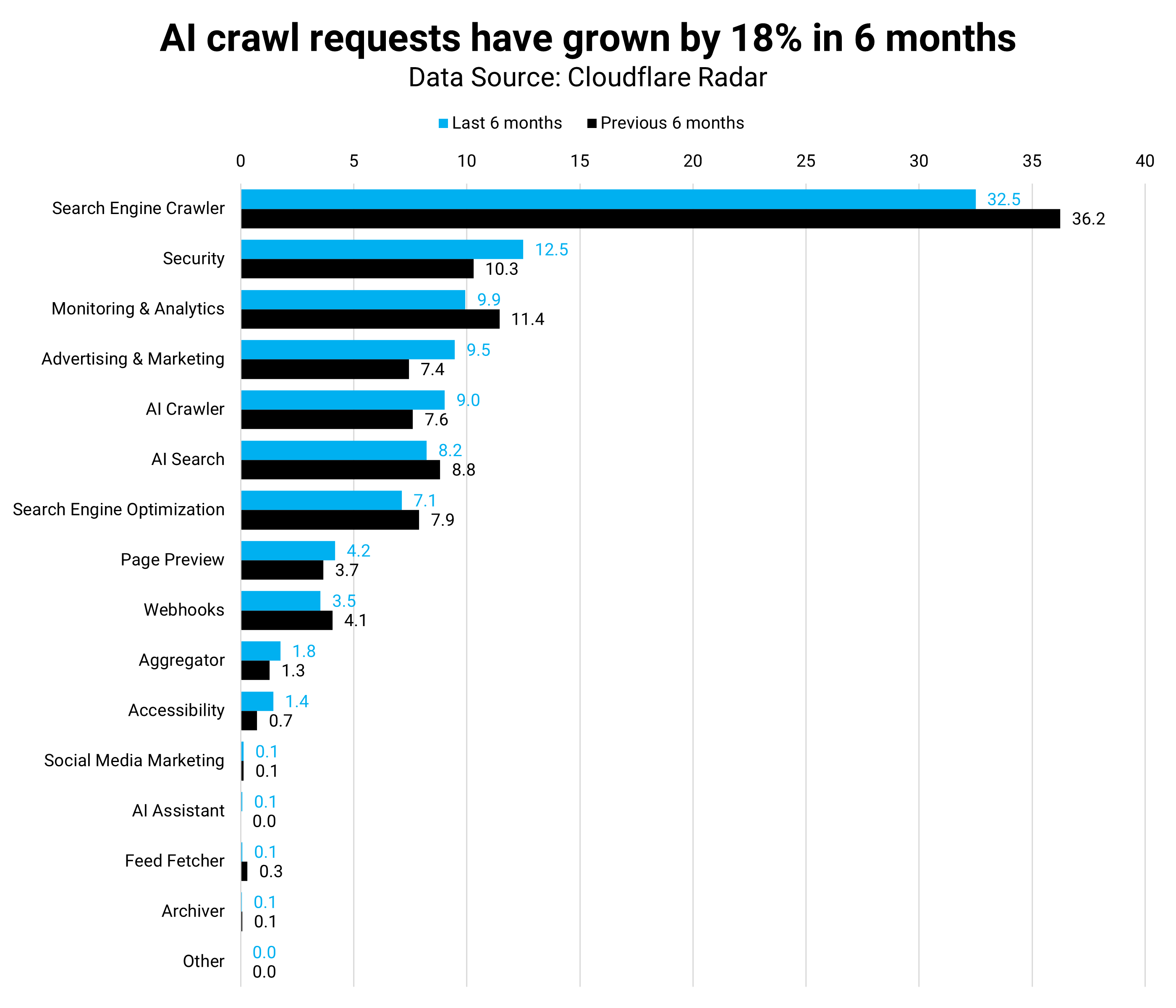
Разница между RAG и GraphRAG
Как опытный веб-мастер, ставший свидетелем эволюции поисковых систем с момента их скромного зарождения, я должен сказать, что GraphRAG выделяется как революционная инновация в этой области. Идея использования диаграммы знаний для организации и обобщения данных является не чем иным, как революционной. Это похоже на переход от пыльного библиотечного каталога к динамичной интерактивной карте информации, и все это на кончиках ваших пальцев.
Проще говоря, RAG (Поисковая расширенная генерация) работает, используя мощную языковую модель вместе с поисковой базой данных. Такая настройка позволяет более точно выдавать ответы на поисковые запросы. Извлекая текущие и актуальные данные из поискового индекса, он сводит к минимуму риск того, что поисковая система ИИ предоставит устаревшие или сфабрикованные ответы.
GraphRAG расширяет возможности традиционных RAG (готов, ожидает ответа и завершен), создавая граф знаний на основе поискового индекса, который впоследствии создает сводки, известные как «отчеты сообщества». Проще говоря, вместо того, чтобы полагаться исключительно на обновления вручную или отдельные ответы, GraphRAG использует данные из поискового индекса для создания взаимосвязанной сети (граф знаний), а затем генерирует краткие сводки по конкретным темам или областям (отчеты сообщества).
GraphRAG использует двухэтапный процесс:
Шаг 1. Создание структуры тематического индекса
Принято считать, что GraphRAG работает с графами знаний, но это еще не все. В действительности, на этапе механизма индексирования GraphRAG создает эти графы знаний из неорганизованных данных, таких как веб-страницы. В отличие от RAG, который просто собирает и обобщает информацию без создания иерархического графика, GraphRAG выделяется тем, что превращает необработанные данные в структурированные знания.
На шаге 2 GraphRAG использует построенный им граф знаний, чтобы предложить соответствующий контекст модели изучения языка (LLM), что позволяет ей давать более точные ответы на вопросы.
По словам Microsoft, проблема с функцией Retrival Augmented Generation (RAG) заключается в том, что ей трудно извлекать данные, относящиеся к конкретным темам, поскольку она в первую очередь фокусируется на понимании семантических связей.
Один из способов перефразирования данного текста заключается в следующем: вместо RAG, который использует семантические связи для поиска ответов, GraphRAG выделяется тем, что сначала преобразует все документы в своей поисковой базе данных в иерархический граф знаний, который классифицирует темы и подтемы (темы) постепенно от общее к частному. Это позволяет GraphRAG находить решения, даже если релевантные ключевые слова не связаны семантически в документе, благодаря фокусу на тематическом сходстве.
Система Baseline RAG испытывает трудности с обработкой запросов, которые требуют сбора данных из различных частей набора данных для получения ответа, например, таких вопросов, как «Каковы 5 основных тем в данных?» работает плохо, поскольку Baseline RAG работает путем поиска семантически связанного текста в наборе данных. Поскольку в запросе нет конкретных указаний, позволяющих направить его на получение соответствующей информации, он может не дать точных результатов.
С помощью GraphRAG мы можем решать такие вопросы, поскольку структура графа знаний, созданная LLM, дает представление об общей организации (и, следовательно, повторяющихся темах) в наборе данных. Таким образом, частный набор данных группируется в соответствующие семантические группы, которые были предварительно обобщены. Затем LLM привлекает эти группы для обобщения и обсуждения этих тем при ответе на запрос пользователя.
Обновление для GraphRAG
Таким образом, GraphRAG создает граф знаний, используя свой индекс поиска. «Сообщество» представляет собой совокупность связанных разделов или документов, сгруппированных вместе из-за их тематического сходства. С другой стороны, «отчет сообщества» представляет собой краткий обзор, созданный LLM для каждого конкретного сообщества.
В первоначальной конструкции GraphRAG он обрабатывал все отчеты сообщества, даже те, которые содержали низкоуровневые сводки, не имеющие прямого отношения к поисковому запросу. Microsoft называет эту методологию «статической», поскольку она не включает динамическую фильтрацию или настройку на основе релевантности запроса.
В обновленном GraphRAG представлен «динамический выбор сообщества», который оценивает актуальность каждого отчета сообщества. Нерелевантные отчеты и их подсообщества удаляются, что повышает эффективность и точность за счет сосредоточения внимания только на актуальной информации.
При таком подходе мы включаем в наш алгоритм глобального поиска метод, называемый динамическим выбором сообщества. Этот метод использует преимущества структуры графа знаний, найденного в нашем наборе данных. Мы начинаем с оценки соответствия отчета сообщества вопросу пользователя с помощью модели большого языка (LLM). Если отчет считается нерелевантным, он и любые связанные с ним узлы или подсообщества исключаются из процесса поиска. И наоборот, если отчет считается релевантным, мы исследуем его дочерние узлы и повторяем один и тот же процесс. Конечным результатом является то, что только соответствующие отчеты попадают в операцию уменьшения карты, которая генерирует окончательный ответ для пользователя.
Выводы: результаты обновления GraphRAG
Microsoft обнаружила, что последняя версия GraphRAG значительно сократила вычислительные затраты примерно на 77%. Это снижение было особенно заметно в стоимости токена во время обработки языковой моделью (LLM). Проще говоря, токены — это фундаментальные компоненты текста, которые обрабатываются LLM. Для расширенного GraphRAG теперь требуется меньший LLM, что означает снижение затрат без ущерба для качества результатов.
Положительное влияние на качество результатов поиска:
- Динамический поиск предоставляет ответы, содержащие более конкретную информацию.
- Результаты более полные и специфичные для запроса пользователя, что помогает избежать предоставления слишком большого количества информации.
GraphRAG: улучшение глобального поиска за счет динамического выбора сообщества
Смотрите также
- Какой самый низкий курс доллара к турецкой лире?
- Золото прогноз
- Какой самый низкий курс евро к рублю?
- Серебро прогноз
- Акции SFIN. ЭсЭфАй: прогноз акций.
- Анализ динамики цен на криптовалюту LTC: прогнозы лайткоина
- Google AI Mode Tests Text Selection For Follow Up Questions
- Google: Почему 100 отрицательных ключевых слов для кампаний Google Ads PMax
- Google Ads Planner Planner Новые ключевые слова Auto-Organize для групп объявлений
- Google тестирует значки проверки для бесплатных списков результатов поиска
2024-11-20 13:38