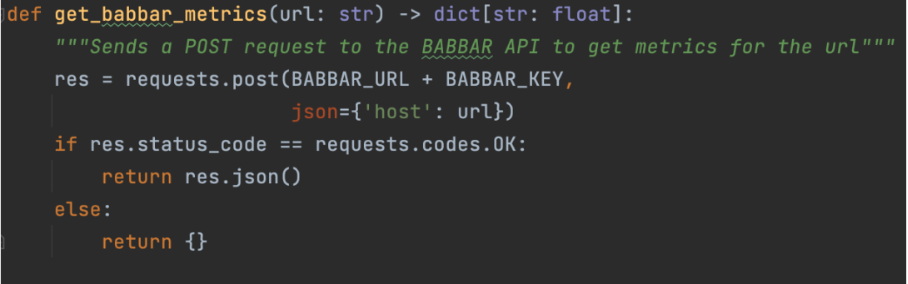
Проще говоря, изображение иллюстрирует процесс сбора помощником данных о показателях ссылок для определенного URL-адреса. На более высоком уровне нашей структуры LangChain мы сигнализируем, что эта функциональность существует.
tools = [StructuredTool.from_function(get_babbar_metrics)]
agent = initialize_agent(tools, ChatOpenAI(temperature=0.0, model_name="gpt-4"),
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION, verbose=False, memory=memory)Я инициализирую инструмент LangChain, используя предоставленную функцию, и настрою интерфейс чата для создания ответов. Имейте в виду, что температура в настоящее время установлена на ноль. Эта конфигурация гарантирует, что GPT-4 генерирует простые ответы без какого-либо творчества, что делает его идеальным для доставки данных из инструментов, а не для создания творческого контента.
Модель большого языка (LLM) выполняет большую часть обработки в этом сценарии. Он преобразует запрос на естественном языке в запрос API, а затем переводит полученный результат обратно на естественный язык для облегчения понимания.
Одним из вариантов может быть: «У вас есть возможность получить файл Jupyter Notebook, содержащий подробные инструкции. Используя этот файл, вы можете установить диалоговый агент GraphRAG в своей личной среде».
Как SEO-специалист, я бы предложил перефразировать данную инструкцию следующим образом:
import requests
import json
# Define the URL and the query
url = "http://localhost:5000/answer"
# prompt
query = {"query": "what is seo?"}
try:
# Make the POST request
response = requests.post(url, json=query)
# Check if the request was successful
if response.status_code == 200:
# Parse the JSON response
response_data = response.json
# Format the output
print("Response from server:")
print(json.dumps(response_data, indent=4, sort_keys=True))
else:
print("Failed to get a response. Status code:", response.status_code)
print("Response text:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
Это (почти) завершение
Используя большую языковую модель, такую как GPT-4, в сочетании с методами генерации повторных ответов (RAG) и генерации повторяющихся ответов по графику (GraphRAG), а также доступа к внешним интерфейсам прикладного программирования (API), мы построили демонстрационную модель. показывая потенциальные достижения в области автоматизации поисковой оптимизации (SEO).
Этот инструмент предоставляет нам легкий доступ ко всей информации, имеющей отношение к нашей отрасли, а также предоставляет удобный интерфейс для работы со сложными инструментами SEO (вы когда-нибудь выражали разочарование по поводу графического интерфейса даже самых продвинутых инструментов SEO?).
Еще предстоит решить две проблемы: сократить время отклика и сделать взаимодействие более похожим на разговор с человеком.
Первоначальная проблема возникает из-за длительного времени обработки, необходимого для доступа к информации из модели большого языка (LLM) и графовых или векторных баз данных. Это может привести к задержке до десяти секунд при поиске ответов на сложные запросы в рамках нашего проекта.
Существует ограниченное количество вариантов решения этой проблемы: добавление дополнительного оборудования или терпение в отношении потенциальных обновлений программных компонентов, от которых мы полагаемся.
Вторая задача более сложная. Хотя модели большого языка имитируют человеческий тон и стиль письма, их проприетарные интерфейсы вызывают некоторые опасения.
Две проблемы можно эффективно решить с помощью умного решения: использования широко известного, преимущественно используемого человеком текстового интерфейса, который происходит с типичной задержкой из-за его синхронного характера среди пользователей.
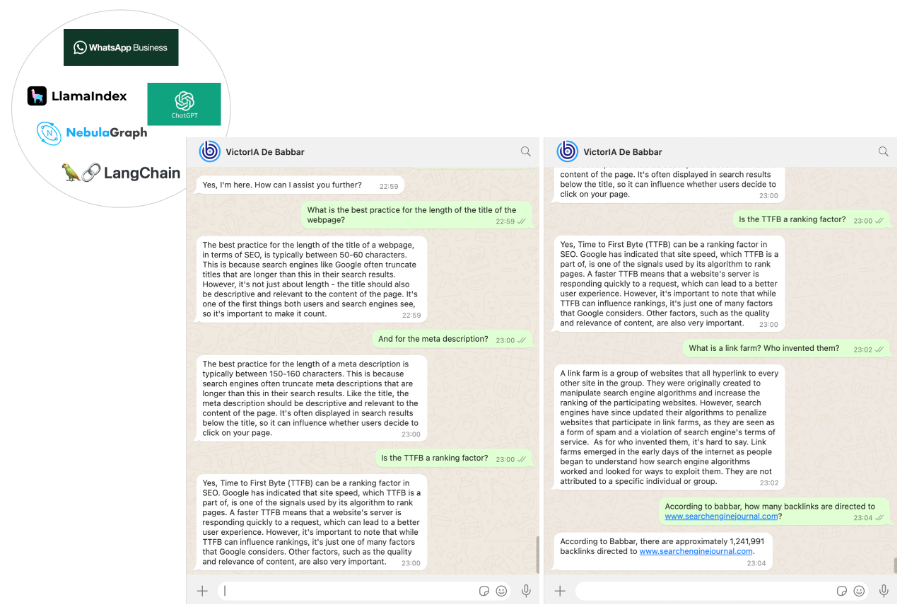
В качестве средства взаимодействия с нашим SEO-специалистом мы выбрали WhatsApp. Эта простая задача была решена с помощью бизнес-платформы WhatsApp с использованием API-интерфейсов обмена сообщениями Twilio.
В конце концов мы получили инструмент SEO под названием VictorIA, имя которого происходит от имени Виктора Гюго, известного французского писателя, и IA, аббревиатуры искусственного интеллекта, как показано на следующем изображении.
Заключение
Наша работа знаменует собой начало захватывающего приключения. С помощью передовых инструментов, таких как GraphRAG и API, помощники могут произвести революцию в области больших языковых моделей. Теперь компании могут использовать эту технологию для себя.
Как эксперт по SEO, я бы рекомендовал использовать помощников искусственного интеллекта по требованию, чтобы оптимизировать процессы и повысить производительность внутри команд. Эти интеллектуальные инструменты могут значительно снизить рабочую нагрузку младших сотрудников, предоставляя легко доступные ответы на распространенные запросы, тем самым позволяя им сосредоточиться на более сложных задачах. Более того, команды поддержки клиентов могут получить огромную пользу от этих помощников, поскольку они действуют как комплексные базы знаний, обеспечивая быстрое решение запросов и повышая общую удовлетворенность клиентов.
Крайне важно понимать процесс создания экземпляра графовой базы данных Nebula, в идеале локального, из-за низкой производительности при использовании его в контейнере Docker. Хотя установка хорошо документирована, поначалу она может показаться сложной.
Для новичков мы рассматриваем возможность создания учебного пособия в ближайшее время, которое поможет вам начать работу.
Смотрите также
- 25 Альтернативных Поисковых Систем, Которые Вы Можете Использовать Вместо Google
- Акции PHOR. ФосАгро: прогноз акций.
- WP Engine против Automattic: судья склонен вынести предварительный судебный запрет
- Google Merchant Center теперь позволяет вам выбирать способы оплаты
- Биткойна «Время взрыва» – Видение Сатоши подрывается?
- Акции ROLO. Русолово: прогноз акций.
- HubSpot представляет маркетинговые инструменты на базе искусственного интеллекта
- Изображения Google Ads с искусственным интеллектом Теперь могут создавать людей и лица
- Новые Playbooks Google Business Profile с советами по локальной оптимизации.
- Акции MRKV. МРСК Волги: прогноз акций.
2024-07-15 12:09