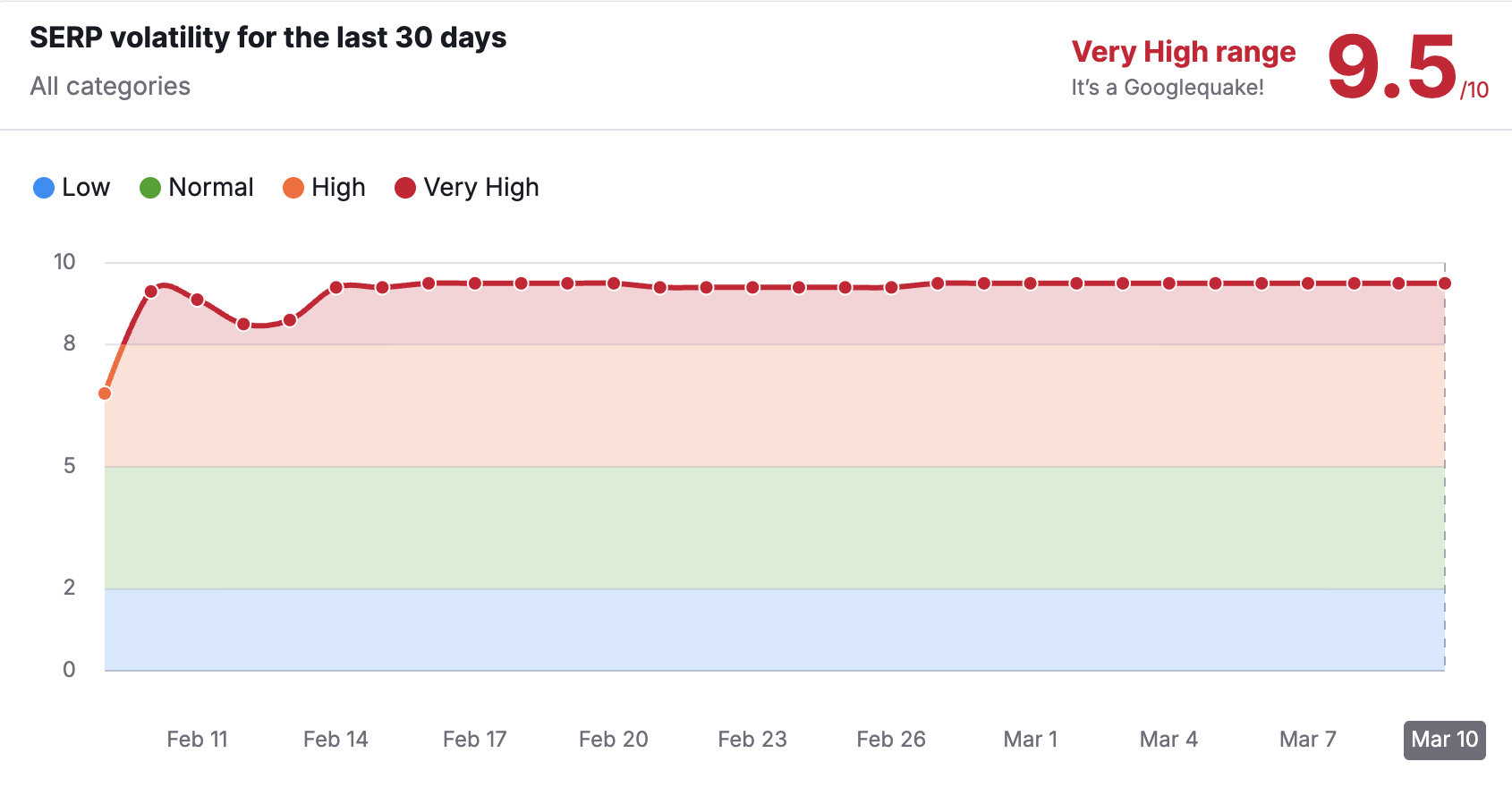
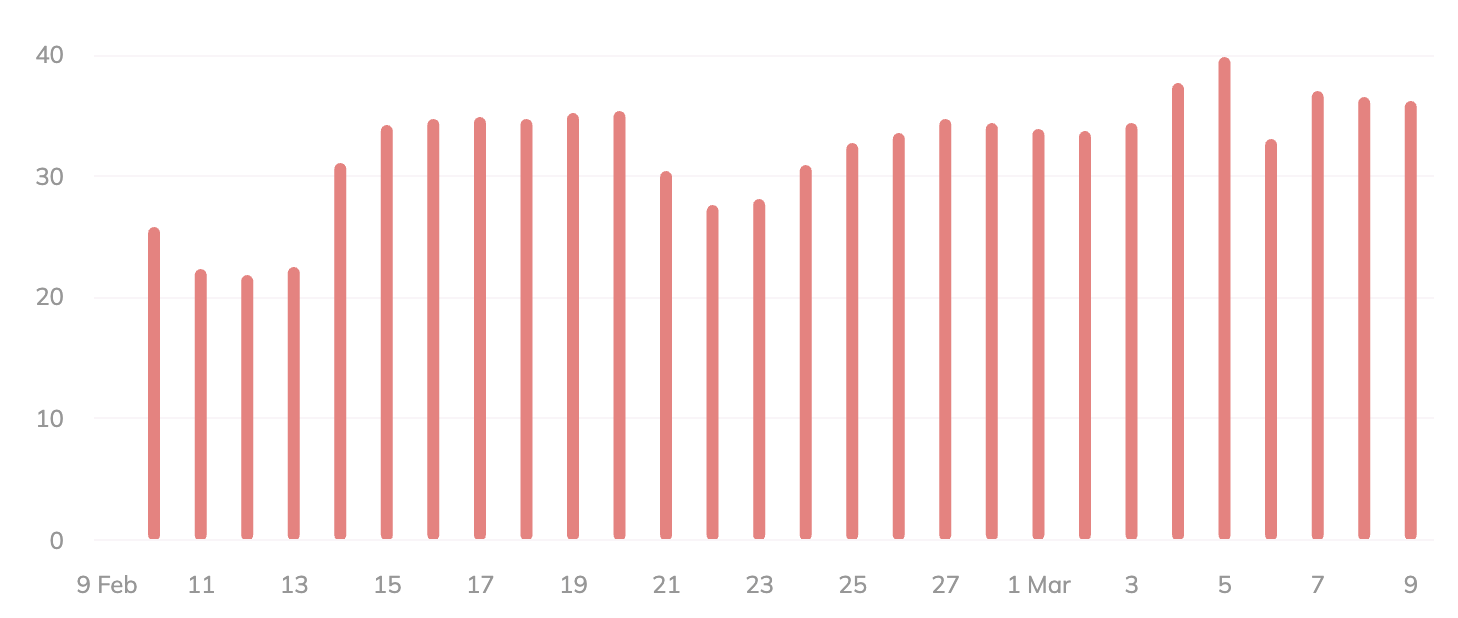
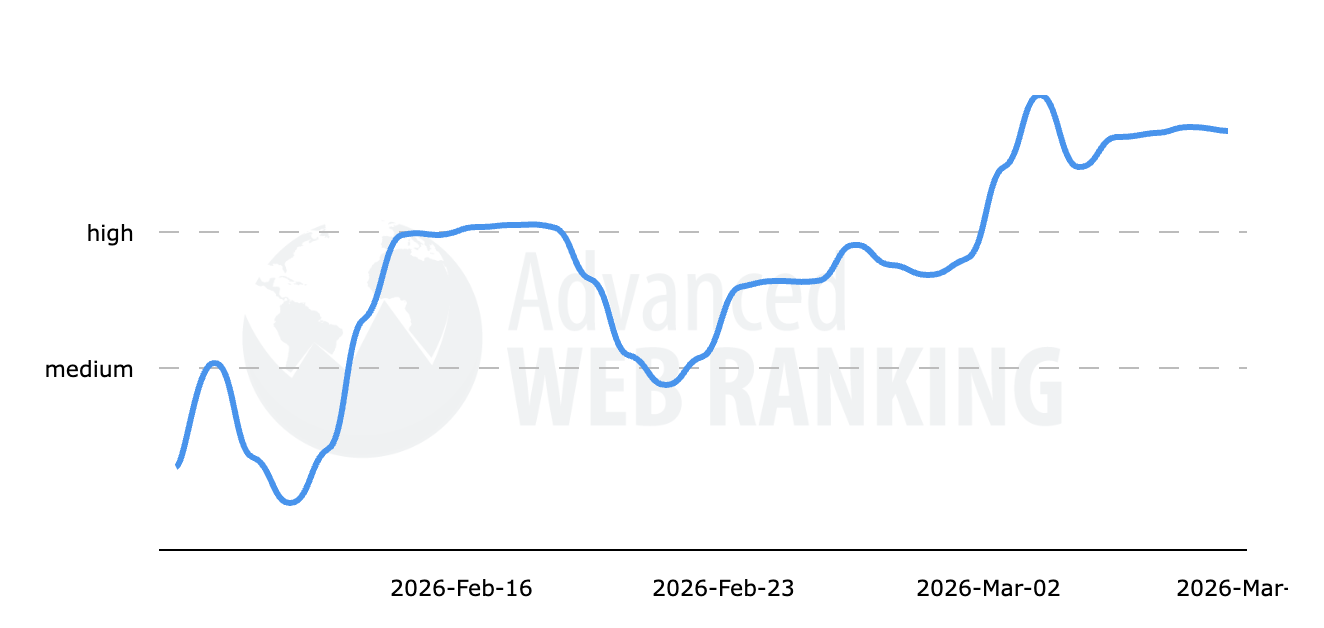
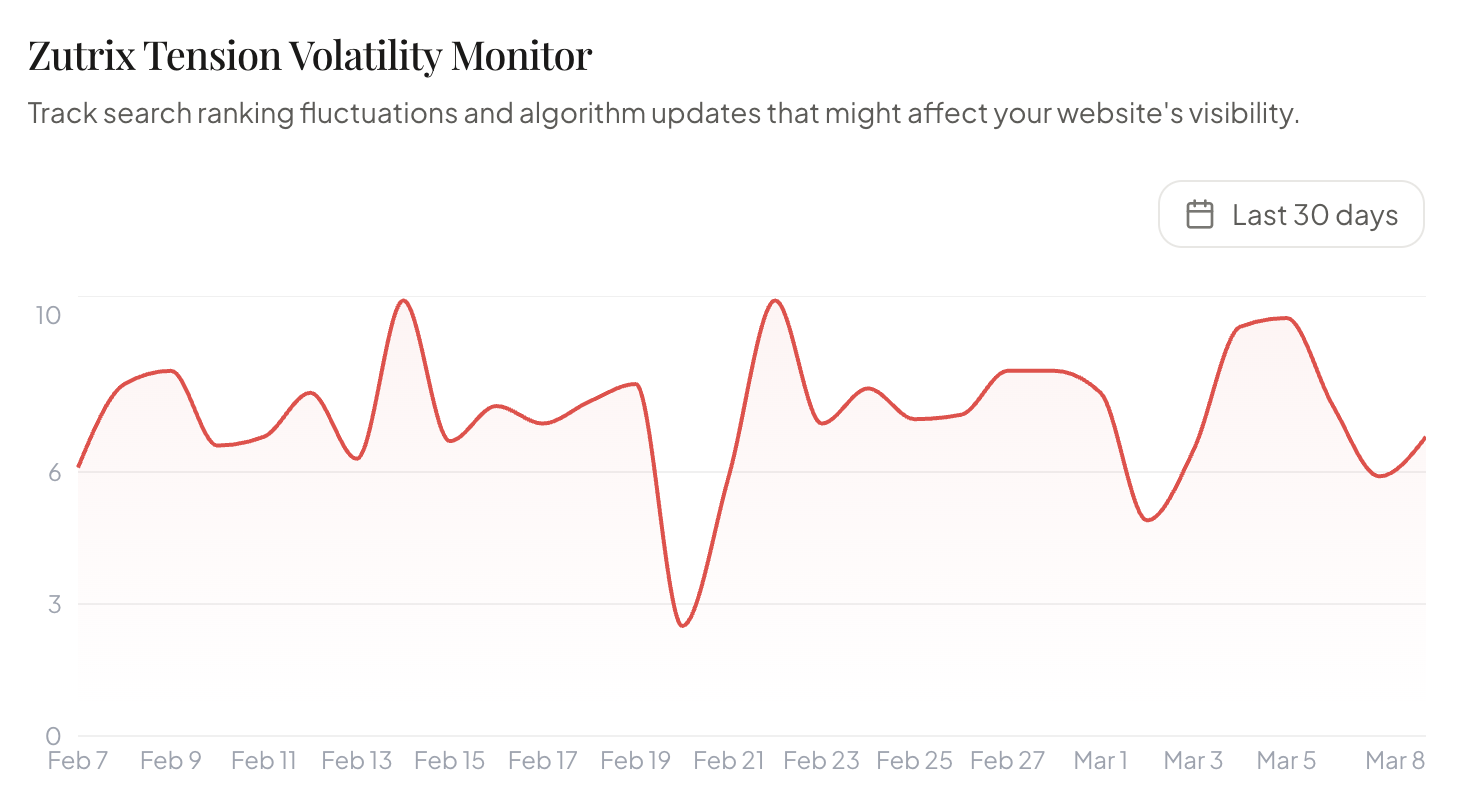
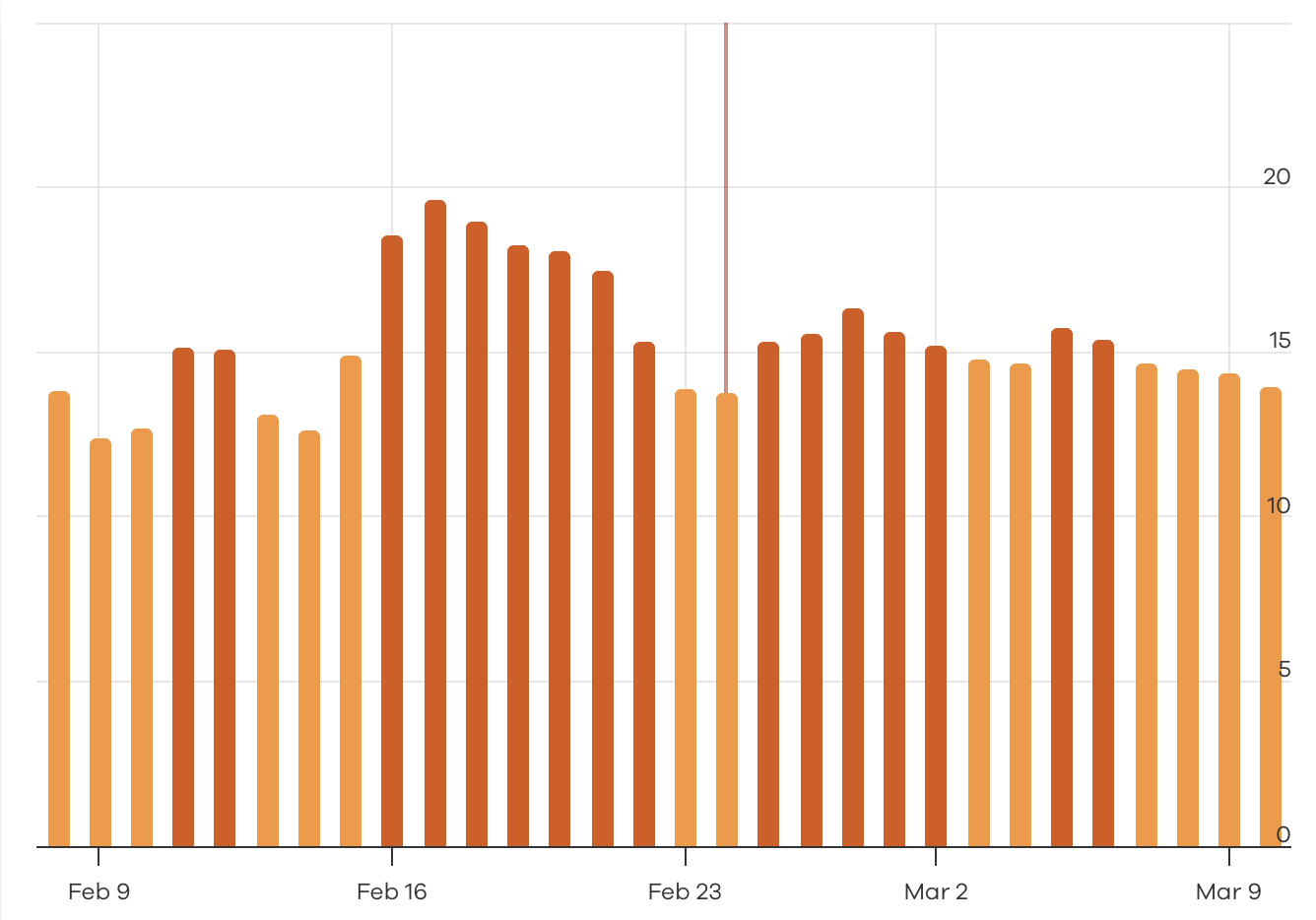
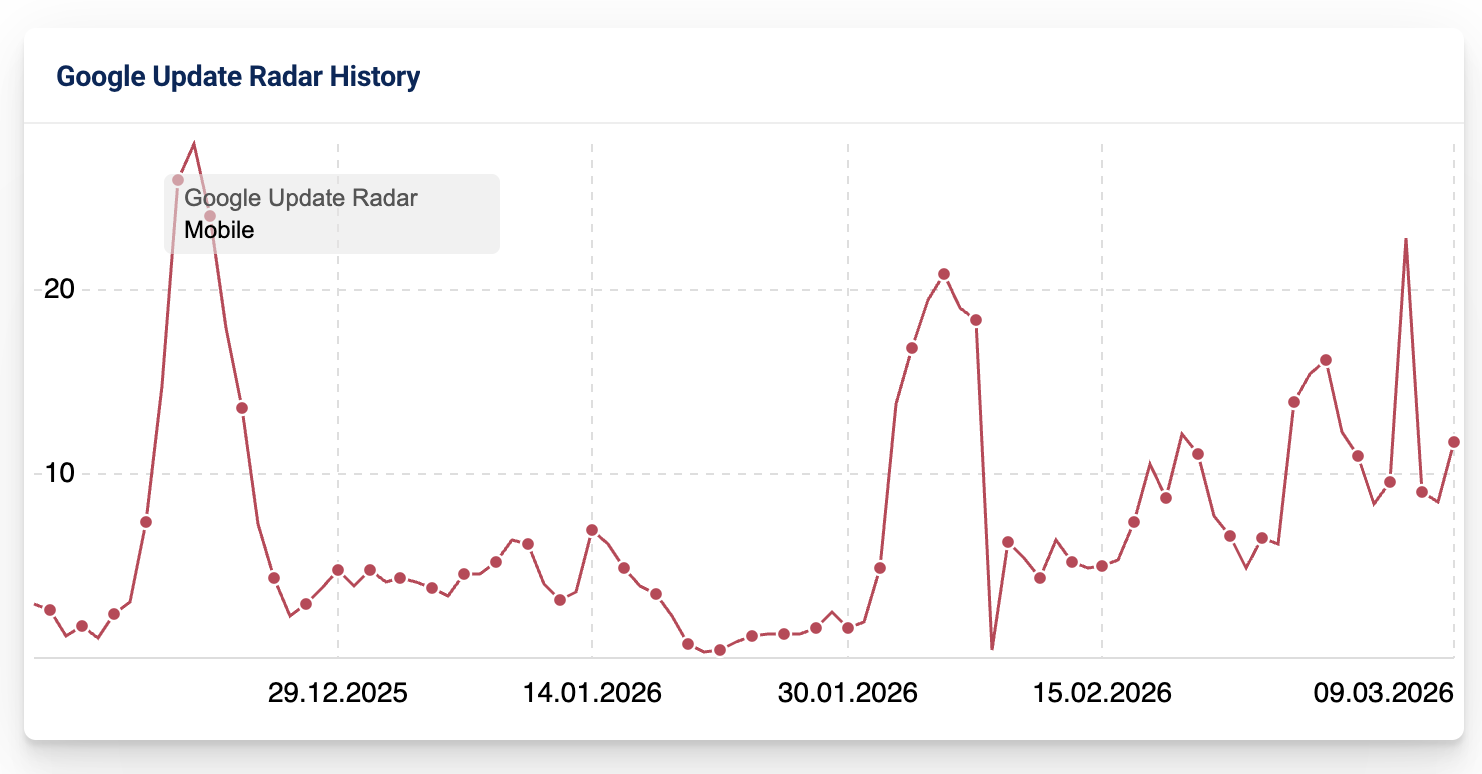
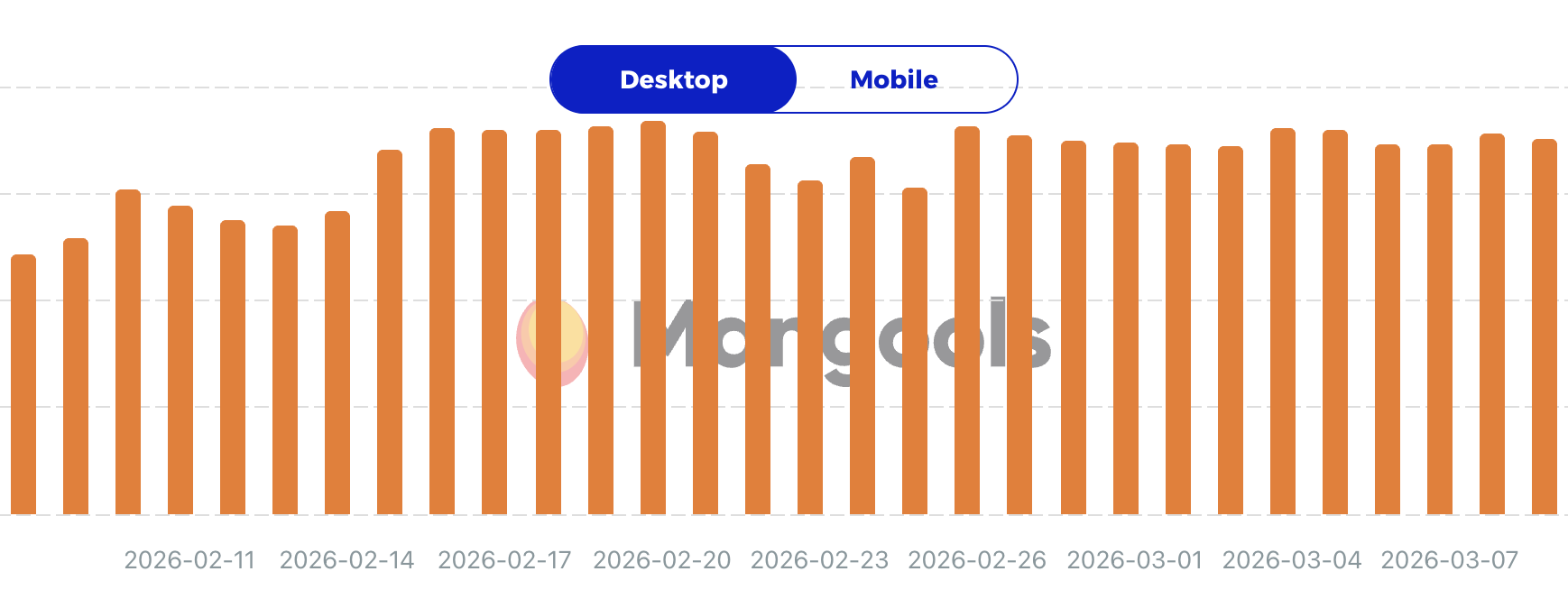
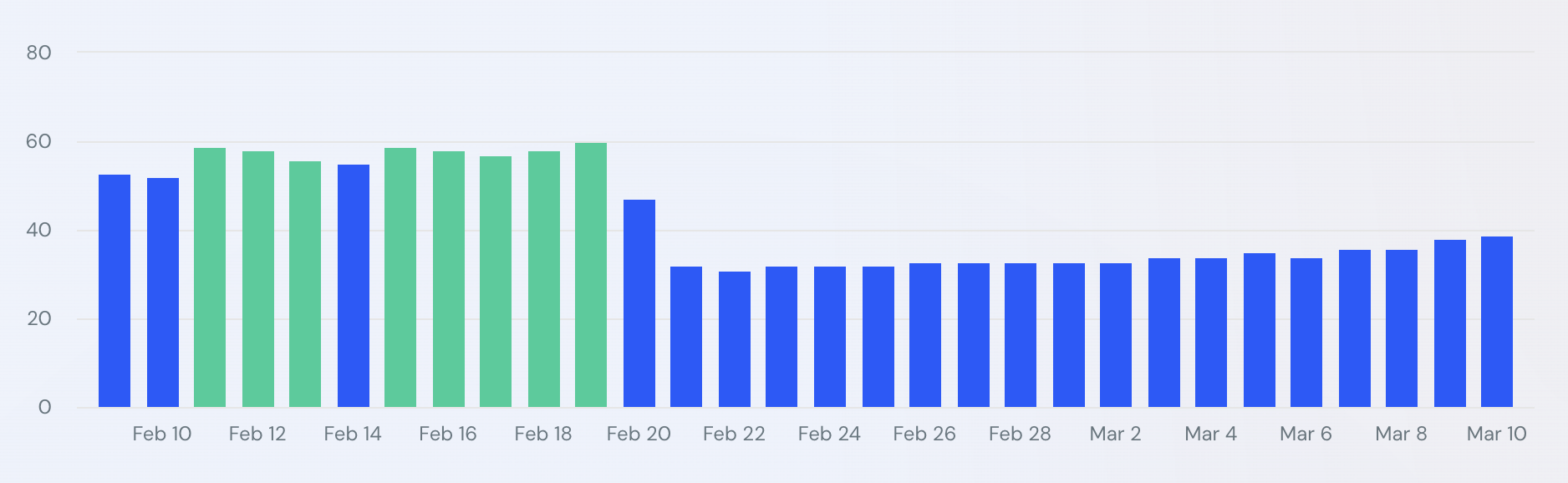
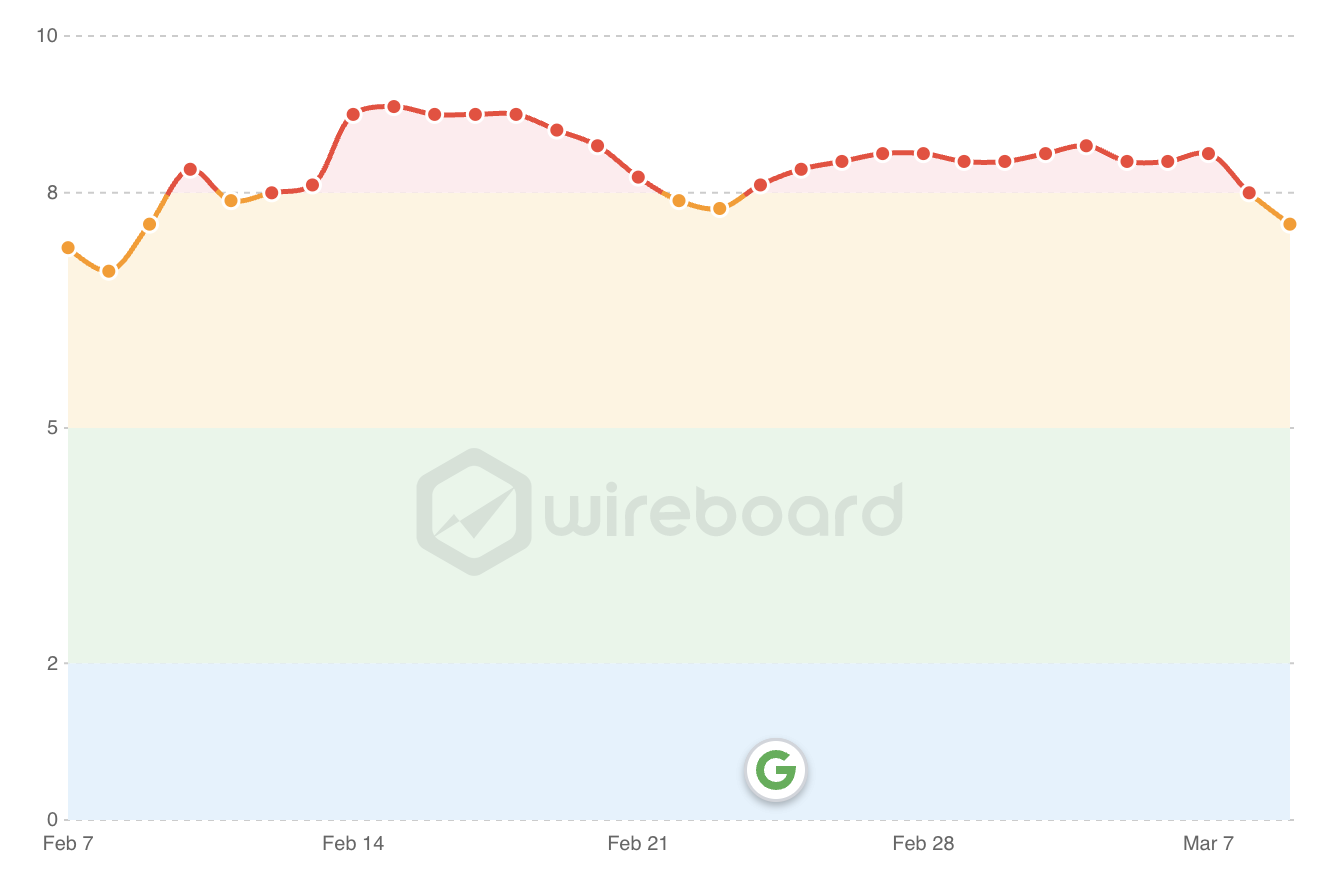
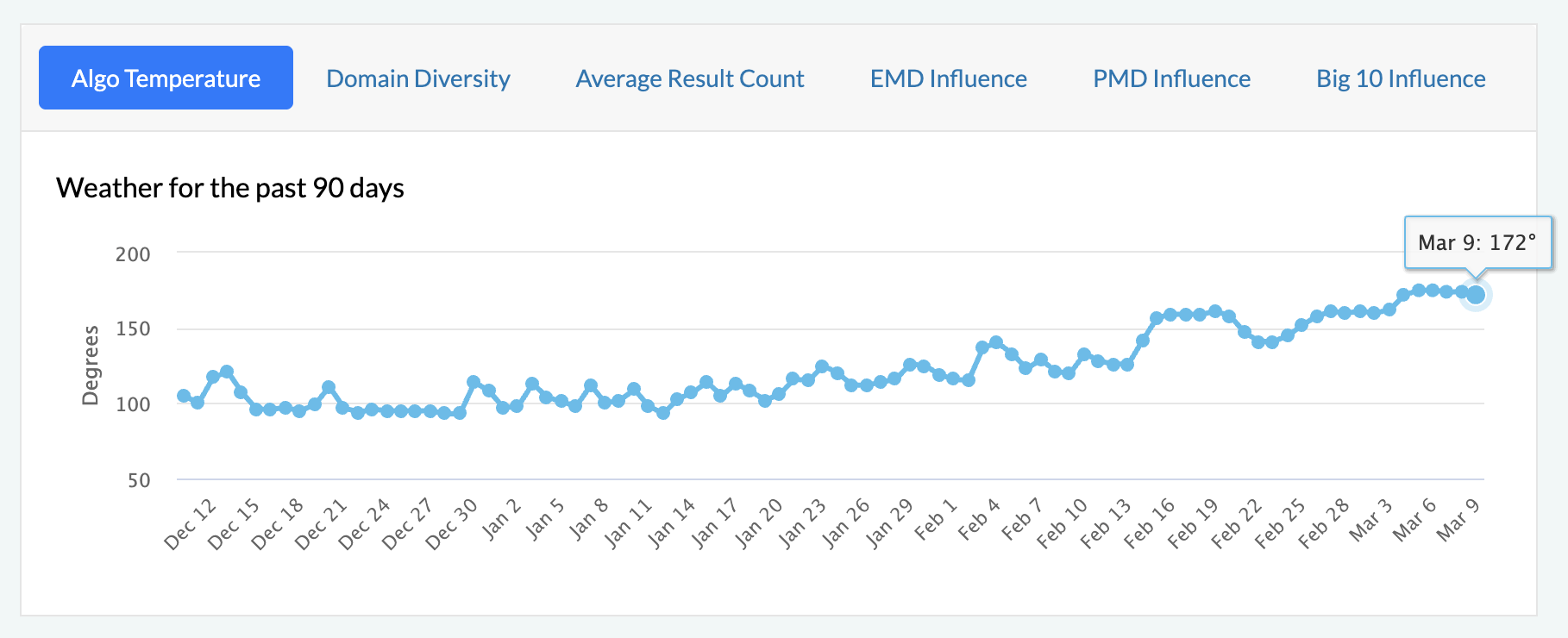
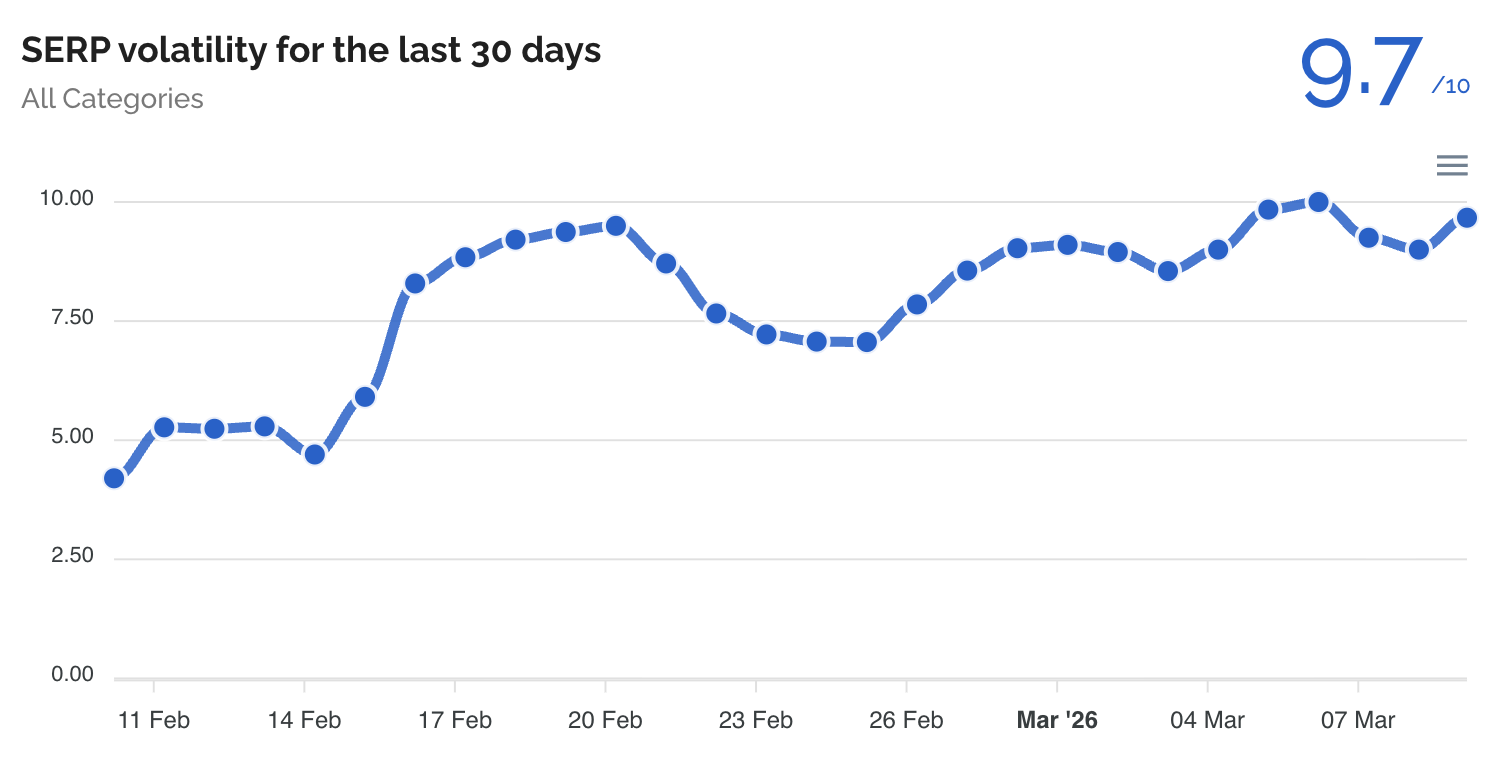
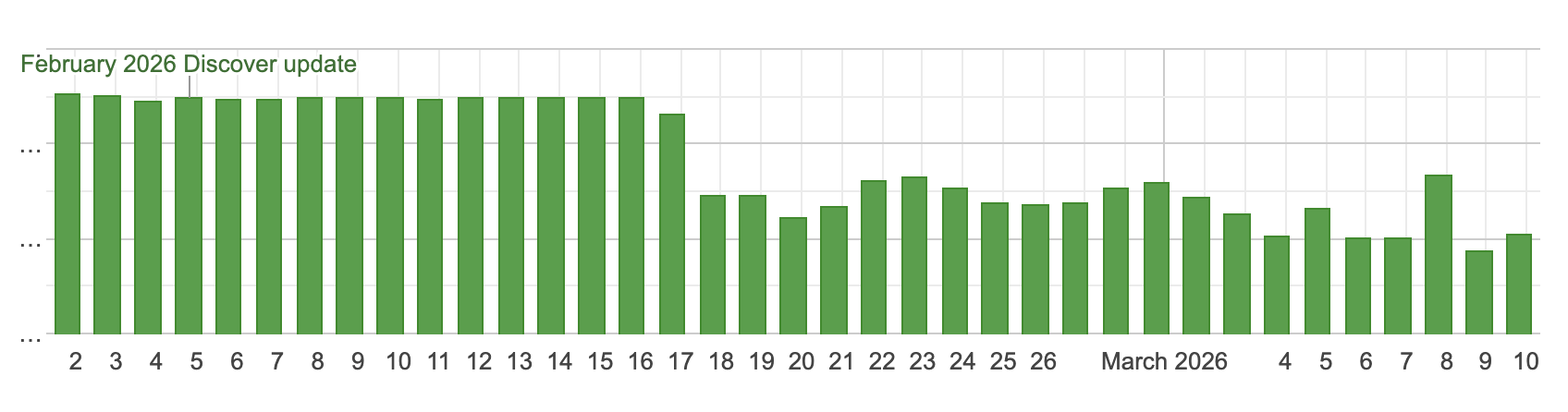
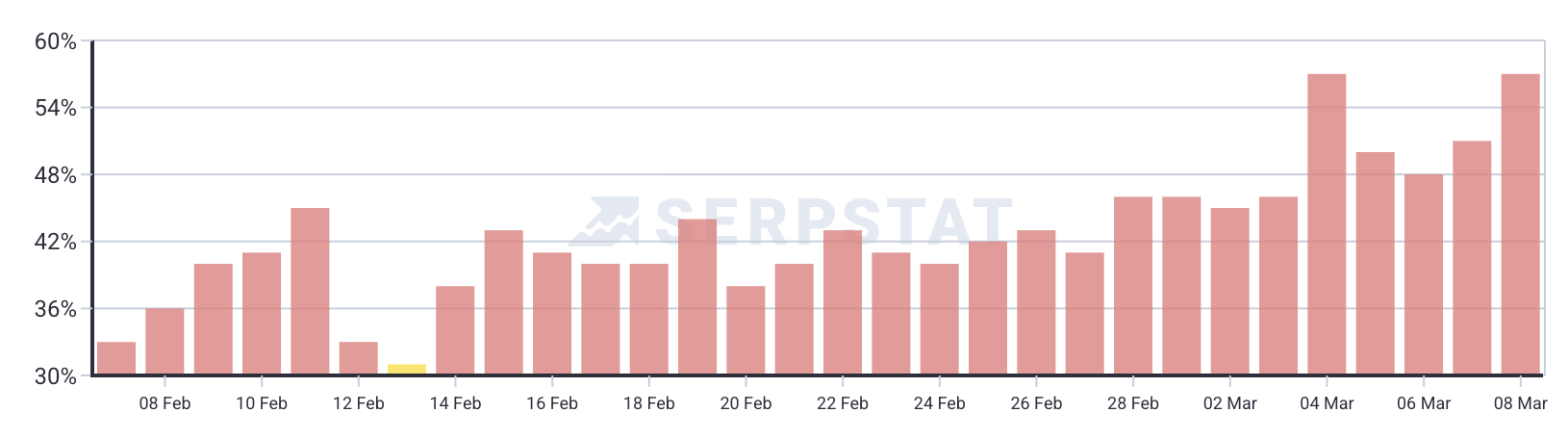
Просто небольшое уведомление, чтобы сообщить вам, что я не буду публиковать материалы в течение следующих нескольких дней. Я не уверен, сколько времени я буду отсутствовать, но я ожидаю, что пройдет не менее нескольких дней, прежде чем я вернусь к нормальной жизни.
Чтобы поддерживать активность, некоторые друзья время от времени публикуют новый контент. У меня также есть запас постов, которые были написаны заранее и теперь публикуются автоматически. Скорее всего, вы увидите смесь этих запланированных постов и новых материалов, появляющихся в разное время.
Если вы хотите уведомить этих друзей о новых находках, вы можете связаться с ними в социальных сетях по адресу:
Отправьте им сообщение в социальных сетях, и, надеюсь, они смогут осветить ваши новые открытия, пока я не в сети.
Обычно я не делаю перерывов в ведении блога или работе, поэтому отстраниться — это непросто. Я очень ценю последовательность и приверженность своим распорядкам дня с этим веб-сайтом, моей работой и моей семьей. Однако я ожидаю вернуться к нормальной жизни через несколько недель.
Если вы хотите сделать мне одолжение, пожалуйста, сохраняйте комментарии спокойными.
Спасибо за вашу поддержку.
Барри Шварц
Смотрите также
- Полное руководство по вариантам таргетинга рекламы PPC
- Акции PHOR. ФосАгро: прогноз акций.
- Акции NMTP. НМТП: прогноз акций.
- Google представляет собственное решение для обработки данных для пользователей аналитики
- Google: получайте определения и переводы при поиске
- Дифференциация: выделяйтесь, получайте клики
- Ошибка поиска Google: снова не индексируется и не отображается новый контент
- Акции VKCO. ВК: прогноз акций.
- Automattic сталкивается с иронией нового протестного сайта WPEngineTracker
- Анализ динамики цен на криптовалюту METH: прогнозы METH
2026-03-10 17:14