Google оспаривает недавнее решение о том, что компания обладает монополией в сфере поиска, и представила новые документы в суд в рамках своей апелляции. Эти документы включают заявления под присягой от двух руководителей Google: Элизабет Рид, вице-президента и главы поиска, и Джесси Адкинса, директора по управлению продуктами для поиска и синдикации рекламы.
В письменном заявлении под присягой (Affidavit), идентифицированном как Документ №1471, Приложение №2, Элизабет Рейд объясняет возражения Google против определенных предложенных решений суда.
Google возражает против двух пунктов соглашения: требования делиться данными и требования распространять результаты поиска другим компаниям. Согласно внутренним документам, Google опасается, что раскрытие этой конфиденциальной информации немедленно и серьезно повредит его конкурентным позициям, а также может нанести ущерб его финансам и репутации, если данные будут утечены или скомпрометированы.
Детали, которые Google должна будет предоставить конкурентам, включают:
- уникальный идентификатор (‘DocID’) каждого документа (т.е. URL) в Индексе веб-поиска Google и информация, достаточная для выявления дубликатов;
- ‘отображение DocID на URL’; и
- ‘для каждого Doc ID, (A) время первого обнаружения URL, (B) время последней скачки URL, (C) оценка спама и (D) флаг типа устройства.’
Google считает, что передача этого приведет к:
Предоставляя конкурентам несправедливое преимущество, поскольку Google десятилетиями разрабатывал эти техники.
(2) Это выдало бы, какие URL-адреса Google считает более важными, чем другие.
(3) Это позволило бы спамерам реконструировать некоторые из его алгоритмов.
(4) Это сделает личную информацию ищущих доступной для своих конкурентов.
Google wrote:
Во-первых, технология сканирования Google обрабатывает веб-страницы в открытом интернете, полагаясь на собственные сигналы качества и свежести страниц, чтобы сосредоточиться на веб-страницах, которые, скорее всего, будут отвечать информационным потребностям пользователей. Во-вторых, Google помечает просканированные веб-страницы собственными аннотациями для понимания страниц, включая сигналы для выявления спама и дублирующихся страниц. Наконец, Google строит индекс, используя помеченные веб-страницы, сгенерированные на этапе аннотирования. Индекс Google использует собственную многоуровневую структуру, которая организует веб-страницы на основе того, как часто Google ожидает, что к контенту потребуется доступ, и насколько свежим должен быть контент (чем свежее должен быть контент, тем чаще Google должен сканировать веб-страницу).
Диаграмма ниже (RDXD-28.005) иллюстрирует пропорцию страниц, которые Google индексирует (отображено зелёным цветом), по сравнению с общим количеством страниц, которые Google сканирует (отображено красным цветом). Как того требует юридическое соглашение, Google должен делиться этим ограниченным набором проиндексированных страниц (зелёная часть) с утвержденными конкурентами.
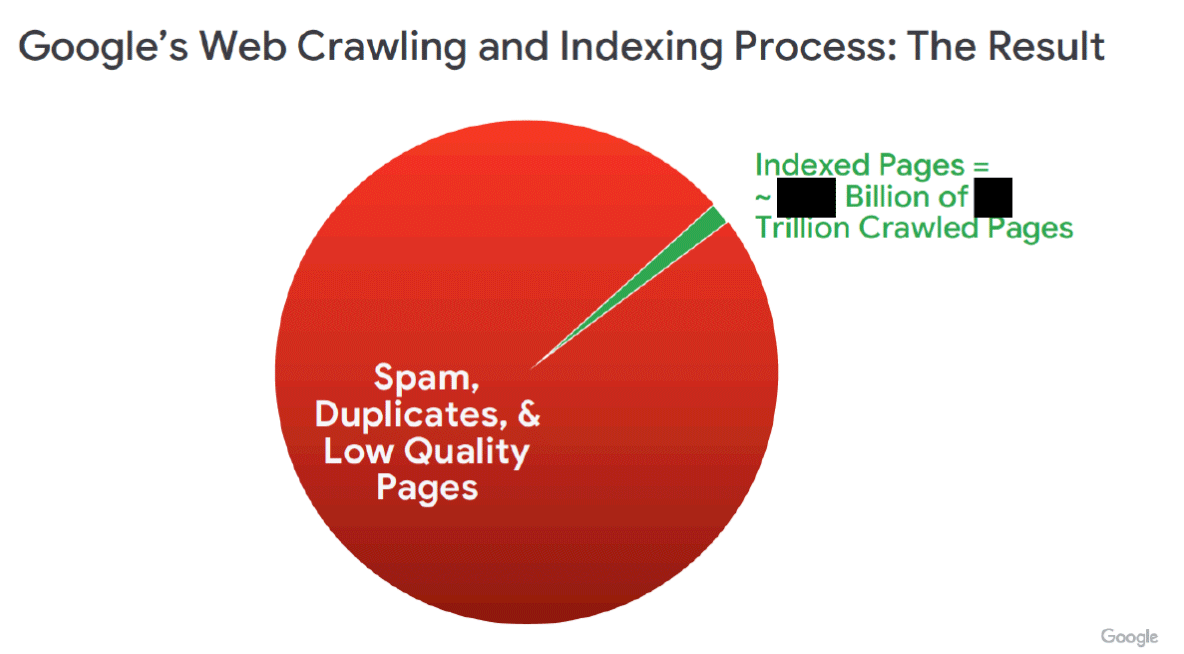
Это указывает на количество URL-адресов, проиндексированных Google – удивительно большое число! Это действительно подчеркивает, насколько большую часть веб-сайтов Google знает.
Google added:
Если спамеры или другие злоумышленники получат доступ к оценкам спама от Qualified Competitors из Google посредством утечек данных или взломов – реалистичный исход, учитывая огромную ценность этих данных – качество поиска Google будет ухудшено, а его пользователи будут подвергаться воздействию возросшего количества спама, что ослабит репутацию Google как надежной поисковой системы.
Если бы конкретные сигналы, которые Google использует для выявления спама на веб-страницах, были публично раскрыты – например, в результате утечки данных – это значительно ухудшило бы качество поиска Google и сильно затруднило бы фильтрацию нежелательного спама. Как я объяснял в предыдущих показаниях, в интернете содержится много спама, и Google разработал сложные системы для борьбы с ним. Эти системы полагаются на сохранение в секрете деталей их работы, потому что если бы спамеры знали, какие сигналы использует Google, они могли бы легко обойти их.
Если бы спамеры могли видеть внутренние оценки спама от Google, они могли бы обмануть систему и избежать обнаружения. Они часто захватывают реальные веб-сайты и заполняют их нежелательным контентом, а знание того, какие страницы Google считает безопасными, значительно бы упростило это. Это, вероятно, привело бы к большему количеству спама и ненадежной информации, появляющейся в результатах поиска, подвергая пользователей риску и нанося ущерб репутации Google как надежного источника.
Затем он переходит к GLUE и RankEmbed:
Данные, полученные от пользователей, используемые для создания, разработки или эксплуатации статистических моделей GLUE, и (ii) Данные, полученные от пользователей, используемые для обучения, разработки или эксплуатации моделей RankEmbed, по предельной стоимости.
Данные пользователей, охватываемые разделом IV.B Окончательного решения, очень конфиденциальны и включают в себя такие вещи, как поисковые запросы, местоположение, время поиска и то, как пользователи взаимодействуют с результатами поиска – например, на что они наводят курсор или на что кликают.
Модель ‘Glue’ от Google построена на основе всесторонней записи истории поиска, включая все веб-результаты и функции поиска, которые отображаются, а также порядок, в котором они появляются. Эти данные собираются за последние тринадцать месяцев истории поиска.
Вы также можете найти письменное заявление под присягой Джесси Адкинса – это Документ №1471, Приложение №3, и он связан с рекламными материалами.
Смотрите также
2026-01-21 15:15