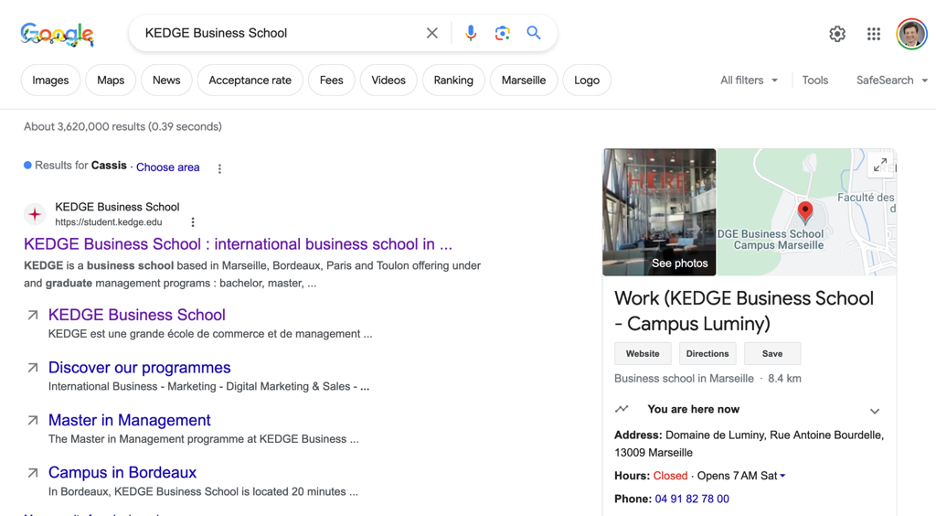
Как опытный эксперт по SEO с более чем двадцатилетним опытом работы в постоянно меняющемся ландшафте алгоритмов поисковых систем, я одновременно заинтригован и с осторожным оптимизмом смотрю на новые страницы результатов поиска Google, организованные с помощью искусственного интеллекта.
Google представляет страницы результатов поиска, организованные с помощью искусственного интеллекта, в США.
Эта предстоящая функция, дебют которой состоится на этой неделе, предоставит комплексный, индивидуальный набор результатов поиска в нескольких стилях, адаптированных специально для пользователя, на одной странице.
В объявлении Google говорится:
Начиная с этой недели мы представляем в США страницы результатов поиска, организованные с помощью искусственного интеллекта, начиная с предложений рецептов и рекомендаций по приготовлению блюд на мобильных устройствах. Теперь вам понравится обширная страница, наполненная персонализированными результатами, отвечающими вашим интересам. Одним касанием вы можете просмотреть различные типы контента, такие как статьи, видео, обсуждения и т. д., собранные вместе для удобного просмотра.
Ключевые особенности
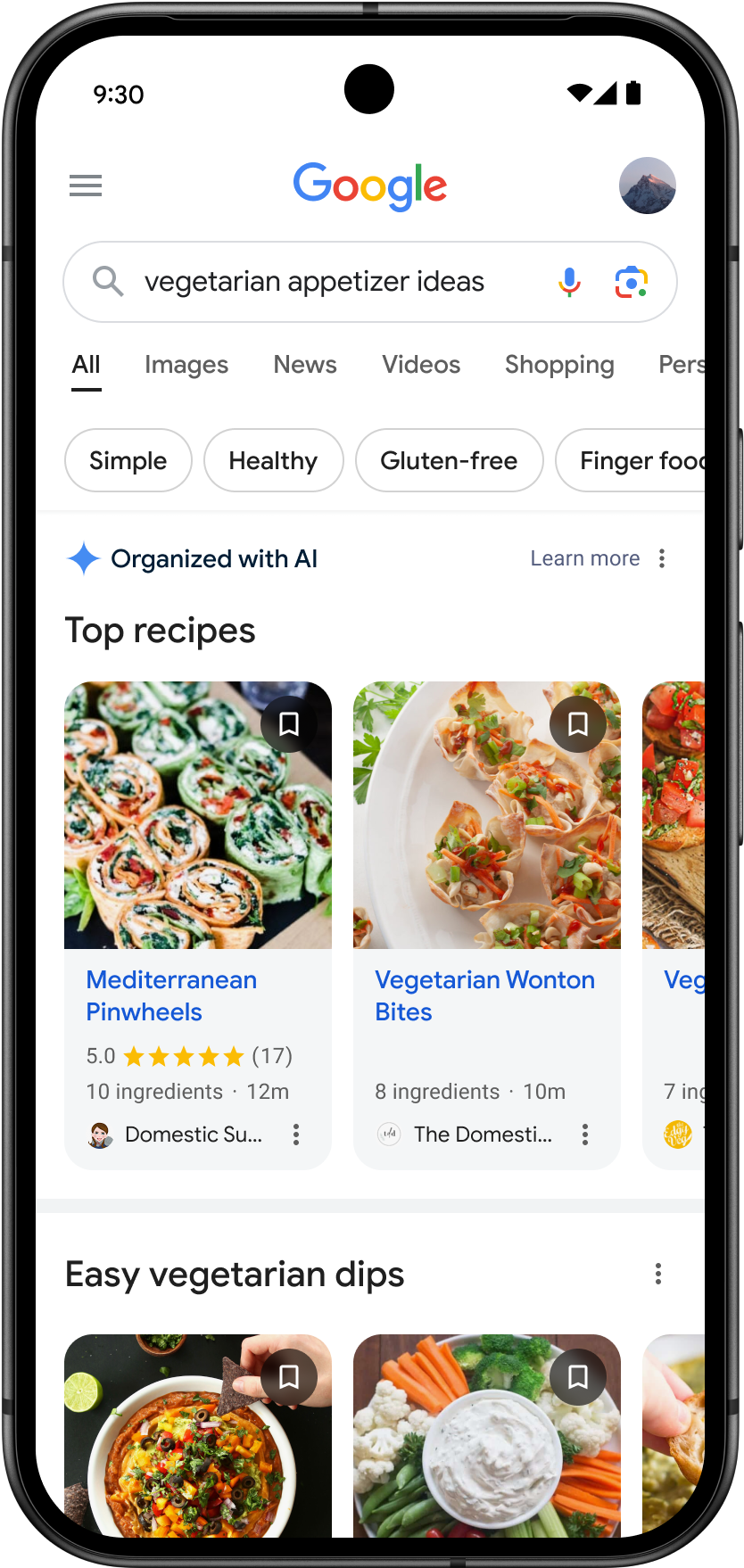
Проще говоря, система искусственного интеллекта собирает ряд материалов, таких как сообщения в блогах, видео и обсуждения, для создания всеобъемлющей коллекции по различным темам.
В своем объявлении Google Ads:
Упорядочивая результаты поиска с помощью технологии искусственного интеллекта, мы предоставляем более широкий выбор типов контента и веб-сайтов, тем самым увеличивая шансы найти новый и интересный контент.
Последствия для отрасли
Поскольку Google подчеркивает преимущества страниц результатов поиска, организованных искусственным интеллектом, обновление вызывает ряд запросов:
- Поскольку ИИ определяет организацию контента, возникают опасения по поводу возможных предвзятостей в представлении информации.
- Новый формат может потребовать новых стратегий для обеспечения наглядности результатов, организованных ИИ.
- Неясно, как это изменение повлияет на видимость рекламы.
Это изменение может потребовать от нас переосмысления нашей тактики SEO. Возможно, нам придется изменить наши стратегии, чтобы наш контент можно было легко найти и правильно отобразить в этом новом макете.
Microsoft Bing недавно представила расширение возможностей своей поисковой системы генерировать ответы на сложные информационные вопросы. В отличие от Bing, Google выделяется реструктуризацией целых страниц результатов поиска.
На первом этапе особое внимание уделяется мобильным устройствам при ответе на вопросы о рецептах и блюдах, что соответствует стратегии Google по определению приоритета мобильного контента.
Еще неизвестно, как эта функция будет реализована в поиске на рабочем столе.
Ответ Google на проблемы отрасли
Учитывая запросы, вызванные этим недавним обновлением, мы обратились к Google, чтобы получить разъяснения по различным важным аспектам.
Влияние на отслеживание в Search Console
О мониторинге результатов поиска, организованных искусственным интеллектом, в Google Search Console представитель Google пояснил:
В Search Console мы не изолируем трафик по индивидуальным характеристикам, но вы все равно сможете просматривать свой трафик из Поиска. Более подробную информацию о поддерживаемых типах результатов поиска можно найти в нашей документации.
Это означает, что, хотя подробные показатели для веб-страниц, управляемых ИИ, предоставляться не будут, администраторы веб-сайтов все равно смогут получать общую статистику посещений.
График расширения
Что касается вашего вопроса о том, когда эта конкретная функция будет распространена на дополнительные категории и местоположения, Google сообщил, что вскоре поделится более подробной информацией.
Во время первоначальной проверки мы отметили, что можем распространить эту функцию на другие области, такие как рестораны, фильмы, музыка, литература, проживание и магазины. На данный момент у нас нет никакой дополнительной информации для раскрытия.
Хотя это подтверждает планы расширения, Google не предоставил конкретных сроков для этих развертываний.
Руководство для SEO-специалистов и создателей контента
Google подчеркнул, что не требуется никаких корректировок в отношении использования новых инструментов или инструкций для улучшения контента для результатов поиска, основанных на искусственном интеллекте.
Как SEO-экспертам, так и создателям контента нет необходимости существенно менять свои стратегии. Новые страницы результатов поиска, организованные с использованием технологии искусственного интеллекта, тесно связаны с нашими фундаментальными принципами ранжирования и качества в поиске, которые мы усердно совершенствовали в течение многих лет, чтобы выделять первоклассную информацию.
Этот ответ предполагает, что существующие лучшие практики SEO должны оставаться эффективными для видимости в этих новых форматах результатов.
Заглядывая в будущее
Ответы Google вносят некоторую ясность, но также оставляют место для спекуляций.
Для экспертов по SEO отсутствие специального метода мониторинга веб-страниц, управляемых искусственным интеллектом, в Search Console потенциально может затруднить прямое измерение точного влияния этой новой функции на трафик их сайта.
Это решение о расширении деятельности в таких областях, как рестораны, кино, музыка, литература, жилье и розничная торговля предполагает широкомасштабное воздействие, которое может затронуть несколько секторов.
Несмотря на то, что Google выразил уверенность, специалисты по SEO могут разработать новые стратегии, поскольку они адаптируются к этому существенному изменению способа отображения результатов поиска.
Как эксперт по SEO, я буду внимательно следить за последними событиями и анализировать их последствия для вас в ближайшие месяцы. Будьте на шаг впереди, подписавшись на нашу рассылку новостей SEJ, чтобы получать своевременные обновления.
Смотрите также
- Серебро прогноз
- 10 октября снова наблюдается нестабильность рейтинга в Google Поиске
- Акции SFIN. ЭсЭфАй: прогноз акций.
- Анализ динамики цен на криптовалюту LTC: прогнозы лайткоина
- Прогноз нефти
- Анализ динамики цен на криптовалюту FLR: прогнозы FLR
- Акции YDEX. Яндекс: прогноз акций.
- Новое руководство по эффективности рекламных кампаний Google: лучшие практики
- Анализ динамики цен на криптовалюту TIA: прогнозы TIA
- Анализ динамики цен на криптовалюту CRO: прогнозы CRO
2024-10-03 19:08