

Как опытный цифровой маркетолог с более чем десятилетним опытом работы за плечами, я могу подтвердить преобразующую силу искусственного интеллекта и машинного обучения в сфере SEO. Возможность использовать эти инструменты для анализа и оптимизации контента для повышения рейтинга в поисковых системах является не чем иным, как революцией.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)В своем собственном путешествии я воочию видел, как интеграция ИИ помогла мне точно настроить мою контент-стратегию и оставаться на шаг впереди. Процесс создания векторных вложений ключевых слов, вычисления косинусного сходства и оптимизации релевантности стал важной частью моего рабочего процесса.
Я помню время, когда мне приходилось полагаться на догадки и интуицию, чтобы оптимизировать свой контент, но теперь с искусственным интеллектом я могу принимать решения на основе данных, которые приводят к ощутимым результатам. Это похоже на хрустальный шар, который помогает мне увидеть будущее SEO и соответствующим образом адаптировать свои стратегии.
Теперь я призываю вас глубоко погрузиться в этот захватывающий мир SEO, основанного на искусственном интеллекте. Не бойтесь экспериментировать с различными инструментами и техниками и не бойтесь совершать ошибки – они всего лишь ступеньки на вашем пути к мастерству. И помните, лучший способ оставаться впереди в этой быстро развивающейся отрасли — продолжать учиться и адаптироваться к постоянно меняющемуся ландшафту AI SEO.
Да, и еще кое-что: если вы чувствуете себя растерянным, не волнуйтесь — однажды я часами пытался придумать, как приготовить сэндвич с арахисовым маслом и желе, используя только вилку. Так что поверьте мне, когда я говорю, что упорством и чувством юмора можно победить все!
База данных векторов представляет собой набор информации, в котором каждый элемент данных сохраняется в виде числового вектора. Проще говоря, этот вектор служит представлением различных объектов или сущностей, таких как изображения, люди, местоположения и т. д., в концептуальном многомерном пространстве.
Проще говоря, векторы, о которых мы узнали ранее, играют значительную роль в понимании связей между различными сущностями. Они помогают нам определить семантическое сходство этих сущностей. Например, в контексте поисковой оптимизации (SEO) эту концепцию можно эффективно использовать. Например, вы можете классифицировать связанные ключевые слова или контент с помощью алгоритма kNN (k-ближайших соседей).
В этой статье мы рассмотрим некоторые стратегии интеграции ИИ в SEO. Например, один из методов включает в себя идентификацию связанного контента для внутренних ссылок, что может улучшить ваш подход к контенту, поскольку поисковые системы теперь сильно зависят от моделей изучения языка (LLM).
Как специалист по цифровому маркетингу, я хотел бы поделиться тем, что вы могли бы изучить соответствующую статью из нашей серии, в которой рассматривается использование встраивания текста OpenAI для выявления каннибализации ключевых слов — распространенной проблемы в SEO.
Давайте углубимся сюда, чтобы начать создавать основу нашего инструмента.
Понимание векторных баз данных
Если у вас есть тысячи статей и вы хотите найти максимальное семантическое сходство для вашего целевого запроса, вы не можете создавать векторные вложения для всех из них на лету для сравнения, поскольку это крайне неэффективно.
Чтобы это произошло, нам нужно будет сгенерировать векторные вложения только один раз и сохранить их в базе данных, которую мы сможем запросить и найти наиболее подходящую статью.
Проще говоря, векторные базы данных — это особый тип базы данных, предназначенный для хранения вложений, которые представляют собой числовые представления или векторы данных.
Когда вы запрашиваете базу данных, в отличие от традиционных баз данных, они выполняют сопоставление по косинусному сходству и возвращают векторы (в данном случае статьи), ближайшие к другому запрашиваемому вектору (в данном случае ключевой фразе).
Вот как это выглядит:
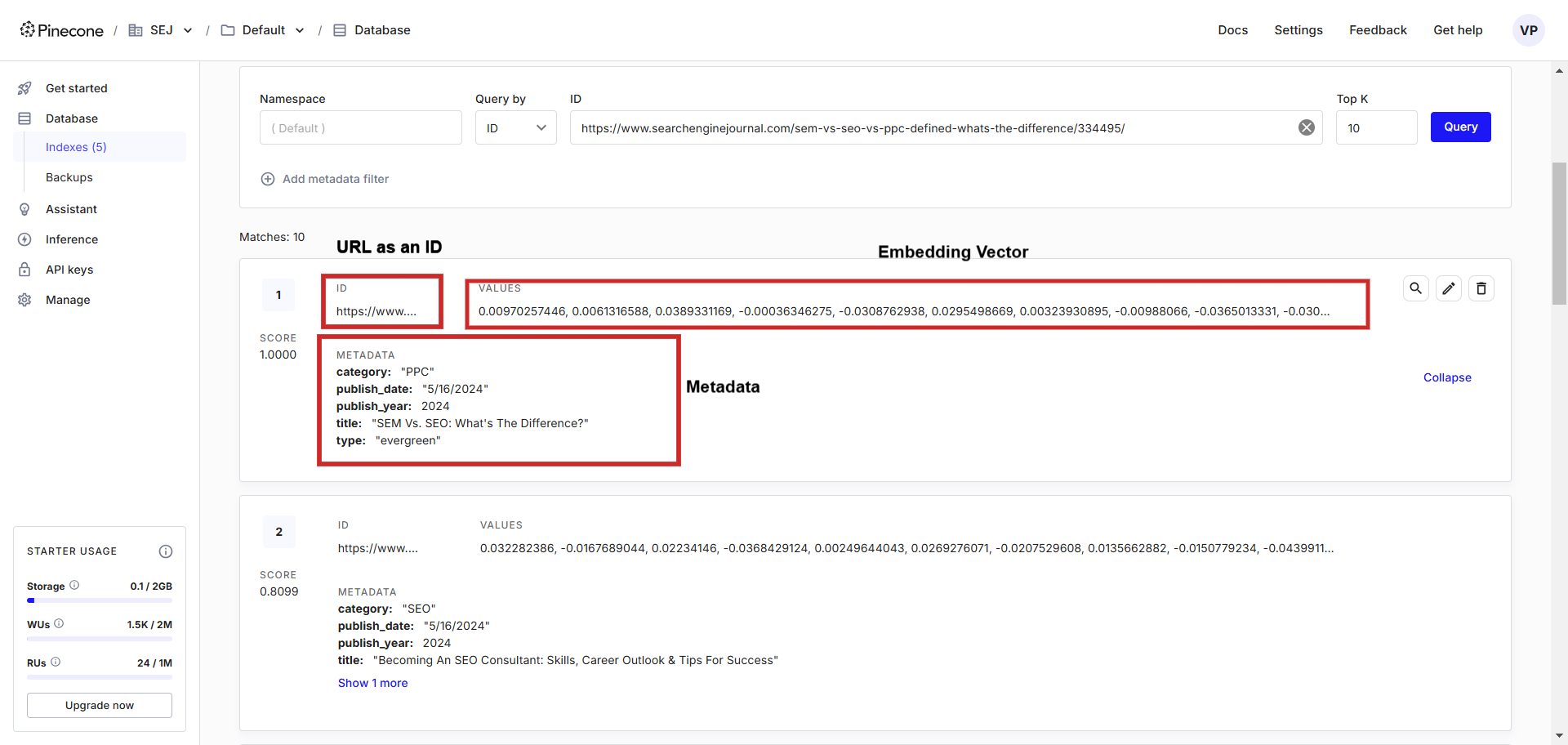
В этой базе данных векторов вы обнаружите, что векторы хранятся вместе со связанными с ними метаданными. Эти метаданные можно быстро получить, написав запросы на любом языке программирования, который вы предпочитаете.
В этой статье мы в первую очередь сосредоточимся на сосновой шишке из-за ее удобства в использовании и простоты обращения; однако стоит также изучить альтернативных поставщиков услуг, таких как Chroma, BigQuery или Qdrant.
Давайте погрузимся.
1. Создайте базу данных векторов.
Сначала зарегистрируйте учетную запись в Pinecone и создайте индекс с конфигурацией «text-embedding-ada-002» с «косинусом» в качестве метрики для измерения векторного расстояния. Вы можете назвать индекс как угодно, мы назовем его article-index-all-ada’.
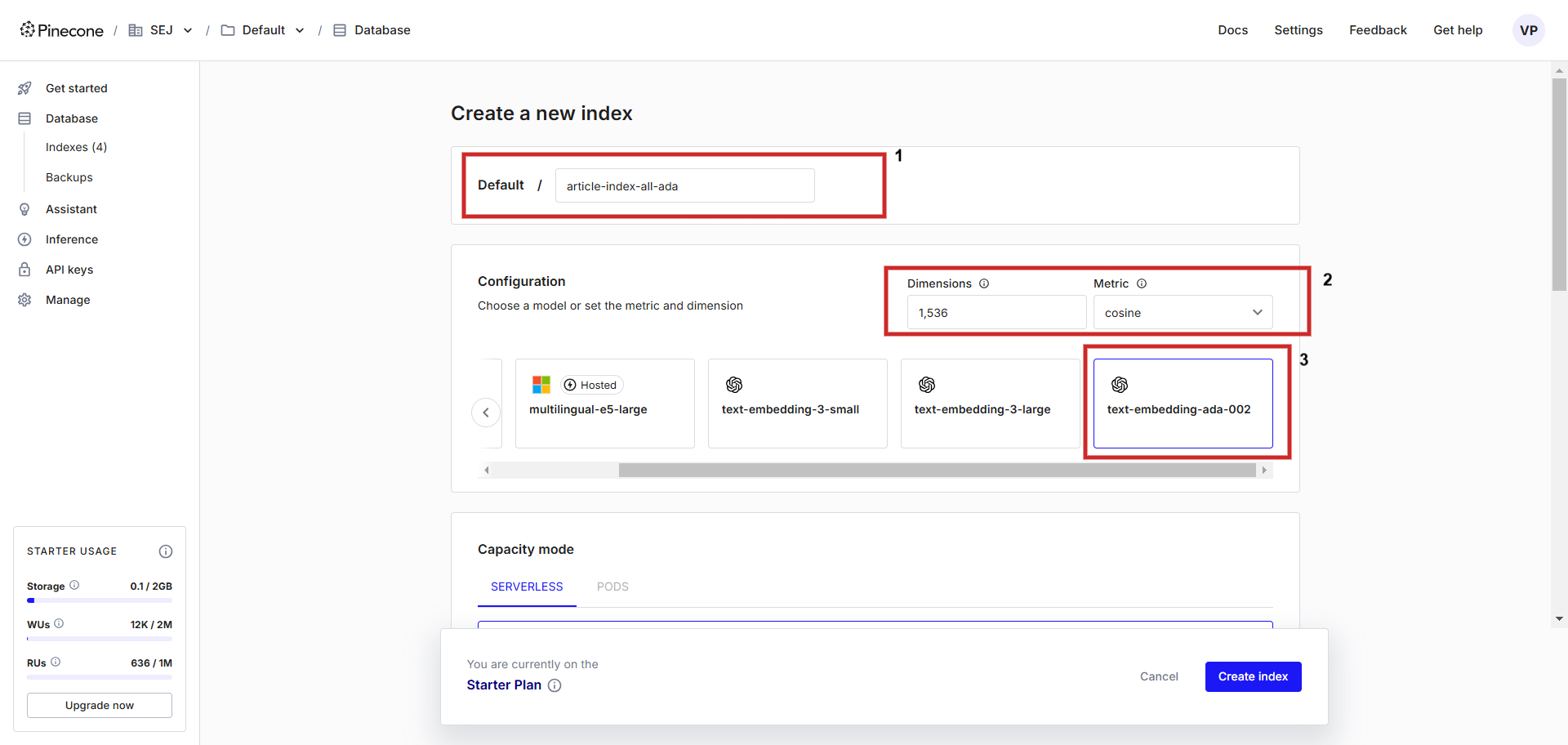
Как опытный пользователь с многолетним опытом за плечами, я должен подчеркнуть важность понимания процесса настройки при работе с продвинутыми инструментами, такими как векторное встраивание Vertex AI. В своем путешествии я встречал бесчисленное количество случаев, когда, казалось бы, простой шаг настройки имел решающее значение для обеспечения бесперебойной работы и оптимальной производительности.
В этом случае, если вы хотите сохранить векторные внедрения Vertex AI, необходимо вручную настроить значение «размеров» на экране конфигурации на 768. Эта настройка имеет решающее значение, поскольку она соответствует размерности Vertex AI по умолчанию, обеспечивая совместимость и точность.
Кроме того, если важна экономия памяти, вы можете установить значение размера в диапазоне от 1 до 768. Имейте в виду, что более низкие значения будут потреблять меньше памяти, но могут повлиять на производительность или точность.
Помните, что если вы потратите время на выполнение этих инструкций во время установки, это поможет вам сэкономить драгоценное время и ресурсы в дальнейшем. Приятного кодирования!
В этом посте мы покажем вам процесс использования «text-embedding-ada-002» от OpenAI и «text-embedding-005 от Google» для задач обработки текста.
После ее создания необходимо иметь ключ API для установления соединения с базой данных векторов через определенный URL-адрес, который служит хостом.
Исходя из моего личного опыта работы с данными, я настоятельно рекомендую использовать Jupyter Notebook для ваших проектов. Если он еще не установлен на вашем компьютере, не волнуйтесь! Я проведу вас через процесс установки. Сначала следуйте этому руководству, чтобы установить Jupyter Notebook. После настройки откройте терминал вашего ПК и вставьте следующую команду, чтобы установить все необходимые пакеты:
[Команда здесь]
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpyИ помните, ChatGPT очень полезен, когда вы сталкиваетесь с проблемами во время кодирования!
2. Экспортируйте свои статьи из вашей CMS.
Далее нам нужно подготовить CSV-файл экспорта статей из вашей CMS. Если вы используете WordPress, вы можете использовать плагин для индивидуального экспорта.
Чтобы достичь нашей основной цели — создания инструмента для внутренних ссылок, мы должны определить, какие данные следует загрузить в векторную базу данных для использования в качестве метаданных. Эти метаданные служат дополнительным уровнем направления во время поиска, согласуясь со структурой RAG за счет включения внешних знаний. Эти дополнительные знания повысят качество поиска, выступая в качестве руководства.
Например, если мы редактируем статью о «PPC» и хотим вставить ссылку на фразу «Исследование ключевых слов», мы можем указать в нашем инструменте «Категория = PPC». Это позволит инструменту запрашивать только статьи в категории «PPC», обеспечивая точные и контекстуально релевантные ссылки, или мы можем захотеть дать ссылку на фразу «последнее обновление Google» и ограничить совпадение только новостными статьями, используя «Тип». ‘ и опубликовано в этом году.
В нашем случае мы будем экспортировать:
- Заголовок.
Категория. - Тип.
- Дата публикации.
- Год публикации.
- Постоянная ссылка.
- Мета-описание.
- Содержание.
Чтобы получить наилучшие результаты, мы объединили бы поля заголовка и метаописания, поскольку они являются лучшим представлением статьи, которую мы можем векторизовать, и идеально подходят для целей встраивания и внутренних ссылок.
Использование полного содержимого статьи для встраивания может снизить точность и снизить релевантность векторов.
Это происходит потому, что одно большое вложение пытается представить несколько тем, затронутых в статье одновременно, что приводит к менее целенаправленному и релевантному представлению. Необходимо применять стратегии разбиения на части (разделение статьи по естественным заголовкам или семантически значимым сегментам), но это не является целью данной статьи.
Вот пример файла экспорта, который вы можете скачать и использовать для нашего примера кода ниже.
2. Вставка текстовых вложений OpenAi в базу данных векторов
Как опытный энтузиаст машинного обучения с многолетним опытом за плечами, я могу с уверенностью сказать, что использование OpenAI API для создания векторных векторных представлений и их хранения в базе данных Pinecone меняет правила игры для задач обработки естественного языка. Эта комбинация позволяет мне эффективно обрабатывать и анализировать большие объемы текстовых данных, что упрощает извлечение значимой информации из неструктурированной информации. Я обнаружил, что этот подход значительно упрощает мой рабочий процесс, экономя драгоценное время и ресурсы. Если вы работаете над подобными проектами, я настоятельно рекомендую попробовать!
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
def generate_embeddings(text):
"""
Generates an embedding for the given text using OpenAI's API.
Returns None if text is invalid or an error occurs.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Clear output for a fresh display
if hasattr(result, 'data') and len(result.data) > 0:
print("API Response:", result)
return result.data[0].embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Load your articles from a CSV
df = pd.read_csv('Sample Export File.csv')
# Process each article
for idx, row in df.iterrows:
try:
clear_output(wait=True)
content = row["Content"]
vector = generate_embeddings(content)
if vector is None:
print(f"Skipping article ID {row['ID']} due to empty or invalid embedding.")
continue
index.upsert(vectors=[
(
row['Permalink'], # Unique ID
vector, # The embedding
{
'title': row['Title'],
'category': row['Category'],
'type': row['Type'],
'publish_date': row['Publish Date'],
'publish_year': row['Publish Year']
}
)
])
except Exception as e:
clear_output(wait=True)
print(f"Error processing article ID {row['ID']}: {str(e)}")
print("Embeddings are successfully stored in the vector database.")
Чтобы справиться с этой задачей, вам следует:
1. Создайте новый файл блокнота.
2. Перенесите содержимое «Образца файла экспорта.csv» и вставьте его в созданный вами файл блокнота.
3. Сохраните оба файла в одной папке для быстрого доступа.
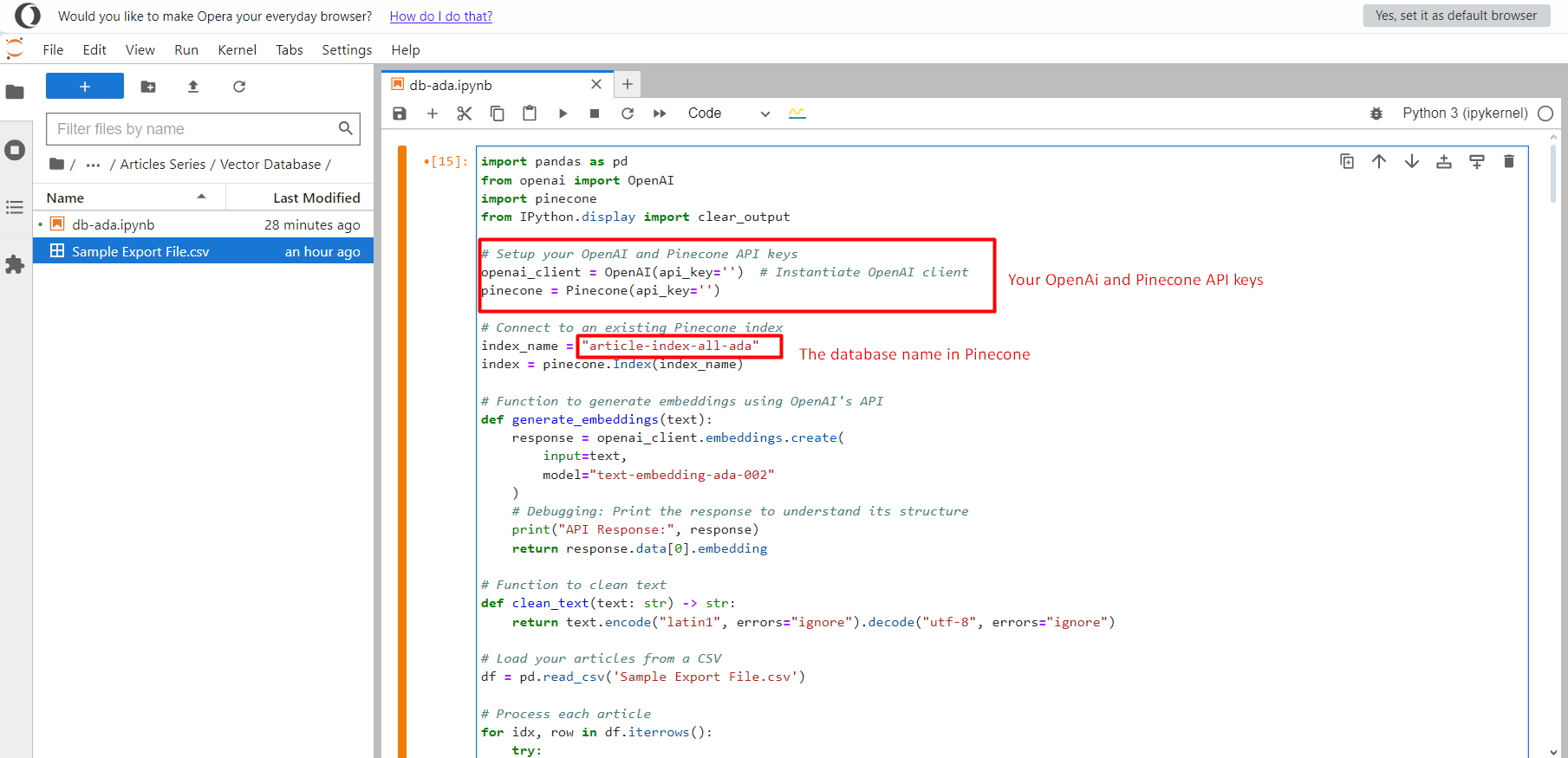
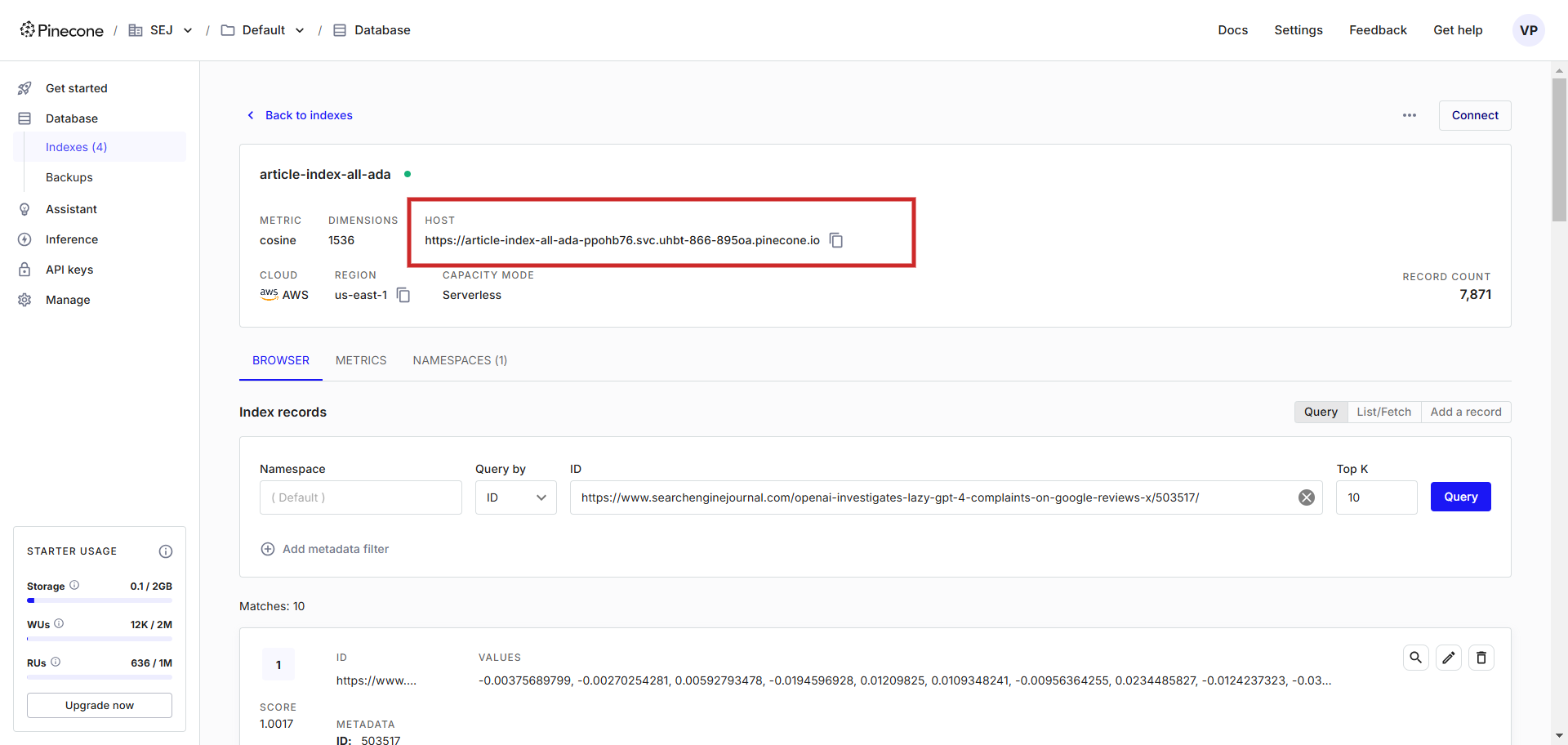
После этого нажмите кнопку «Выполнить», и все векторы встраивания текста начнут помещаться в индекс article-index-all-ada, который мы создали на первом этапе.
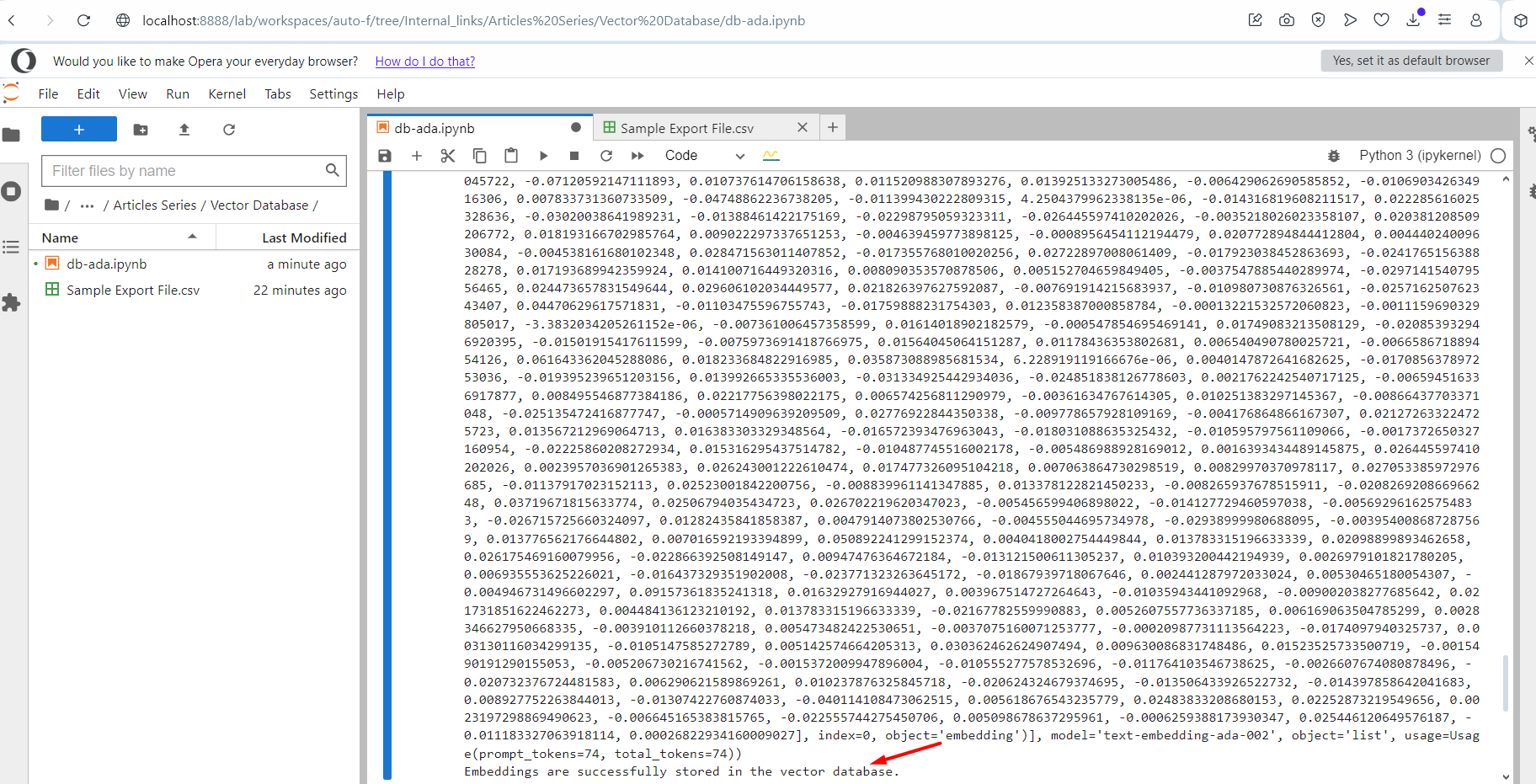
После запуска программы вы увидите журнал, отображающий векторы внедрения в качестве выходных данных. По завершении появится сообщение об успешном завершении. Затем перейдите к своему индексу в Pinecone, и вы заметите, что ваши данные сохранены там.
3. Поиск соответствия статьи ключевому слову
Хорошо, давайте попробуем найти статью, соответствующую ключевому слову.
Создайте новый файл блокнота, скопируйте и вставьте этот код.
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
from tabulate import tabulate # Import tabulate for table formatting
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
# Function to generate embeddings using OpenAI's API
def generate_embeddings(text):
"""
Generates an embedding for a given text using OpenAI's API.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
# Debugging: Print the response to understand its structure
clear_output(wait=True)
#print("API Response:", result)
if hasattr(result, 'data') and len(result.data) > 0:
return result.data[0].embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Function to query the Pinecone index with keywords and metadata
def match_keywords_to_index(keywords):
"""
Matches a list of keywords to the closest article in the Pinecone index, filtering by metadata dynamically.
"""
results = []
for keyword_pair in keywords:
try:
clear_output(wait=True)
# Extract the keyword and category from the sub-array
keyword = keyword_pair[0]
category = keyword_pair[1]
# Generate embedding for the current keyword
vector = generate_embeddings(keyword)
if vector is None:
print(f"Skipping keyword '{keyword}' due to embedding error.")
continue
# Query the Pinecone index for the closest vector with metadata filter
query_results = index.query(
vector=vector, # The embedding of the keyword
top_k=1, # Retrieve only the closest match
include_metadata=True, # Include metadata in the results
filter={"category": category} # Filter results by metadata category dynamically
)
# Store the closest match
if query_results['matches']:
closest_match = query_results['matches'][0]
results.append({
'Keyword': keyword, # The searched keyword
'Category': category, # The category used for filtering
'Match Score': f"{closest_match['score']:.2f}", # Similarity score (formatted to 2 decimal places)
'Title': closest_match['metadata'].get('title', 'N/A'), # Title of the article
'URL': closest_match['id'] # Using 'id' as the URL
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
clear_output(wait=True)
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage: Find matches for an array of keywords and categories
keywords = [["SEO Tools", "SEO"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]] # Replace with your keywords and categories
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Мы пытаемся найти соответствие этим ключевым словам:
- SEO-инструменты.
- ТикТок.
- SEO-консультант.
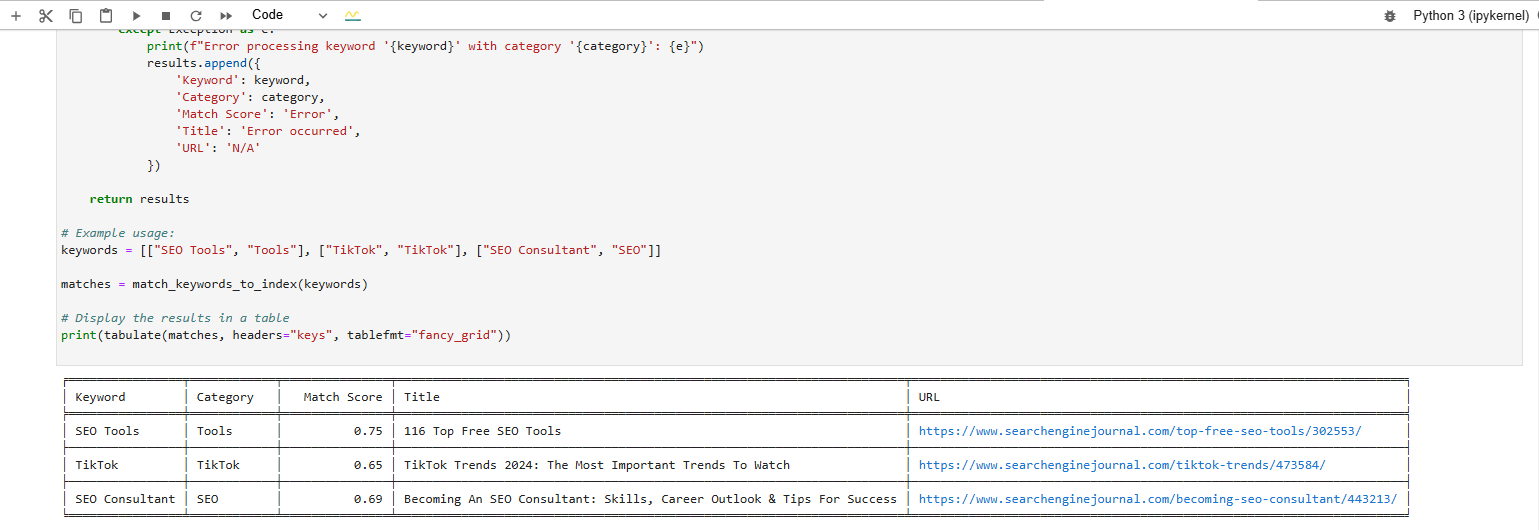
И вот какой результат мы получим после выполнения кода:
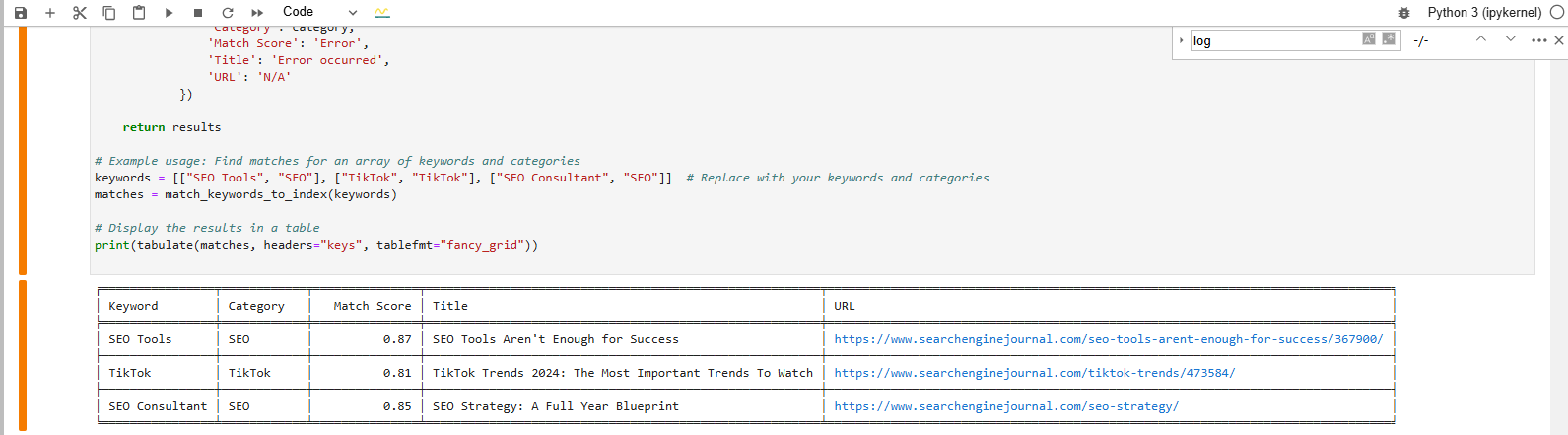
Вывод в формате таблицы внизу показывает статьи, наиболее близкие к нашим ключевым словам.
4. Вставка встраивания текста Google Vertex AI в базу данных векторов
Вместо этого давайте продолжим тот же подход, но воспользуемся моделью встраивания Google text-embedding-005. Эта модель выделяется тем, что она возникла в Google, ее ролью в обеспечении Vertex AI Search, а также ее специализированной подготовкой для таких задач, как поиск и сопоставление запросов. Учитывая эти характеристики, он идеально соответствует нашим требованиям.
Вы даже можете создать виджет внутреннего поиска и добавить его на свой сайт.
Сначала откройте Google Cloud Console и инициируйте новый проект. После этого найдите API Vertex AI в библиотеке API и активируйте его.
Чтобы начать использовать Vertex AI, создайте свою платежную учетную запись. Стоимость составляет всего 0,0002 доллара за каждые 1000 символов, а новые пользователи получают приветственный бонус в размере 300 долларов США в виде кредитов.
После настройки вам нужно будет перейти в раздел «Службы API», а затем выполнить следующие действия: создать новую учетную запись службы, создать связанный с ней ключ и сохранить этот ключ в формате JSON, загрузив его.
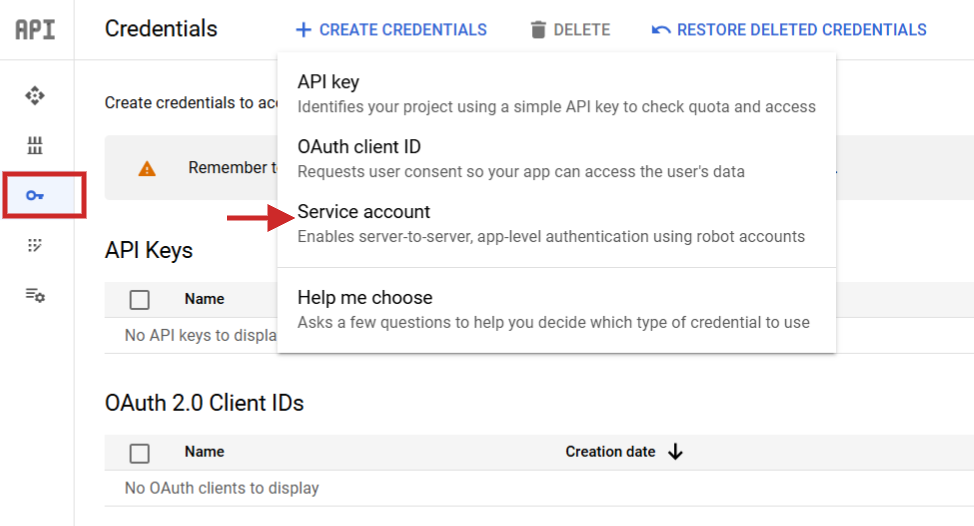
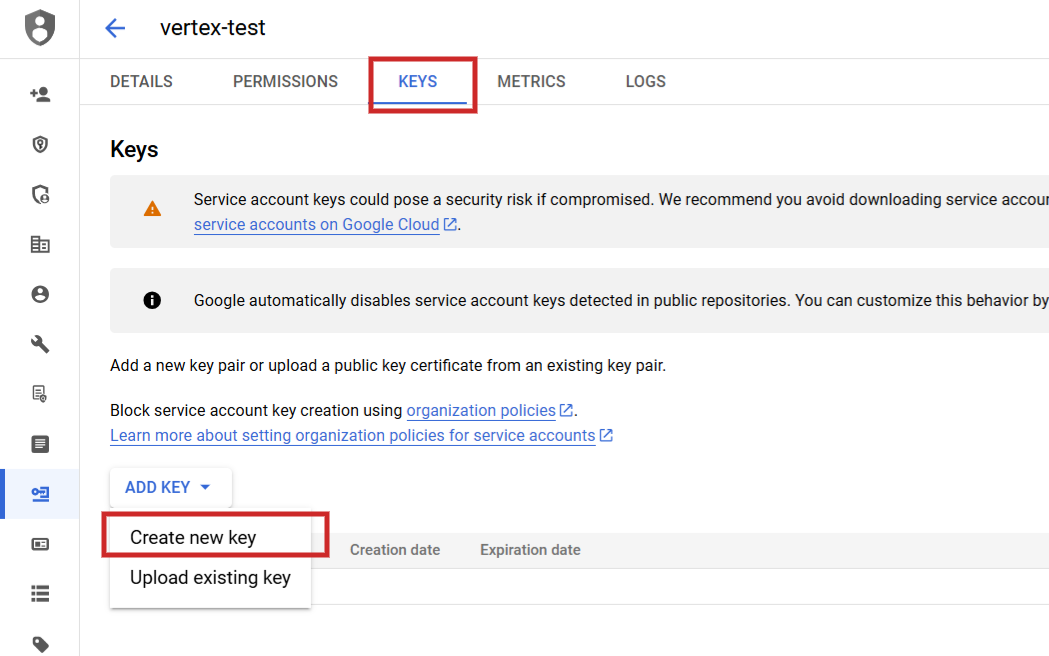

Обновите имя файла JSON на «config.json», а затем с помощью значка стрелки вверх перенесите его в рабочий каталог Jupyter Notebook.
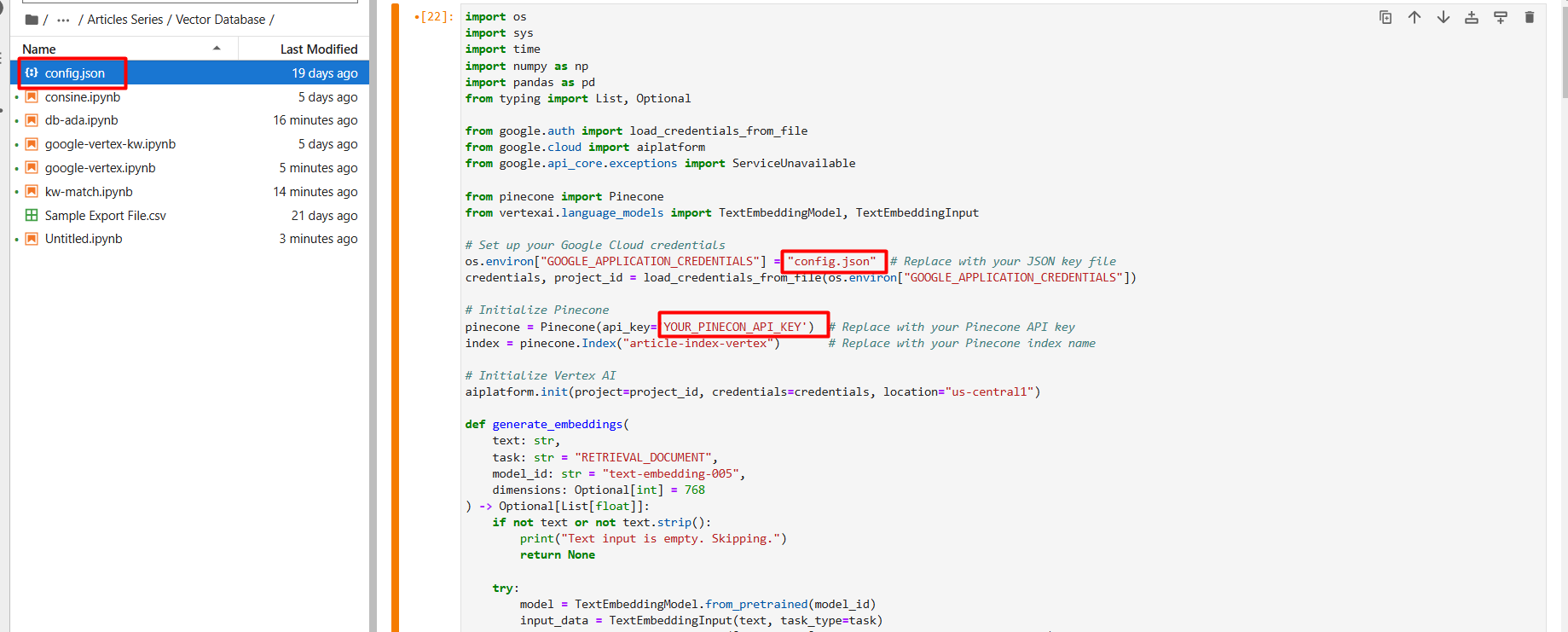
На первом этапе настройки создайте новую базу данных векторов под названием «article-index-vertex», вручную установив размерность 768.
После настройки вы можете выполнить этот скрипт, чтобы инициировать процесс создания векторных вложений из того же исходного файла с использованием модели Google Vertex AI text-embedding-005. Альтернативно, выберите text-multilingual-embedding-002, если ваш текст не на английском языке.
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import List, Optional
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Set up your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Replace with your Pinecone API key
index = pinecone.Index("article-index-vertex") # Replace with your Pinecone index name
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
task: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Optional[int] = 768
) -> Optional[List[float]]:
if not text or not text.strip:
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(text, task_type=task)
vectors = model.get_embeddings([input_data], output_dimensionality=dimensions)
return vectors[0].values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# Load data from CSV
data = pd.read_csv("Sample Export File.csv") # Replace with your CSV file path
for idx, row in data.iterrows:
try:
permalink = str(row["Permalink"])
content = row["Content"]
embedding = generate_embeddings(content)
if not embedding:
print(f"Skipping article ID {row['ID']} due to empty or failed embedding.")
continue
print(f"Embedding for {permalink}: {embedding[:5]}...")
sys.stdout.flush
index.upsert(vectors=[
(
permalink,
embedding,
{
'category': row['Category'],
'title': row['Title'],
'publish_date': row['Publish Date'],
'type': row['Type'],
'publish_year': row['Publish Year']
}
)
])
time.sleep(1) # Optional: Sleep to avoid rate limits
except Exception as e:
print(f"Error processing article ID {row['ID']}: {e}")
print("All embeddings are stored in the vector database.")
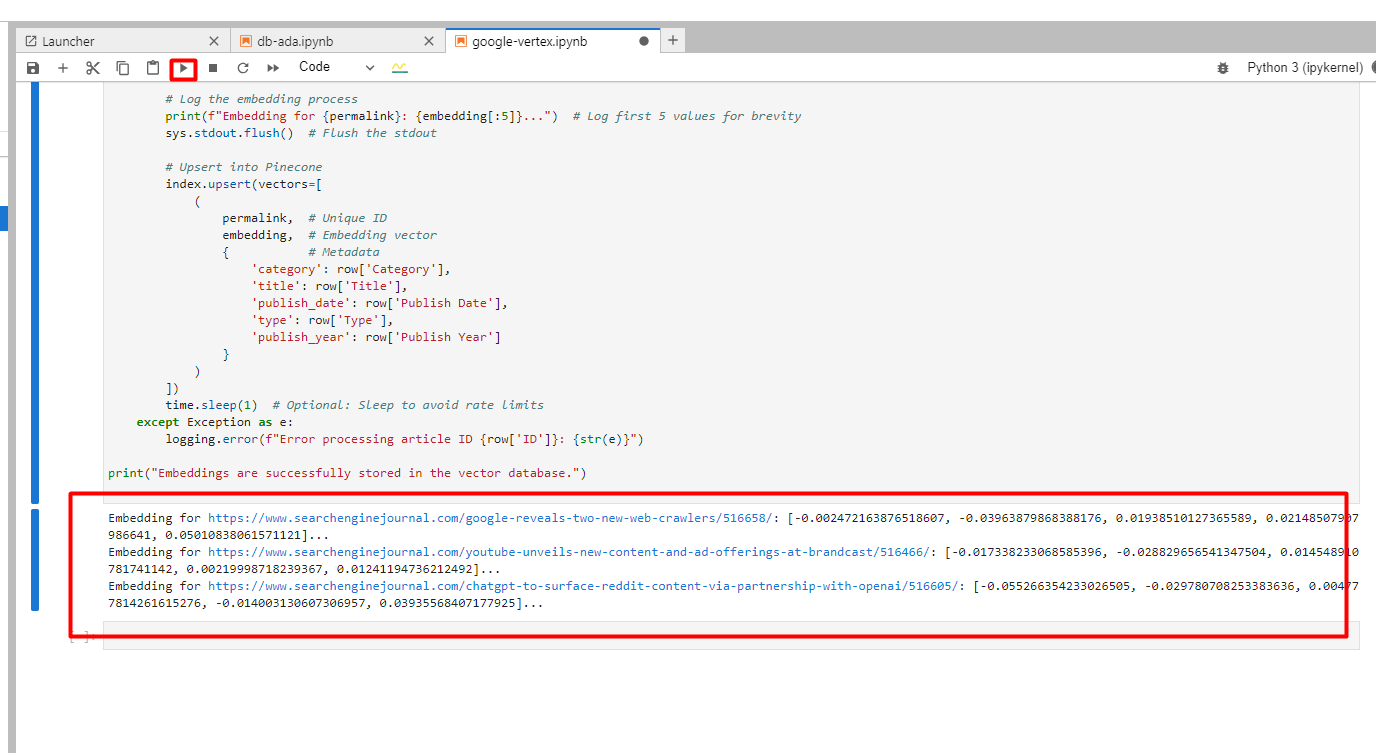
Вы увидите ниже в логах созданных вложений.
4. Поиск соответствия статьи ключевому слову с помощью Google Vertex AI
Теперь давайте проделаем то же самое сопоставление ключевых слов с Vertex AI. Есть небольшой нюанс: вам нужно использовать «RETRIEVAL_QUERY» вместо «RETRIEVAL_DOCUMENT» в качестве аргумента при генерации вложений ключевых слов, поскольку мы пытаемся выполнить поиск статьи (она же документа), которая лучше всего соответствует нашей фразе.
Типы задач — одно из важных преимуществ Vertex AI перед моделями OpenAI.
Этот метод гарантирует, что встраивания точно отражают значение ключевых слов, что является решающим аспектом для эффективных внутренних ссылок. Это также повышает актуальность и точность результатов, полученных из вашей векторной базы данных.
Используйте этот скрипт для сопоставления ключевых слов с векторами.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # For table formatting
# Set up your Google Cloud credentials
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ["GOOGLE_APPLICATION_CREDENTIALS"])
# Initialize Pinecone client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API key
index_name = "article-index-vertex" # Replace with your Pinecone index name
index = pinecone.Index(index_name)
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
model_id: str = "text-embedding-005"
) -> list:
"""
Generates embeddings for the input text using Google Vertex AI's embedding model.
Returns None if text is empty or an error occurs.
"""
if not text or not text.strip:
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings([text]) # Removed 'task_type' and 'output_dimensionality'
return vector[0].values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
def match_keywords_to_index(keywords):
"""
Matches a list of keyword-category pairs to the closest articles in the Pinecone index,
filtering by metadata if specified.
"""
results = []
for keyword_pair in keywords:
keyword = keyword_pair[0]
category = keyword_pair[1]
try:
keyword_vector = generate_embeddings(keyword)
if not keyword_vector:
print(f"No embedding generated for keyword '{keyword}' in category '{category}'.")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error/Empty',
'Title': 'No match',
'URL': 'N/A'
})
continue
query_results = index.query(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"category": category}
)
if query_results['matches']:
closest_match = query_results['matches'][0]
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': f"{closest_match['score']:.2f}",
'Title': closest_match['metadata'].get('title', 'N/A'),
'URL': closest_match['id']
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage:
keywords = [["SEO Tools", "Tools"], ["TikTok", "TikTok"], ["SEO Consultant", "SEO"]]
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
И вы увидите сгенерированные баллы:
Попробуйте проверить релевантность написания вашей статьи
Думайте об этом как об упрощенном (широком) способе проверить, насколько семантически ваше письмо соответствует ключевому слову head. Создайте векторное встраивание ключевого слова и всего содержимого статьи с помощью Google Vertex AI и рассчитайте косинусное сходство.
Если ваш текст слишком длинный, возможно, вам придется рассмотреть возможность реализации стратегии разделения на фрагменты.
Оценка, близкая к 1,0 (например, 0,8 или 0,7), предполагает высокий уровень сходства по теме. Если ваш балл ниже, это может указывать на то, что слишком длинное введение, наполненное ненужными подробностями, может снизить актуальность. Вместо этого его обрезка может улучшить фокус.
Однако имейте в виду, что любые вносимые вами изменения должны быть логичными и полезными как с точки зрения редактора, так и с точки зрения пользователя.
Вы можете быстро оценить свою эффективность, интегрировав высококлассный контент конкурента в качестве ориентира, что позволит вам оценить свое собственное положение.
Выполнение этого действия может помочь обеспечить более точное соответствие вашего контента основной теме, что потенциально повысит ваши шансы на более высокий рейтинг.
Уже существуют инструменты, способные выполнять подобные работы, но освоение этих методов позволяет вам применять индивидуальный подход, соответствующий вашим конкретным требованиям — и, что наиболее важно, это можно сделать бесплатно.
Опробовав эти методы и оттачивая свои навыки, вы останетесь в авангарде, когда дело доходит до AI SEO, и сможете делать осознанный выбор.
Смотрите также
- Акции привилегированные PMSBP. Пермэнергосбыт: прогноз акций привилегированных.
- Разработчики систем – как ИИ меняет работу SEO
- Как выбрать правильную стратегию назначения ставок для кампаний по привлечению потенциальных клиентов
- Обновление ядра Google за декабрь 2024 г. уже доступно — что мы видим
- Google протестирует фоновые изображения, созданные искусственным интеллектом для ваших рекламных объявлений
- Построение сообщества для маркетологов: поиск своего «зачем»
- 8 наиболее важных KPI PPC, которые стоит отслеживать
- Google: Более крупные и долгосрочные проблемы могут занять больше времени на обращение в результатах поиска Google
- Серебро прогноз
- Lenovo ThinkPad T14s 6-го поколения против 5-го поколения: Snapdragon X Elite или Intel Core Ultra?
2025-01-02 16:13