

Как человек, который уже более десяти лет бороздит коварные воды SEO, я не могу не чувствовать чувство оправдания, когда читаю об исследованиях, подобных этому. Это подтверждает мое давнее убеждение, что полагаться на один-единственный сигнал рейтинга или качества — это путь к катастрофе.
Купил акции на все деньги, а они упали? А Илон Маск снова написал твит? Знакомо. У нас тут клуб тех, кто пытается понять этот цирк и не сойти с ума.
Купить на падении (нет)Это менее общеизвестно, но специалистам по SEO следует ознакомиться с идеей сжимаемости как важного показателя. Это свойство позволяет поисковым системам более эффективно различать идентичные страницы, дорвеи со схожим содержанием и страницы, переполненные повторяющимися ключевыми словами. Таким образом, понимание сжимаемости может быть полезно для практики SEO.
Хотя это исследование эффективно демонстрирует, как элементы на странице могут быть использованы для выявления спама, секретный характер алгоритмов поисковых систем затрудняет окончательное подтверждение того, действительно ли они используют эти конкретные методы или связанные с ними методы.
Что такое сжимаемость?
С точки зрения информатики, сжимаемость — это уменьшение размера файла без потери важных деталей, что часто делается для оптимизации емкости хранилища или ускорения передачи данных через Интернет.
TL/DR сжатия
Вместо того, чтобы широко использовать повторяющиеся слова или фразы, сжатие сокращает их до более коротких форм, тем самым резко уменьшая общий размер файла. Веб-страницы, индексируемые поисковыми системами, часто сжимаются для различных целей, таких как увеличение емкости хранилища, минимизация передачи данных и повышение скорости поиска, среди прочего.
Это упрощенное объяснение того, как работает сжатие:
- Определить закономерности:
Алгоритм сжатия сканирует текст, чтобы найти повторяющиеся слова, шаблоны и фразы. - Более короткие коды занимают меньше места:
Коды и символы занимают меньше места для хранения, чем исходные слова и фразы, что приводит к меньшему размеру файла. - Более короткие ссылки используют меньше битов:
«Код», который по сути символизирует замененные слова и фразы, использует меньше данных, чем оригиналы.
Одним из преимуществ использования сжатия является его способность находить идентичные веб-страницы, дорвеи, содержащие аналогичную информацию, а также страницы, переполненные повторяющимися ключевыми словами.
Исследовательская статья об обнаружении спама
Важность этой исследовательской работы заключается в том, что она была написана выдающимися учеными-компьютерщиками, известными своими новаторскими достижениями в области искусственного интеллекта, распределенных вычислений, поиска данных и различных смежных областей.
Марк Найорк
Среди авторов исследовательской работы — Марк Найорк, известный учёный в этой области, который является заслуженным учёным-исследователем в Google DeepMind. Он является одним из авторов статей TW-BERT, проводил исследования по повышению точности использования неявной обратной связи с пользователем, такой как клики, и сыграл важную роль в разработке передовых систем искусственного интеллекта для поиска информации (DSI++: Обновление памяти трансформатора с помощью новых документов). . Среди его многочисленных значительных достижений в этой области это лишь некоторые из них.
Деннис Феттерли
Одного из других авторов зовут Деннис Феттерли, который в настоящее время работает инженером-программистом в Google. Примечательно, что он считается соавтором патента, касающегося алгоритма ранжирования, использующего ссылки. В сферу его компетенции входят исследования в области распределенных вычислений и поиска информации.
Два известных исследователя, входящие в число соавторов исследовательской работы Microsoft 2006 года по выявлению спама на основе характеристик контента на странице, также обнаружили, что сжимаемость – одна из нескольких особенностей контента, рассмотренных в исследовании – может служить эффективным классификатором для определения спама. если веб-страница содержит спам.
Обнаружение спам-веб-страниц с помощью анализа контента
Хотя исследование было написано в 2006 году, его выводы остаются актуальными и по сей день.
Тогда и сегодня многие люди пытались организовать множество веб-страниц, сосредоточенных вокруг мест, причем эти страницы по существу были дубликатами, за исключением различий в названиях городов, регионов или штатов. В обе эпохи специалисты по поисковой оптимизации (SEO) часто создавали такие веб-страницы в первую очередь для поисковых систем, злоупотребляя ключевыми словами в заголовках, метаописаниях, заголовках, тексте внутренних ссылок и самом контенте, чтобы повысить их рейтинг.
Как специалист по цифровому маркетингу, я часто замечал, что поисковые системы отдают предпочтение страницам, на которых ключевые слова моего запроса повторяются несколько раз. Например, страница, на которой термин используется десять раз, может иметь более высокий рейтинг, чем страница, на которой тот же термин упоминается только один раз. Чтобы воспользоваться этой функцией, некоторые сайты, рассылающие спам, многократно дублируют свой контент, стремясь подняться наверх в рейтинге.
Исследование показало, что поисковые системы сжимают веб-страницы для более быстрого доступа к ним, а большее количество повторяющихся слов приводит к более легкому сжатию. Он запрашивает, существует ли сильная связь между простым сжатием (высокая сжимаемость) и наличием спам-контента.
В этой части нашего метода мы выявляем ненужный контент на странице, уменьшая его. Этот процесс помогает экономить место для хранения и сокращает время, необходимое для поиска, поскольку поисковые системы обычно сжимают веб-страницы после индексации, но перед сохранением их в кеше.
….Мы рассчитываем избыточность веб-страниц, используя коэффициент сжатия, который представляет собой размер несжатой страницы, разделенный на размер сжатой страницы. Для достижения сжатия мы использовали эффективный и быстрый алгоритм GZIP.
Высокая сжимаемость коррелирует со спамом
Результаты нашего исследования показали, что веб-страницы со степенью сжатия 4,0 или выше часто оказываются некачественными или спам-сайтами. Тем не менее, по мере того, как мы переходили к более высоким уровням сжимаемости, результаты становились менее надежными из-за нехватки данных, что затрудняло получение точных выводов.
Рисунок 9. Распространенность спама в зависимости от сжимаемости страницы.
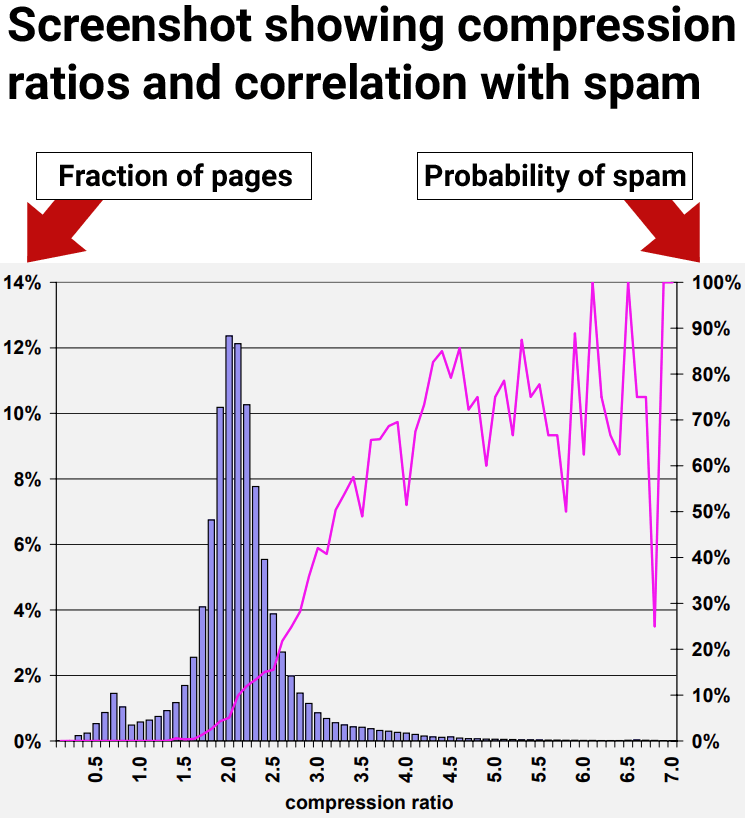
«70 % всех выбранных страниц со степенью сжатия не менее 4,0 были признаны спамом».
Однако даже когда они использовали только степень сжатия, это приводило к случаям, когда страницы, не являющиеся спамом, ошибочно классифицировались как спам.
В разделе 4.6 мы обнаружили, что метод коэффициента сжатия показал оптимальные результаты: он точно пометил 27,9 %, или 660, спам-страниц от общего числа, но неправильно классифицировал 12,0 %, или 2068 страниц, из всех оцененных.
После применения метода десятикратной перекрестной проверки с использованием всех ранее упомянутых характеристик точность классификации выглядит многообещающе.
95,4% оцененных нами страниц были классифицированы правильно, а 4,6% – неправильно.
Проще говоря, для категории, помеченной как спам (класс 1), около 940 из 2364 веб-страниц были точно идентифицированы как спам. В категории «не спам» (класс 0) примерно 14 440 из 14 804 веб-страниц были правильно идентифицированы. Это означает, что около 788 страниц были категоризированы неправильно.
В следующей части мы рассмотрим увлекательную находку, касающуюся методов повышения точности использования индикаторов на странице для обнаружения спама.
Взгляд на рейтинги качества
В ходе исследования были проанализированы различные элементы веб-страниц, такие как сжимаемость, и обнаружено, что каждый элемент может идентифицировать определенный спам-контент. Однако использование всего одного элемента привело к тому, что законные страницы были классифицированы как спам — явление, известное как «ложные срабатывания».
Исследователи сделали важное открытие, которое должен знать каждый, кто интересуется SEO: использование нескольких классификаторов повышает точность обнаружения спама и снижает вероятность ложных срабатываний. Не менее важно и то, что сигнал сжимаемости идентифицирует только один вид спама, но не весь спектр спама.
Проще говоря, кажется, что сжимаемость может помочь в распознавании определенных типов спама, но важно отметить, что не весь спам можно обнаружить, используя только этот метод. Другие формы спама могут избежать обнаружения с помощью сигнала сжимаемости.
В последней части мы рассказали о различных методах выявления спам-сайтов. Эти методы включали изучение характеристик веб-страниц и определение пороговых значений, связанных с тем, что страница является спамом. Однако, если применять их по отдельности, ни один из этих методов не сможет эффективно обнаружить большую часть спама в нашем наборе данных без ошибочной маркировки многих страниц, не являющихся спамом, как спама.
В соответствии со стратегией коэффициента сжатия, описанной в разделе 4.6, одна из наших лучших стратегий имеет среднюю вероятность спама 72 % для коэффициентов, равных или превышающих 4,2. Однако только около 1,5 % всех веб-страниц попадают в этот диапазон, что значительно ниже 13,8 % спам-страниц, которые мы обнаружили в нашем наборе данных.
Хотя сжимаемость оказалась сильным индикатором спама, она не смогла полностью выявить все случаи спама, скрытые в наборе данных, которые исследователи проанализировали в целях тестирования.
Объединение нескольких сигналов
Первоначальные результаты показали, что одиночные сигналы более низкого качества менее надежны. В результате они решили вместо этого изучить возможность использования нескольких сигналов. Они обнаружили, что объединение нескольких индикаторов на странице для выявления спама привело к более высокому уровню точности и меньшему количеству ложных срабатываний (страницы неправильно классифицируются как спам).
Как эксперт по SEO, я бы подошел к обнаружению спама по-другому, представив его как задачу классификации. Моя цель — разработать надежную модель классификации, которая сможет эффективно классифицировать веб-страницу на «спам» и «не-спам». Эта модель проанализирует уникальные характеристики страницы, чтобы принять обоснованное решение и помочь нам поддерживать качество наших данных.
Как опытный эксперт по SEO, я углубился в тонкости спама на основе веб-контента, используя подлинные данные сканера MSNSearch. Я предложил несколько эвристических стратегий для выявления контентного спама. Хотя некоторые из этих стратегий более эффективны, чем другие, важно отметить, что при индивидуальном использовании они могут не перехватывать каждую спам-страницу. Чтобы решить эту проблему, я синтезировал эти стратегии обнаружения спама и разработал высокоточный классификатор C4.5. Этот классификатор способен точно идентифицировать 86,2 % всех спам-страниц, сводя при этом к минимуму количество законных страниц, ошибочно помеченных как спам.
Ключевая идея:
Ошибочное определение «очень немногих законных страниц как спама» стало значительным прорывом. Важная мысль, которую должен вынести каждый, кто занимается SEO, заключается в том, что один сигнал сам по себе может привести к ложным срабатываниям. Использование нескольких сигналов повышает точность.
Проще говоря, проведение отдельных SEO-тестов по факторам ранжирования или элементам качества не даст заслуживающих доверия результатов, которые подходят для формирования стратегий или бизнес-решений.
Вынос
Хотя неясно, используют ли поисковые системы сжимаемость специально, это простой метод, который в сочетании с другими может помочь идентифицировать распространенные типы спама, такие как многочисленные дорвеи с названиями городов, заполненные похожим контентом. Даже если поисковые системы не используют этот сигнал, это демонстрирует легкость, с которой такие манипуляции поисковых систем могут быть обнаружены, и подчеркивает способность современных поисковых систем эффективно справляться с такими ситуациями.
Вот ключевые моменты этой статьи, о которых следует помнить:
- Дорвеи с дублирующимся контентом легко обнаружить, поскольку они сжимаются с большей степенью сжатия, чем обычные веб-страницы.
- Группы веб-страниц со степенью сжатия выше 4,0 представляли собой преимущественно спам.
- Сигналы отрицательного качества, используемые сами по себе для перехвата спама, могут привести к ложным срабатываниям.
- В ходе этого конкретного теста они обнаружили, что сигналы отрицательного качества на странице улавливают только определенные типы спама.
- При использовании отдельно сигнал сжимаемости улавливает только спам избыточного типа, не обнаруживает другие формы спама и приводит к ложным срабатываниям.
- Объединение сигналов качества повышает точность обнаружения спама и снижает количество ложных срабатываний.
- Сегодня поисковые системы имеют более высокую точность обнаружения спама благодаря использованию искусственного интеллекта, такого как Spam Brain.
Прочтите исследовательскую работу, ссылка на которую находится на странице Google Scholar Марка Найорка:
Обнаружение спам-веб-страниц посредством анализа контента
Смотрите также
- Акции CBOM. МКБ: прогноз акций.
- Часть 1. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Акции SGZH. Сегежа: прогноз акций.
- Контролируя Вашу Розничную Позицию Онлайн С помощью SEO
- Часть 2. Как шаг за шагом запустить, управлять и развивать партнерскую программу
- Google может меньше полагаться на Hreflang и перейти на автоматическое определение языка
- Интеграция Google Lens для YouTube Shorts: Поиск внутри видео.
- Акции привилегированные KZOSP. Казаньоргсинтез: прогноз акций привилегированных.
- Акции привилегированные SBERP. Сбербанк: прогноз акций привилегированных.
- Google запускает генерацию видео в Product Studio
2024-10-27 21:09