

Как опытный профессионал в области SEO с более чем десятилетним опытом работы за плечами, я могу с уверенностью сказать, что скромный файл robots.txt — это мощный, но часто упускаемый из виду инструмент в нашем цифровом арсенале. За время своего путешествия я видел бесчисленное количество веб-сайтов, которые либо процветали, либо терпели неудачу в зависимости от того, как они использовали этот простой текстовый файл.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Поскольку файл Robots.txt отмечает свое 30-летие, он ставит под сомнение свою значимость на фоне современного искусственного интеллекта и передовых технологий поиска. Примерно так же, как человек, которому исполнилось 30 лет, может задуматься о своей значимости в быстро меняющемся мире.
Спойлер: это определенно так!
Давайте рассмотрим решающую роль, которую этот файл играет в контроле над тем, как поисковые системы просматривают ваш веб-сайт, изучим эффективные способы его использования и определим типичные ошибки, которых следует избегать.
Что такое файл robots.txt?
Файл robots.txt во многом похож на путеводитель или карту у входа в музей, предлагая указания веб-сканерам, таким как Googlebot и Bingbot, при навигации по вашему сайту. Он представляет собой четкий набор инструкций в начале веб-сайта, подробно описывающий области, которые следует изучить или избегать, включая информацию о:
- Каким сканерам разрешен/не разрешен вход?
- Любые ограниченные области (страницы), которые не следует сканировать.
- Приоритетные страницы для сканирования – через XML-объявление карты сайта.
Основная функция — контролировать доступ веб-сканеров к определенным разделам веб-сайта, определяя недоступные области. Благодаря этому сканеры отдают приоритет ценному контенту над менее важным, тем самым экономя краулинговый бюджет.
Что касается файла robots.txt, стоит отметить, что, хотя он и служит руководством для веб-сканеров, не каждый бот соблюдает его правила, особенно вредные или вредоносные. Однако большинство авторитетных поисковых систем считают своей стандартной процедурой следование рекомендациям, установленным в файле robots.txt.
Что содержится в файле robots.txt?
Файлы Robots.txt состоят из строк директив для сканеров поисковых систем и других ботов.
Допустимые строки в файле robots.txt состоят из поля, двоеточия и значения.
Помимо стандартных правил, файлы Robots.txt часто содержат пустые строки для удобства чтения, а также примечания и комментарии, помогающие администраторам веб-сайтов более эффективно управлять своими инструкциями.

Чтобы лучше понять общие элементы файла robots.txt и то, как его используют различные веб-сайты, я изучил файлы robots.txt из 60 популярных доменов, охватывающих такие сектора, как здравоохранение, финансы, розничная торговля и технологии.
Без учета комментариев и пустых строк среднее количество строк в 60 файлах robots.txt составило 152.
Вообще говоря, веб-сайты, принадлежащие крупным издателям или агрегаторам, таким как Hotels.com, forbes.com и nytimes.com, как правило, имеют относительно длинные файлы robots.txt. С другой стороны, веб-сайты, связанные с больницами, такие как pennmedicine.org и hopkinsmedicine.com, обычно имеют более короткие адреса. Файлы robots.txt розничных сайтов обычно имеют средний размер примерно 152 слова.
Проверив все веб-сайты, мы обнаружили, что каждый из них содержит поля «user-agent» и «disallow» в документах robots.txt, и примерно 77% этих сайтов также содержат декларацию «sitemap».
Реже использовались поля, известные как «allow» (используются примерно на 60 % веб-сайтов) и «crawl-delay» (используются примерно на 20 % веб-сайтов). .
| Поле | % сайтов, использующих |
пользовательский агент |
100% |
запретить |
100% |
карта сайта |
77% |
разрешить |
60% |
задержка сканирования |
20% |
Синтаксис файла Robots.txt
После объяснения различных разделов файла robots.txt давайте углубимся в понимание их значения и того, как они эффективно применяются.
Чтобы узнать о правильном синтаксисе файлов robots.txt и о том, как Google их интерпретирует, ознакомьтесь с руководством Google по использованию robots.txt.
Пользовательский агент
Проще говоря, поле «user-agent» определяет, для какого сканера или бота поисковой системы предназначены данные директивы (например, «disallow», «allow»). Вы можете настроить свои правила для конкретных ботов/сканеров, используя поле «user-agent», или использовать подстановочный знак, чтобы применить правила ко всем сканерам в целом.
Например, приведенный ниже синтаксис указывает, что любая из следующих директив применима только к роботу Googlebot.
пользовательский агент: Googlebot
При формировании правил, которые должны быть применимы ко всем веб-сканерам, вместо указания конкретного из них более эффективно использовать подстановочный знак.
пользовательский агент: *
В файл robots.txt вы можете вставить несколько строк User-Agent, чтобы установить уникальные рекомендации для различных веб-сканеров или кластеров сканеров. Вот пример:
пользовательский агент: *
#Правила здесь будут применяться ко всем сканерам
пользовательский агент: Googlebot
#Правила здесь применимы только к роботу Google
пользовательский агент:otherbot1
пользовательский агент:otherbot2
пользовательский агент:otherbot3
#Правила здесь будут применяться к другимботам1, другимботам2 и другимботам3
Запретить и разрешить
Проще говоря, раздел «запретить» ограничивает доступ к определенным путям для определенных веб-сканеров. И наоборот, раздел «Разрешить» предоставляет доступ к определенным путям для тех же веб-сканеров.
Чтобы сделать ситуацию более понятной для поисковых роботов, таких как Googlebot, которые считают доступными любые URL-адреса, не заблокированные явно, многие веб-сайты упрощают свои правила, указывая только запрещенные пути, используя директиву `disallow`. .
В качестве помощника, например, следующий синтаксис служит сигналом для всех веб-сканеров, предлагая им избегать посещения URL-адресов, соответствующих шаблону «/no-entry».
пользовательский агент: *
запретить: /do-not-enter
#Всем сканерам запрещено сканировать страницы с путем /do-not-enter
При использовании директив «allow» и «disallow» в файле robots.txt крайне важно ознакомиться с последовательностью приоритетов правил, изложенной в руководстве Google.
Как правило, в случае противоречивых правил Google будет использовать более конкретное правило.
В этой ситуации страницы, расположенные по адресу /do-not-enter, не будут проверяться Google, поскольку определенное правило «запретить» имеет приоритет над общим правилом «разрешить».
пользовательский агент: *
разрешить: /
запретить: /do-not-enter
Если ни одно из правил не является более конкретным, Google по умолчанию будет использовать менее строгое правило.
В ситуациях, когда доступ к странице возможен по пути /do-not-enter, Google может сделать это, поскольку правило «разрешить» является более разрешающим по сравнению с правилом «запретить».
пользовательский агент: *
разрешить: /do-not-enter
запретить: /do-not-enter
Обратите внимание: если в полях allow или disallow не указан путь, правило будет игнорироваться.
пользовательский агент: *
запретить:
Вместо того, чтобы просто использовать косую черту («/») в качестве значения поля «disallow», это позволит ему соответствовать только основному домену и всем подстраницам вашего веб-сайта.
Чтобы ваш веб-сайт появлялся в результатах поисковых систем, избегайте включения этого конкретного кода, поскольку он не позволяет всем поисковым системам получать доступ и индексировать каждую страницу вашего сайта.
пользовательский агент: *
запретить: /
Это может показаться очевидным, но поверьте мне, я видел, как это происходило.
URL-пути
//www.example.com/guides/technical/robots-txt, путь будет /guides/technical/robots-txt. Эта часть URL-адреса помогает перемещаться по определенным разделам или ресурсам веб-сайта.

Чтобы обеспечить правильную работу файла robots.txt, всегда проверяйте, соответствуют ли символы верхнего и нижнего регистра конкретному URL-пути, который вы собираетесь использовать. Другими словами, убедитесь, что слова «Робот» и «робот» не имеют разных значений для желаемого URL-адреса.
Специальные символы
Поисковые платформы, такие как Google, Bing и другие, позволяют использовать определенные уникальные символы для сопоставления URL-адресов, хотя и с некоторыми ограничениями.
Как опытный веб-мастер, я хотел бы подчеркнуть, что специальные символы — это не обычные буквы или цифры; они выполняют уникальные функции или имеют определенное значение. В контексте файла robots.txt Google это специальные символы, о которых нам следует знать:
- Звездочка (*) – соответствует 0 или более экземплярам любого символа.
- Знак доллара ($) – обозначает конец URL-адреса.
Чтобы проиллюстрировать, как работают эти уникальные символы, рассмотрим простой веб-сайт со следующей структурой URL-адресов:
- https://www.example.com/
- https://www.example.com/search
- https://www.example.com/guides
- https://www.example.com/guides/technical
- https://www.example.com/guides/technical/robots-txt
- https://www.example.com/guides/technical/robots-txt.pdf
- https://www.example.com/guides/technical/xml-sitemaps
- https://www.example.com/guides/technical/xml-sitemaps.pdf
- https://www.example.com/guides/content
- https://www.example.com/guides/content/on-page-optimization
- https://www.example.com/guides/content/on-page-optimization.pdf
Пример сценария 1. Блокировка результатов поиска по сайту
Одним из частых применений файла robots.txt является исключение результатов внутреннего поиска по сайту из сканирования роботами поисковых систем, поскольку такие страницы обычно не способствуют естественному или органическому рейтингу в поиске.
В этом сценарии, если пользователь выполняет поиск по адресу https://www.example.com/search, введенный им поисковый запрос добавляется непосредственно к URL-адресу.
Как эксперт по SEO, я хотел бы уточнить: когда вы определяете URL-путь в файле robots.txt, он соответствует не только точному URL-адресу, но и всем URL-адресам, разделяющим этот конкретный путь. Другими словами, если вы хотите запретить доступ к определенным URL-адресам, вам не всегда нужно использовать для этой цели подстановочный знак.
Следующее правило будет соответствовать как https://www.example.com/search, так и https://www.example.com/search?search-query=xml-sitemap-guide.
пользовательский агент: *
запретить: /search
#Всем сканерам запрещено сканировать страницы с путем /search
Если бы был добавлен подстановочный знак (*), результаты были бы такими же.
пользовательский агент: *
запретить: /search*
#Всем сканерам запрещено сканировать страницы с путем /search
Пример сценария 2. Блокировка PDF-файлов
В некоторых случаях вы можете использовать файл robots.txt для блокировки определенных типов файлов.
Рассмотрим сценарий, в котором веб-сайт решает создать PDF-файлы для каждого руководства, чтобы пользователям было проще распечатывать его. В результате этого действия появляются два URL-адреса, содержащие одинаковое содержимое. Поскольку владелец веб-сайта не хочет, чтобы поисковые системы индексировали эти версии PDF, он может рассмотреть возможность запрета веб-сканерам доступа к ним.
В этом сценарии использование подстановочного знака (*) окажется полезным, поскольку он может эффективно сопоставлять URL-адреса, которые начинаются с «/guides/» и заканчиваются «.pdf», хотя символы или символы в середине могут отличаться.
пользовательский агент: *
запретить: /guides/*.pdf
Заблокируйте всем веб-сканерам доступ к веб-страницам, URL-адреса которых включают строку «/guides/», за которой следует ноль или более символов (включая полное отсутствие символов) и заканчивается «.pdf».
Приведенная выше директива не позволит поисковым системам сканировать следующие URL-адреса:
- https://www.example.com/guides/technical/robots-txt.pdf
- https://www.example.com/guides/technical/xml-sitemaps.pdf
- https://www.example.com/guides/content/on-page-optimization.pdf
Пример сценария 3. Блокировка страниц категорий
В нашем последнем примере давайте представим, что на веб-сайте созданы страницы категорий как для технических, так и для содержательных руководств, чтобы пользователи могли легко и более эффективно перемещаться по контенту в будущем.
Тем не менее, поскольку в настоящее время доступно всего три опубликованных руководства, эти страницы не представляют существенной ценности ни для пользователей, ни для поисковых систем.
Администратор сайта может временно запретить поисковым системам сканировать только страницу категории, например эту:
Для этого мы можем использовать «$» для обозначения конца пути URL.
пользовательский агент: *
запретить: /guides/technical$
запретить: /guides/content$
Заблокируйте всем веб-сканерам доступ к веб-страницам, URL-адреса которых заканчиваются на «/guides/technical» или «/guides/content».
Приведенный выше синтаксис предотвратит сканирование следующих URL-адресов:
- https://www.example.com/guides/technical
- https://www.example.com/guides/content
Разрешая поисковым системам сканировать:
- https://www.example.com/guides/technical/robots-txt
- https://www.example.com/guides/content/on-page-optimization
Карта сайта
Поле карты сайта используется для предоставления поисковым системам ссылки на одну или несколько карт сайта XML.
Как специалист по цифровому маркетингу, я считаю полезным (хотя и не обязательным) включать карты сайта XML в свой файл robots.txt. Эта практика помогает поисковым системам легко идентифицировать и расставлять приоритеты URL-адресов, которые они должны сканировать, что делает процесс индексации более рациональным.
Чтобы обеспечить правильную работу, значение поля sitemap должно быть записано как абсолютный веб-адрес (например, https://www.example.com/sitemap.xml), а не как относительный. (например, /sitemap.xml). Если у вас есть несколько карт сайта XML, не стесняйтесь включать несколько полей sitemap.
Пример файла robots.txt с одной XML-картой сайта:
пользовательский агент: *
запретить: /do-not-enter
карта сайта: https://www.example.com/sitemap.xml
Пример файла robots.txt с несколькими XML-картами сайта:
пользовательский агент: *
запретить: /do-not-enter
карта сайта: https://www.example.com/sitemap-1.xml
карта сайта: https://www.example.com/sitemap-2.xml
карта сайта: https://www.example.com/sitemap-3.xml
Задержка сканирования
Как упоминалось выше, 20% сайтов также включают поле crawl-delay в свой файл robots.txt.
Параметр «задержка сканирования» указывает ботам скорость, с которой они могут перемещаться по веб-сайту, обычно с целью снижения скорости сканирования и предотвращения перегрузки сервера.
Проще говоря, число, присвоенное параметру «crawl-delay», задает время в секундах, в течение которого роботы поисковых систем (или сканеры) должны делать паузу между запросами новой веб-страницы. Уточним: если это правило установлено, оно предписывает указанному сканеру ждать пять секунд после каждого запроса, прежде чем перейти к другому URL-адресу.
пользовательский агент: FastCrawlingBot
задержка сканирования: 5
Google заявил, что не поддерживает поле crawl-delay и оно будет проигнорировано.
Как опытный специалист по SEO, я могу подтвердить, что другие известные поисковые системы, такие как Bing и Yahoo, также соблюдают инструкции по «задержке сканирования», когда дело касается операций их веб-сканеров.
| Поисковая система | Основной пользовательский агент для поиска | Учитывает задержку сканирования? |
| Googlebot | Нет | |
| Бинг | Бингбот | Да |
| Yahoo | хлебать | Да |
| Яндекс | ЯндексБот | Да |
| Байду | Байдупаук | Нет |
Веб-сайты часто содержат инструкции, называемые директивами задержки сканирования, которые применимы ко всем типам пользователей (обозначаются подстановочным знаком *). Эти инструкции соблюдаются сканерами поисковых систем, а также упомянутыми ранее, а также специализированными инструментами SEO, такими как Ahrefbot и SemrushBot.
Число секунд, в течение которых сканерам было указано ждать перед запросом другого URL-адреса, варьировалось от одной секунды до 20 секунд, но значения crawl-delay в пять секунд и 10 секунд были наиболее распространенными на 60 проанализированных сайтах.
Тестирование файлов Robots.txt
Всякий раз, когда вы создаете или редактируете файл robots.txt, всегда дважды проверяйте инструкции, грамматику и общий макет, прежде чем публиковать его.
Инструмент проверки и тестирования robots.txt позволяет легко это сделать (спасибо, Макс Прин!).
Чтобы протестировать работающий файл robots.txt, просто:
- Добавьте URL-адрес, который хотите протестировать.
- Выберите свой пользовательский агент.
- Выберите «Жить».
- Нажмите «Проверить».
В приведенном ниже примере показано, что смартфону робота Googlebot разрешено сканировать тестируемый URL-адрес.
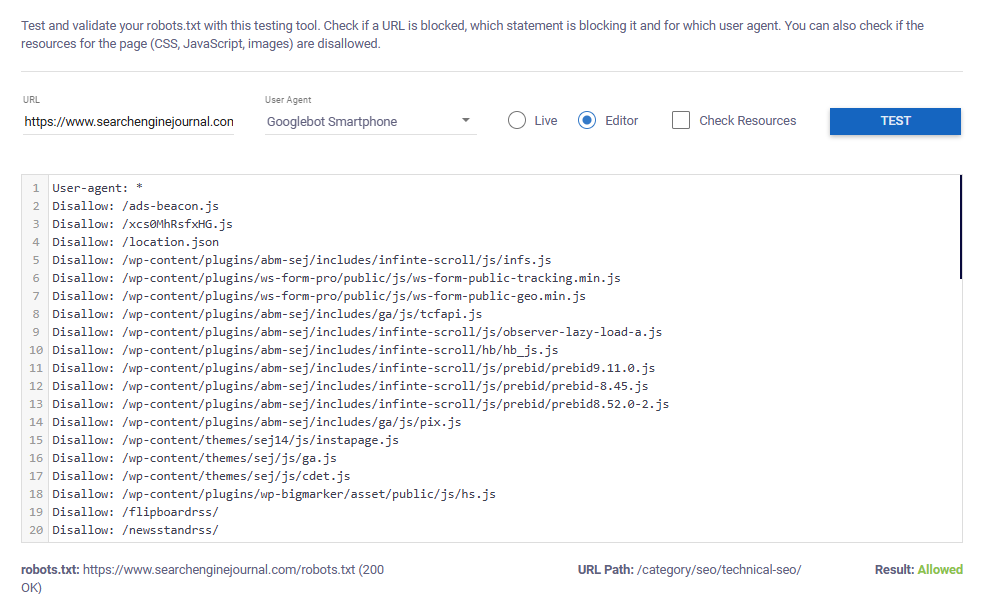
Если окажется, что предоставленный URL-адрес ограничен, инструмент определит конкретное правило, из-за которого указанный браузер не сможет получить к нему доступ.
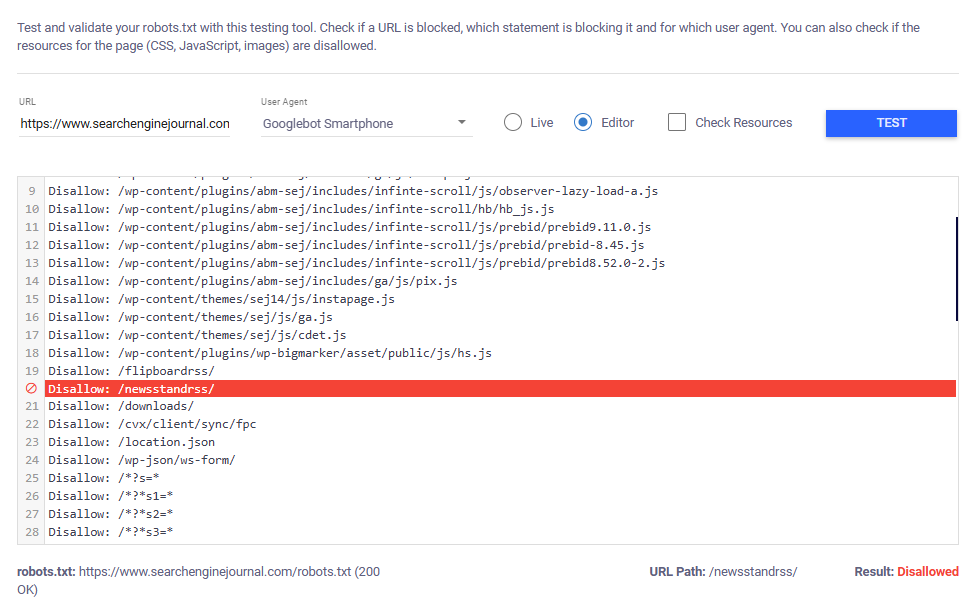
Прежде чем публиковать новые правила, попробуйте переключиться в «Режим редактирования» и сначала ввести правила в текстовую область для тестового запуска.
Общее использование файла Robots.txt
Изучение 60 различных файлов robots.txt на разных веб-сайтах показало, что, хотя их конкретное содержимое может значительно различаться, существуют некоторые закономерности в том, как они используются, и в том, какие виды контента веб-мастера часто не позволяют поисковым системам индексировать.
Запретить поисковым системам сканировать малоценный контент
На многочисленных веб-сайтах, особенно обширных, таких как сайты электронной коммерции или сайты с богатым содержанием, часто непреднамеренно создаются «страницы с минимальной ценностью» из-за функций, реализованных для улучшения взаимодействия с пользователем.
Например, страницы внутреннего поиска и возможность фильтрации и сортировки (фасетная навигация) позволяют пользователям легко и быстро найти именно то, что им нужно.
Хотя эти характеристики имеют решающее значение для удобства пользователя, они потенциально могут привести к появлению множества или менее ценных URL-адресов, которые не имеют большой ценности с точки зрения поисковых систем.
Файл robots.txt обычно используется для блокировки сканирования этих малоценных страниц.
К распространенным типам контента, блокируемого через robots.txt, относятся:
- Параметризованные URL-адреса. URL-адреса с параметрами отслеживания, идентификаторами сеансов или другими динамическими переменными блокируются, поскольку часто ведут к одному и тому же контенту, что может привести к проблемам с дублированием контента и трате бюджета сканирования. Блокировка этих URL-адресов гарантирует, что поисковые системы будут индексировать только основной, чистый URL-адрес.
- Фильтры и сортировка. Блокировка URL-адресов фильтрации и сортировки (например, страниц товаров, отсортированных по цене или категории) помогает избежать индексации нескольких версий одной и той же страницы. Это снижает риск дублирования контента и позволяет поисковым системам сосредоточиться на самой важной версии страницы.
- Результаты внутреннего поиска. Страницы результатов внутреннего поиска часто блокируются, поскольку они создают контент, не имеющий уникальной ценности. Если поисковый запрос пользователя вводится в URL-адрес, содержимое страницы и мета-элементы, сайты могут даже рискнуть просканировать и проиндексировать некоторый неуместный, созданный пользователем контент (см. образец снимка экрана Мэтта Татта в этой публикации). Их блокировка предотвращает появление этого некачественного и потенциально нежелательного контента в поиске.
- Профили пользователей. Страницы профилей могут быть заблокированы для защиты конфиденциальности, уменьшения сканирования малоценных страниц или обеспечения сосредоточения внимания на более важном контенте, например страницах продуктов или сообщениях в блогах.
- Среды тестирования, тестирования или среды разработки. Среды тестирования, разработки или тестирования часто блокируются, чтобы гарантировать, что частный контент не будет сканироваться поисковыми системами.
- Подпапки кампании. Целевые страницы, созданные для платных медиа-кампаний, часто блокируются, если они не актуальны для более широкой поисковой аудитории (например, целевая страница прямой почтовой рассылки, предлагающая пользователям ввести код активации). .
- Страницы оформления заказа и подтверждения. Страницы оформления заказа блокируются, чтобы пользователи не могли попасть на них напрямую через поисковые системы, что повышает удобство работы пользователей и защищает конфиденциальную информацию в процессе транзакции.
- Созданный пользователями и спонсируемый контент. Спонсируемый контент или пользовательский контент, созданный с помощью обзоров, вопросов, комментариев и т. д., часто блокируется для сканирования поисковыми системами.
- Медиа-файлы (изображения, видео). Медиа-файлы иногда блокируются от сканирования, чтобы сэкономить полосу пропускания и уменьшить видимость проприетарного контента в поисковых системах. Это гарантирует, что в результатах поиска будут отображаться только релевантные веб-страницы, а не отдельные файлы.
- API: API часто блокируются, чтобы предотвратить их сканирование или индексирование, поскольку они предназначены для межмашинного взаимодействия, а не для результатов поиска конечных пользователей. Блокировка API защищает их использование и снижает ненужную нагрузку на сервер от ботов, пытающихся получить к ним доступ.
Блокировка «плохих» ботов
Нежелательные или вредоносные программные роботы, часто называемые плохими ботами, выполняют такие действия, как неизбирательный сбор данных (очистка контента) или поиск слабых мест с целью кражи конфиденциальной информации в серьезных ситуациях.
Боты, у которых нет вредоносных намерений, все равно могут быть помечены как «неблагоприятные», когда они бомбардируют веб-сайты чрезмерным количеством запросов, вызывая тем самым перегрузку сервера.
Более того, некоторые менеджеры веб-сайтов могут предпочесть держать определенных веб-сканеров подальше от своего сайта, поскольку они не видят никаких преимуществ от такого взаимодействия.
Например, если вы не предоставляете услуги Китаю или хотите избежать возможных сбоев в работе сервера из-за запросов Baidu, вы можете решить ограничить доступ со стороны Baidu.
Несмотря на то, что некоторые «нежелательные» боты могут игнорировать правила, изложенные в файле robots.txt, веб-сайты часто включают запреты, чтобы не допустить их попадания.
Согласно нашему анализу 60 файлов robot.txt, каждый из них содержал ограничение хотя бы для одного пользовательского агента, не позволяющее им получить доступ ко всему содержимому сайта с помощью команды «disallow: /».
Блокировка ИИ-сканеров
Среди проверенных веб-сайтов было обнаружено, что GPTBot был наиболее часто блокируемым сканером, поскольку примерно один из четырех сайтов (или 23%) не позволял GPTBot получить доступ к какому-либо своему контенту.
По состоянию на ноябрь 2024 года информационная панель Orginality.ai в режиме реального времени показывает, что примерно четверть (27%) из 1000 крупнейших веб-сайтов приняли меры, предотвращающие их сканирование GPTBot.
Возможные причины ограничения веб-скраперов ИИ варьируются от беспокойства по поводу управления данными и личной конфиденциальности до желания предотвратить использование своих данных в системах обучения ИИ без соответствующего вознаграждения.
Каждая ситуация требует индивидуальной оценки при определении необходимости блокировки ИИ-ботов с помощью файла robots.txt.
Если вы хотите предотвратить использование контента вашего веб-сайта для обучения ИИ, сохраняя при этом максимальную видимость, вы сорвали джекпот! OpenAI четко описывает использование таких моделей, как GPTBot и другие веб-сканеры, что дает вам контроль над доступом к вашим данным.
По крайней мере, сайты могут захотеть предоставить доступ OAI-SearchBot, инструменту, используемому для демонстрации и подключения веб-сайтов к функции поиска в реальном времени SearchGPT — последнему дополнению к услугам ChatGPT.
По сравнению с блокировкой GPTBot, блокирование OAI-SearchBot встречается гораздо реже, поскольку оно наблюдается только примерно на 2,9% из 1000 крупнейших веб-сайтов, которые были созданы для препятствования работе этого конкретного сканера поисковой системы, ориентированного на SearchGPT.
Творческий подход
Помимо того, что файл robots.txt служит ключевым инструментом в управлении доступом поисковых роботов к вашему сайту, он также может предоставить веб-сайтам возможность продемонстрировать свой инновационный и художественный талант.
Просматривая документы примерно из 60 различных источников, я наткнулся на несколько неожиданных сокровищ – например, причудливые рисунки, скрытые в разделах комментариев файлов robots.txt от Marriott и Cloudflare.
Многие компании даже превращают эти файлы в уникальные инструменты для подбора персонала.
Файл robots.txt на сайте TripAdvisor также служит объявлением о вакансии с умным сообщением, включенным в комментарии:
Если вы изучаете этот документ и вы не машина, похоже, мы заинтересованы в сотрудничестве с такими людьми, как вы, которые от природы любознательны…
Управляйте, а не сканируйте, чтобы подать заявку на вступление в элитную SEO-команду TripAdvisor[.]»
Если вы ищете новую вакансию, вам будет полезно изучить файлы robots.txt, а также LinkedIn.
Как проверить файл robots.txt
Аудит файла Robots.txt является важной частью большинства технических SEO-аудитов.
Выполнение всесторонней проверки файла robots.txt гарантирует, что он правильно настроен для повышения видимости сайта, при этом избегая непреднамеренной блокировки важных веб-страниц.
Чтобы проверить файл Robots.txt:
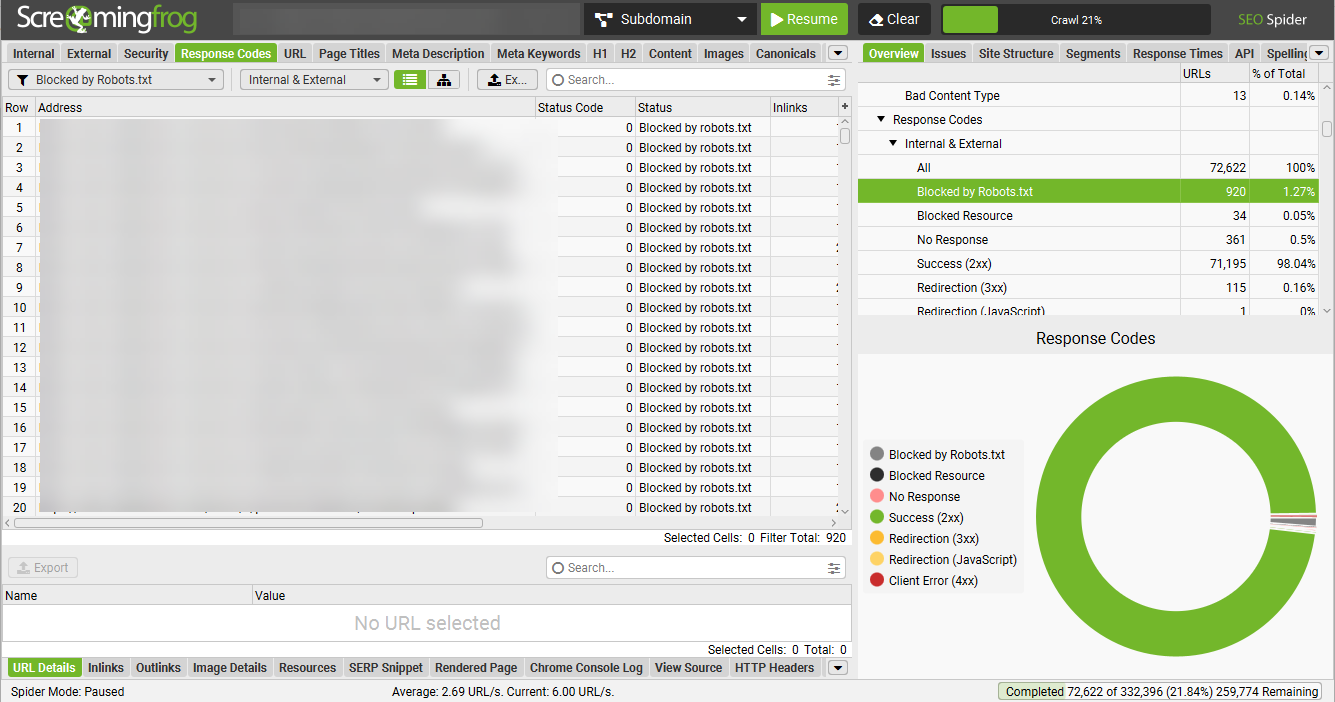
- Просканируйте сайт с помощью предпочитаемого вами сканера. (Обычно я использую Screaming Frog, но с этой задачей справится любой веб-сканер.)
- Фильтровать сканирование для всех страниц, помеченных как «заблокированные файлом robots.txt». В Screaming Frog вы можете найти эту информацию, перейдя на вкладку кодов ответов и отфильтровав ее по «заблокировано robots.txt».
- Просмотрите список URL-адресов, заблокированных файлом robots.txt, чтобы определить, следует ли их заблокировать. Обратитесь к приведенному выше списку распространенных типов контента, заблокированного файлом robots.txt, чтобы определить, должны ли заблокированные URL-адреса быть доступны поисковым системам.
- Откройте файл robots.txt и проведите дополнительные проверки, чтобы убедиться, что файл robots.txt соответствует рекомендациям SEO (и позволяет избежать распространенных ошибок), подробно описанных ниже.
Рекомендации по использованию файла robots.txt (и подводные камни, которых следует избегать)
Разумное использование файла robots.txt может принести большую пользу вашему веб-сайту, но крайне важно избегать некоторых типичных ловушек, чтобы предотвратить нежелательные, случайные повреждения.
Вот несколько рекомендуемых стратегий, которые помогут поисковым системам легко обнаружить ваш контент, избегая при этом случайной блокировки:
- Создайте файл robots.txt для каждого субдомена. Каждый субдомен вашего сайта (например, blog.yoursite.com, shop.yoursite.com) должен иметь собственный файл robots.txt для управления конкретными правилами сканирования. в этот поддомен. Поисковые системы рассматривают поддомены как отдельные сайты, поэтому уникальный файл обеспечивает надлежащий контроль над тем, какой контент сканируется или индексируется.
- Не блокируйте важные страницы сайта. Убедитесь, что приоритетный контент, например страницы продуктов и услуг, контактная информация и содержимое блога, доступен поисковым системам. Кроме того, убедитесь, что заблокированные страницы не мешают поисковым системам получать доступ к ссылкам на контент, который вы хотите сканировать и индексировать.
- Включите ссылку на карту сайта. Всегда включайте ссылку на карту сайта в файл robots.txt. Это позволяет поисковым системам более эффективно находить и сканировать ваши важные страницы.
- Не разрешайте доступ к вашему сайту только определенным ботам. Если вы запретите всем ботам сканировать ваш сайт, за исключением определенных поисковых систем, таких как Googlebot и Bingbot, вы можете непреднамеренно заблокировать ботов, которые могут принести пользу вашему сайту. Примеры ботов включают в себя:
<ул> - FacebookExtenalHit – используется для получения протокола открытого графа.
- GooglebotNews – используется для вкладки «Новости» в Google Поиске и приложении Google News.
- AdsBot-Google — используется для проверки качества рекламы на веб-странице.
- Не блокируйте URL-адреса, которые вы хотите удалить из индекса. Блокировка URL-адреса в файле robots.txt не позволяет поисковым системам только сканировать его, но не индексировать, если URL-адрес уже известен. Чтобы удалить страницы из индекса, используйте другие методы, такие как тег «noindex» или инструменты удаления URL-адресов, гарантируя, что они должным образом исключены из результатов поиска.
- Не запрещайте Google и другим крупным поисковым системам сканировать весь ваш сайт. Просто не делайте этого.
TL;DR
- Файл robots.txt указывает сканерам поисковых систем, к каким областям веб-сайта следует обращаться или избегать, оптимизируя эффективность сканирования за счет сосредоточения внимания на наиболее ценных страницах.
- Ключевые поля включают «Агент пользователя» для указания целевого сканера, «Запретить» для областей с ограниченным доступом и «Карта сайта» для приоритетных страниц. Файл также может содержать такие директивы, как «Разрешить» и «Задержка сканирования».
- Веб-сайты обычно используют robots.txt для блокировки результатов внутреннего поиска, малоценных страниц (например, фильтров, параметров сортировки) или конфиденциальных областей, таких как страницы оформления заказа и API.
- Чтобы ваш сайт был успешным, убедитесь, что у каждого поддомена есть собственный файл robots.txt, проверьте директивы перед публикацией, включите декларацию карты сайта XML и избегайте случайной блокировки ключевого контента.
Смотрите также
- Акции PHOR. ФосАгро: прогноз акций.
- Акции MRKV. МРСК Волги: прогноз акций.
- Важные функции поисковой выдачи торговой площадки Google
- Акции VKCO. ВК: прогноз акций.
- Акции NVTK. НОВАТЭК: прогноз акций.
- Акции RENI. Ренессанс Страхование: прогноз акций.
- 11 лучших бесплатных и платных курсов по цифровому маркетингу (2024 г.)
- Google: нДВУ и язык помогают вам повысить рейтинг в местном регионе страны
- Показатели видеорекламы и реклама бренда с Грегом Джарбо
- Обзоры искусственного интеллекта Google Отказ от Reddit и использование YouTube [исследование]
2024-11-27 14:10